
AI写诗?? AI创作小说?? 近年来人们时常听到这类新闻,听上去很不可思议,那么今天我们来一探究竟,这种功能是如何通过深度学习来实现的。
通常文本生成的基本策略是借助语言模型,这是一种基于概率的模型,可根据输入数据预测下一个最有可能出现的词,而文本作为一种序列数据 (sequence data),词与词之间存在上下文关系,所以使用循环神经网络 (RNN) 基本上是标配,这样的模型被称为神经语言模型 (neural language model)。在训练完一个语言模型后,可以输入一段初始文本,让模型生成一个词,把这个词加入到输入文本中,再预测下一个词。这样不断循环就可以生成任意长度的文本了,如下图给定一个句子 ”The cat sat on the m“ 可生成下一个字母 ”a“ :
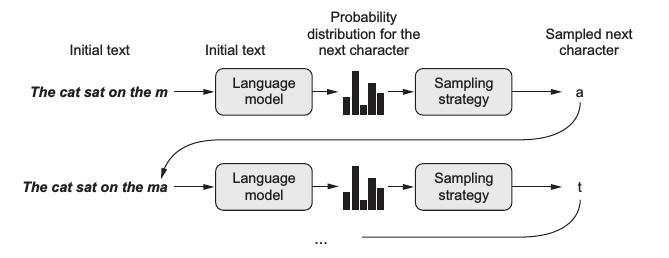
上图中语言模型 (language model) 的预测输出其实是字典中所有词的概率分布,而通常会选择生成其中概率最大的那个词。不过图中出现了一个采样策略 (sampling strategy),这意味着有时候我们可能并不想总是生成概率最大的那个词。设想一个人的行为如果总是严格遵守规律缺乏变化,容易让人觉得乏味;同样一个语言模型若总是按概率最大的生成词,那么就容易变成 XX讲话稿了。
因此在生成词的过程中引入了采样策略,在最后从概率分布中选择词的过程中引入一定的随机性,这样一些本来不大可能组合在一起的词可能也会被生成,进而生成的文本有时候会变得有趣甚至富有创造性。采样的关键是引入一个temperature参数,用于控制随机性。假设 \(p(x)\) 为模型输出的原始分布,则加入 temperature 后的新分布为:
\[
p(x_{new}) = \frac{e^{\,{log(p(x_i))}\,/\,{temperature}}}{\sum\limits_i e^{\,{log(p(x_i))}\,/\,{temperature}}} \tag{1.1}
\]
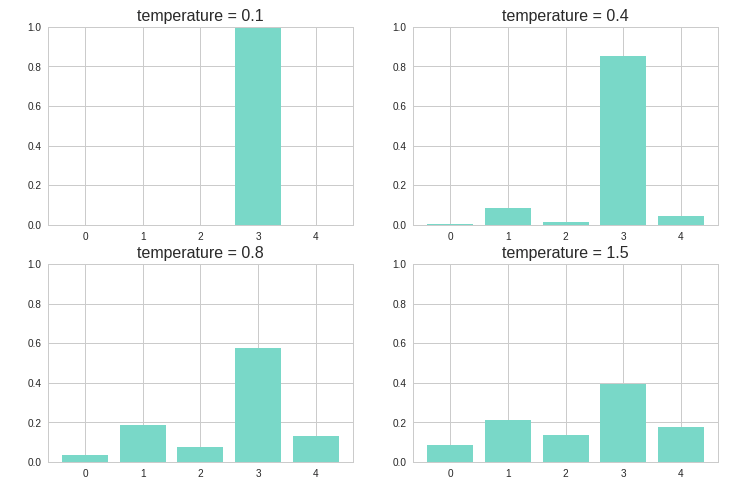
下图展示了不同的 temperature 分别得到的概率分布。temperature 越大,则新的概率分布越均匀,随机性也就越大,越容易生成一些意想不到的词。
本文将试验3种神经网络模型,用的库是Keras:
One-hot encoding + LSTM
Embedding + 双向GRU
Embedding + GRU + Conv1D + 反向Conv1D
这里训练的语料选择了老舍的遗作《正红旗下》。
首先读取文件,将文本向量化,以每个字为单位分词,最后采用one-hot编码为3维张量。
whole = open('正红旗下.txt', encoding='utf-8').read() maxlen = 30 # 序列长度 sentences = [] # 存储提取的句子 next_chars = [] # 存储每个句子的下一个字符(即预测目标) for i in range(0, len(whole) - maxlen): sentences.append(whole[i: i + maxlen]) next_chars.append(whole[i + maxlen]) print('提取的句子总数:', len(sentences)) chars = sorted(list(set(whole))) # 语料中所有不重复的字符,即字典 char_indices = dict((char, chars.index(char)) for char in chars) x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool) # 3维张量(句子数,序列长度,字典长度) y = np.zeros((len(sentences), len(chars)), dtype=np.bool) # 2维张量 (句子数,字典长度) for i, sentence in enumerate(sentences): for t, char in enumerate(sentence): x[i, t, char_indices[char]] = 1.0 y[i, char_indices[next_chars[i]]] = 1.0先查看下数据的大小:
print(np.round((sys.getsizeof(x) / 1024 / 1024 / 1024), 2), "GB") print(x.shape, y.shape) # 6.11 GB # (80095, 30, 2667) (80095, 2667)仅仅8万行数据就有 6GB 大小,这是由于使用 one-hot 编码普遍存在的高维稀疏问题。
接下来搭建神经网络,中间仅用一层LSTM,后接全连接层用softmax输出字典中所有字符的概率:
model = keras.models.Sequential() model.add(layers.LSTM(256, input_shape=(maxlen, len(chars)))) model.add(layers.Dense(len(chars), activation='softmax')) optimizer = keras.optimizers.RMSprop(lr=1e-3) model.compile(loss='categorical_crossentropy', optimizer=optimizer) model.fit(x, y, epochs=100, batch_size=1024, verbose=2)训练了100个epoch后,可以开始生成文本了,主要有以下几个步骤:
将已生成的文本以同样的方式 one-hot 编码,用训练好的模型得出所有字符的概率分布。
根据给定的 temperature 得到新的概率分布。
从新的概率分布中抽样得到下一个字符。
将生成的新字符加到最后,并去掉原文本的第一个字符。