
用于存储键值对数据的HashEntry,在设计上它的成员变量value等都是volatile类型的,这样就保证别的线程对value值的修改,get方法可以马上看到。
static final class HashEntry<K,V> { final int hash; final K key; volatile V value; volatile HashEntry<K,V> next; }1.4 Put方法
1、首先定位segment,当这个segment在map初始化后,还为null,由ensureSegment方法负责填充这个segment。
2、对Segment加锁,虽然value是volatile的,只能保证可见性,不能保证原子性。这里put操作不是原子操作,因此需要加锁。

3、定位所在的table元素,并扫描table下的链表,找到时:

注意到默认onlyIfAbsent为false,也就是如果有相同key的元素,会覆盖旧的值。无论是否覆盖,都是返回旧值。
没有找到时:

1.5 扩容操作
扩容操作不会扩容Segment,只会扩容对应的table数组,每次都是将数组翻倍。

之前也提到过,由于数组长度为2次幂,所以每次扩容之后,元素要么在原处,要么在原处加上偏移量为旧的size的新位置。
1.6 Size方法
size的时候进行两次不加锁的统计,两次一致直接返回结果,不一致,重新加锁再次统计,

ConcurrentHashMap的弱一致性
get方法和containsKey方法都是通过对链表遍历判断是否存在key相同的节点以及获得该节点的value。但由于遍历过程中其他线程可能对链表结构做了调整,因此get和containsKey返回的可能是过时的数据,这一点是ConcurrentHashMap在弱一致性上的体现。
JDK1.8中的实现相比JDK1.7的重要变化:
1、取消了segment数组,引入了Node结构,直接用Node数组来保存数据,锁的粒度更小,减少并发冲突的概率。
2、存储数据时采用了链表+红黑树的形式,纯链表的形式时间复杂度为O(n),红黑树则为O(logn),性能提升很大。什么时候链表转红黑树?当key值相等的元素形成的链表中元素个数超过8个的时候。
2.1 数据结构
Node:存放实际的key和value值。
sizeCtl:负数:表示进行初始化或者扩容,-1表示正在初始化,-N,表示有N-1个线程正在进行扩容
正数:0 表示还没有被初始化,>0的数,初始化或者是下一次进行扩容的阈值。
TreeNode:用在红黑树,表示树的节点, TreeBin是实际放在table数组中的,代表了这个红黑树的根。
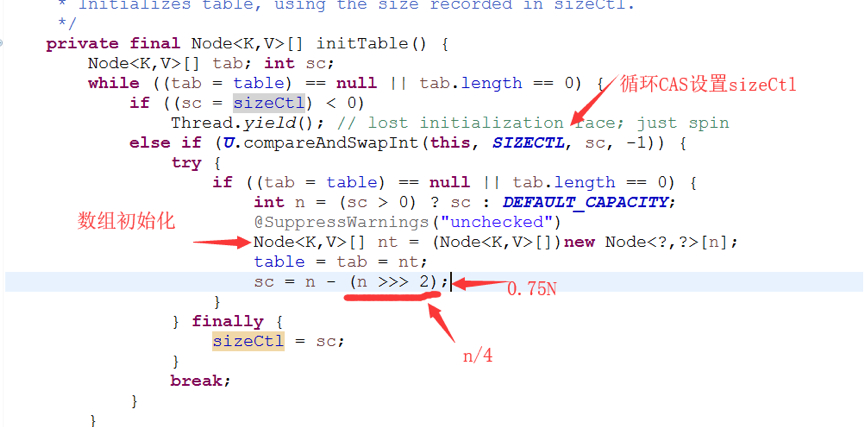
ConcurrentHashMap在初始化时,只是给成员变量赋值,put时进行实际数组的填充。
2.2 Hash计算
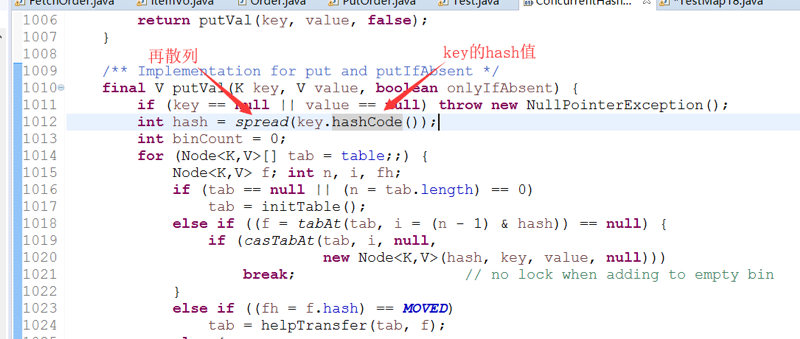
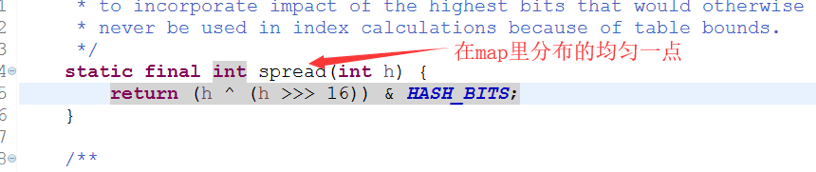
先计算key的hash值,然后将高位加入计算来进行再散列。
2.3 Get方法
首先计算hash值,确定在table中的位置。
是否刚好在table中某个首元素,找到返回;
在树中查找
在链表中查找

注意到在初始化TreeBin,也就是设置红黑树所在的Node的第一个节点时,会设置对应的hash值,这些hash值定义如下。所以上面的代码中,可以通过判断首节点的hash值<0来确定该节点为树。
static final int MOVED = -1; // hash for forwarding nodes static final int TREEBIN = -2; // hash for roots of trees static final int RESERVED = -3; // hash for transient reservations2.4 Put方法
PUT方法中会实际初始化数组,