卷积神经网络一般多用于图像领域,主要由于其独特的局部特征提取功能。但人们发现一维卷积神经网络 (Conv1D) 同样适合序列数据的处理,因为其可以提取长序列中的局部信息,这在特定的 NLP 领域 (如机器翻译,自动问答等) 中非常有用。另外值得一提的是相比于用 RNN 处理序列数据,Conv1D的训练要快得多。
受上个例子中双向模型的启发,这里我也同时使用了正向和反向序列的信息,最后的模型大致是这样:
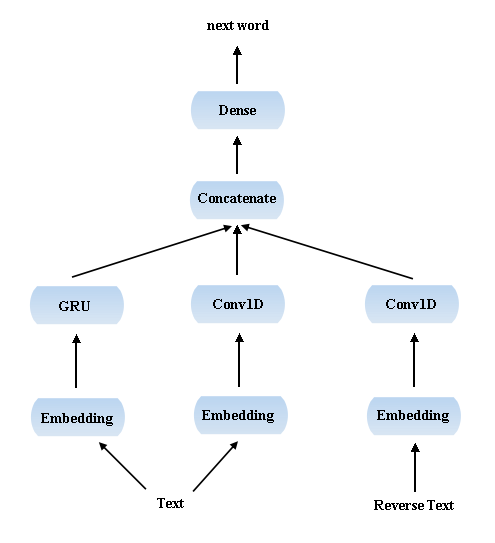
这次的训练语料是《西游记》。
whole = open('西游记.txt', encoding='utf-8').read()
maxlen = 30 # 正向序列长度
revlen = 20 # 反向序列长度
sentences = []
reverse_sentences = []
next_chars = []
for i in range(maxlen, len(whole) - revlen):
sentences.append(whole[i - maxlen : i])
reverse_sentences.append(whole[i + 1 : i + revlen + 1][::-1])
next_chars.append(whole[i])
print('提取的正向句子总数:', len(sentences))
print('提取的反向句子总数:', len(reverse_sentences))
chars = sorted(list(set(whole)))
char_indices = dict((char, chars.index(char)) for char in chars)
x = np.zeros((len(sentences), maxlen), dtype='float32')
reverse_x = np.zeros((len(reverse_sentences), revlen), dtype='float32')
y = np.zeros((len(sentences),), dtype='float32')
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
x[i, t] = char_indices[char]
y[i] = char_indices[next_chars[i]]
for i, reverse_sentence in enumerate(reverse_sentences):
for t, char in enumerate(reverse_sentence):
reverse_x[i, t] = char_indices[char]
建立神经网络模型:
normal_input = layers.Input(shape=(maxlen,), dtype='float32',)
model_1 = layers.Embedding(len(chars), 128, input_length=maxlen)(normal_input)
model_1 = layers.GRU(256, return_sequences=True)(model_1)
model_1 = layers.GRU(128)(model_1)
reverse_input = layers.Input(shape=(revlen,), dtype='float32',)
model_2 = layers.Embedding(len(chars,), 128, input_length=revlen)(reverse_input)
model_2 = layers.Conv1D(64, 5, activation='relu')(model_2)
model_2 = layers.MaxPooling1D(2)(model_2)
model_2 = layers.Conv1D(32, 3, activation='relu')(model_2)
model_2 = layers.GlobalMaxPooling1D()(model_2)
normal_input_2 = layers.Input(shape=(maxlen,), dtype='float32',)
model_3 = layers.Embedding(len(chars), 128, input_length=maxlen)(normal_input_2)
model_3 = layers.Conv1D(64, 7, activation='relu')(model_3)
model_3 = layers.MaxPooling1D(2)(model_3)
model_3 = layers.Conv1D(32, 5, activation='relu')(model_3)
model_3 = layers.GlobalMaxPooling1D()(model_3)
combine = layers.concatenate([model_1, model_2, model_3], axis=-1)
output = layers.Dense(len(chars), activation='softmax')(combine)
model = keras.models.Model([normal_input, reverse_input, normal_input_2], output)
optimizer = keras.optimizers.RMSprop(lr=1e-3)
model.compile(loss='sparse_categorical_crossentropy', optimizer=optimizer)
model.fit({'normal': x, 'reverse': reverse_x, 'normal_2': x}, y, epochs=200, batch_size=1024, verbose=2)
在预测的过程中需要不断在 list 的尾部删除元素,在头部插入元素,因而使用 collections 模块中的 deque 代替 list 进行高效操作:
from collections import deque
def write_3(model, temperature, word_num):
gg = begin_sentence[:30]
reverse_gg = deque(begin_sentence[31:51][::-1])
print(gg, end='/// ')
for _ in range(word_num):
sampled = np.zeros((1, maxlen))
reverse_sampled = np.zeros((1, revlen))
for t, char in enumerate(gg):
sampled[0, t] = char_indices[char]
for t, reverse_char in enumerate(reverse_gg):
reverse_sampled[0, t] = char_indices[reverse_char]
preds = model.predict({'normal': sampled, 'reverse': reverse_sampled, 'normal_2': sampled}, verbose=0)[0]
if temperature is None:
next_word = chars[np.argmax(preds)]
else:
next_index = sample(preds, temperature)
next_word = chars[next_index]
reverse_gg.pop()
reverse_gg.appendleft(gg[0])
gg += next_word
gg = gg[1:]
sys.stdout.write(next_word)
sys.stdout.flush()
初始文本是:
begin_sentence = whole[70000: 70100]
print(begin_sentence[:30] + " //" + begin_sentence[30] + "// " + begin_sentence[31:51])
# ,命掌生死簿判官:“急取簿子来,看陛下阳寿天禄该有几何?”崔 //判// 官急转司房,将天下万国国王天禄总簿,先逐
不使用 temperature 生成:
write_3(model, None, 500, begin_sentence)
