
上面这个例子是字符级别 (character-level) 的语言模型,每个句子都以单个字符为单位,这个例子中我们以词组为单位进行训练,所以首先要用 jieba 分词将句子分成词组。
用词嵌入 (word embedding) 代替one-hot编码,节省内存空间,同时词嵌入可能比 one-hot 更好地表达语义。
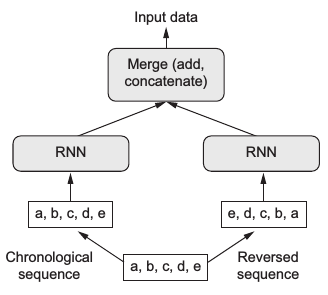
用双向GRU (birdectional GRU) 代替LSTM,双向模型同时利用了正向序列和反向序列的信息,再将二者结合起来,如下图所示:
训练的语料选择了推理作家东野圭吾的名作《白夜行》。
import jieba whole = open('白夜行.txt', encoding='utf-8').read() all_words = list(jieba.cut(whole, cut_all=False)) # jieba分词 words = sorted(list(set(all_words))) word_indices = dict((word, words.index(word)) for word in words) maxlen = 30 sentences = [] next_word = [] for i in range(0, len(all_words) - maxlen): sentences.append(all_words[i: i + maxlen]) next_word.append(all_words[i + maxlen]) print('提取的句子总数:', len(sentences)) x = np.zeros((len(sentences), maxlen), dtype='float32') # Embedding的输入是2维张量(句子数,序列长度) y = np.zeros((len(sentences)), dtype='float32') for i, sentence in enumerate(sentences): for t, word in enumerate(sentence): x[i, t] = word_indices[word] y[i] = word_indices[next_word[i]]查看数据的大小:
print(np.round((sys.getsizeof(x) / 1024 / 1024 / 1024), 2), "GB") print(x.shape, y.shape) 0.03 GB (235805, 30) (235805,)23万行数据 0.03 GB,比 one-hot 编码小多了。
接下来搭建神经网络,中间用两层双向 GRU,后接全连接层用softmax输出所有词组的概率:
main_input = layers.Input(shape=(maxlen, ), dtype='float32') model_1 = layers.Embedding(len(words), 128, input_length=maxlen)(main_input) model_1 = layers.Bidirectional(layers.GRU(256, return_sequences=True))(model_1) model_1 = layers.Bidirectional(layers.GRU(128))(model_1) output = layers.Dense(len(words), activation='softmax')(model_1) model = keras.models.Model(main_input, output) optimizer = keras.optimizers.RMSprop(lr=3e-3) model.compile(loss='sparse_categorical_crossentropy', optimizer=optimizer) model.fit(x, y, epochs=100, batch_size=1024, verbose=2)定义文本生成函数:
def write_2(model, temperature, word_num): gg = begin_sentence[:30] print(''.join(gg), end='/// ') for _ in range(word_num): sampled = np.zeros((1, maxlen)) for t, char in enumerate(gg): sampled[0, t] = word_indices[char] preds = model.predict(sampled, verbose=0)[0] if temperature is None: next_word = words[np.argmax(preds)] else: next_index = sample(preds, temperature) next_word = words[next_index] gg.append(next_word) gg = gg[1:] sys.stdout.write(next_word) sys.stdout.flush()初始文本是:
begin_sentence = whole[50003: 50100] print(begin_sentence[:30]) begin_sentence = list(jieba.cut(begin_sentence, cut_all=False)) # 且不全力挥杆,先练习击球。 # 最初还有些生涩,但感觉慢慢回来了。打完二十球左右不使用 temperature 生成:
write_2(model, None, 300, begin_sentence)且不全力挥杆,先练习击球。
最初还有些生涩,但感觉慢慢回来了。打完二十球左右/// ,他便能重新前往那个方向。
然而,这样的可能性又能让她们之间的内容,这是一种感觉资料的。而当他的身世,也难怪他们找不到最主要的机会。
亮司离开了酒店,但这些对他说:“请问你要去找我了?”
“嗯。”她点头,脸上的表情让她更加扭曲。“我这时顶多,又怎么说,虽然要不管我,都会堂兄调查,才会很开心。”
“可是,你却不能必要。而且他经常怀疑你,就叫你提过。”
“可是,我不认识他的身体了。”
“没有,我不想到这里的意思了。”
“嗯,那我把谢谢你的名字。”
“嗯,”江利子用力点头,“那天你才开门。”
“真奇怪,我不会以为你有什么打算?”
“嗯。”听筒里露出这么沉重的笑容,他嘴角。“呃,那时候已经没什么好了。”
“不用了,我不等他,我就跟你说一声。”
“既然这样,我
temperature = 0.5 生成:
write_2(model, 0.5, 300, begin_sentence)且不全力挥杆,先练习击球。
最初还有些生涩,但感觉慢慢回来了。打完二十球左右/// ,他便能重新发现尸体的同时,他也详细又暗,“只说,你在电话里一定有很多电话了吧?”
“嗯。”友彦点头。
“请问……她说了在一起吗?”
“嗯。”
“这样啊。”
“哦。”她又对他说了好的,“我是在想,她似乎在别认识笹垣先生。”
她的问题在意味不得而知。他一脸不安地听着你的话,大概就是这样。”
“嗯……”
“嗯。”
“还有一件事。”雪穗。
“我想,既然有这种感觉,我就会认为我没问题。”
“哦。”雪穗露出苦笑,“不过,我很听她,有一次差不多过了锁的地方,不能透露多少次。”
“哦。”
“心里跳舞?哦,这是她的职业!一成先生,你对唐泽雪穗小姐的直觉。”
“是啊。”绘里回答,“那是个……”
“嗯……我想,
其中出现了一些奇怪的句子:
可是,我不认识他的身体了。
心里跳舞?哦,这是她的职业!