
另外,观察XGBoost的最优特征准则:
\[
Gain=\frac{G_L^2}{H_L^2+\lambda}+\frac{G_R^2}{H_R^2+\lambda}-\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}-\gamma
\]
其中,等式右侧前半部分表示训练loss的减少,\(\gamma\)为正则化。上式有可能是负的,也就是说,loss的减少比正则化力度还要小时,分裂的增益会是负的。因此类似于预剪枝和后剪枝,有两种训练策略:
提前停止:如果最佳分裂点是负的,那么提前停止分裂。这是这种策略过于贪婪,该分裂有可能有益于后面的分裂。
后剪枝:将一棵树生成到它的最大深度,递归剪枝,剪去叶子节点分裂是负增益的。
XGBoost的其它特性:
行抽样
列抽样
缩减学习率
支持自定义损失函数,当然,该损失函数需要二阶可导
增加了对稀疏数据的支持,在计算分裂增益时,只利用没有missing值的样本
支持并行化,在分裂节点计算增益时,并行
XGBoost论文地址:XGBoost: A Scalable Tree Boosting System
XGBoost官网:XGBoost Documentation
LightGBM
与XGBoost的不同:
直方图算法
把连续的浮点特征值离散化为k个整数,同时构造一个宽度为k的直方图。在遍历数据时,根据离散化后的值作为索引,在直方图中计算统计量。当遍历一次数据后,直方图计算了需要的统计量,然后根据直方图的离散值,遍历寻找最优分割点。
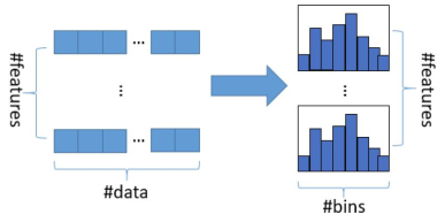
优势:减少了内存占用;减少了分裂点计算增益时的计算量
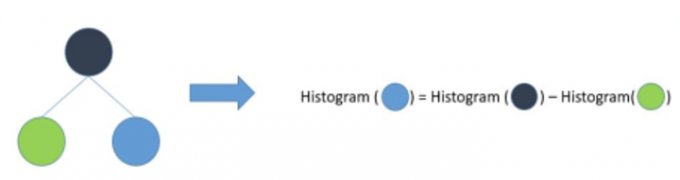
直方图加速
一个叶子的直方图可以由它的父节点的直方图与它的兄弟节点的直方图,做差而得,提升一倍速度。
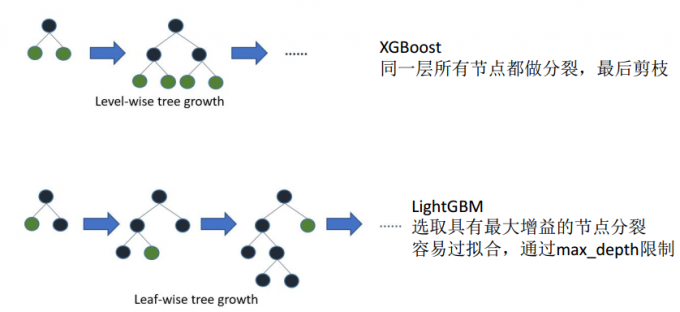
建树方法
XGBoost是Level-wise,LightGBM是Leaf-wise
总而言之,LightGBM特性:
基于Histogram的决策树算法
直方图差加速
带深度限制的Leaf-wise的叶子生长策略
直接支持类别特征(Categorical Feature)
Cache命中率优化
基于直方图的稀疏特征优化
多线程优化
LightGBM论文地址:Lightgbm: A highly efficient gradient boosting decision tree
LightGBM官网:LightGBM Documentation