
摘要:Ray的定位是分布式应用框架,主要目标是使能分布式应用的开发和运行。
Ray是UC Berkeley大学 RISE lab(前AMP lab) 2017年12月 开源的新一代分布式应用框架(刚发布的时候定位是高性能分布式计算框架,20年中修改定位为分布式应用框架),通过一套引擎解决复杂场景问题,通过动态计算及状态共享提高效率,实现研发、运行时、容灾一体化
Ray架构解析 业务目标Ray的定位是分布式应用框架,主要目标是使能分布式应用的开发和运行。
业务场景具体的粗粒度使用场景包括
弹性负载,比如Serverless Computing
机器学习训练,Ray Tune, RLlib, RaySGD提供的训练能力
在线服务, 例如Ray Server提供在线学习的案例
数据处理, 例如Modin, Dask-On-Ray, MARS-on-Ray
临时计算(例如,并行化Python应用程序,将不同的分布式框架粘合在一起)
Ray的API让开发者可以轻松的在单个分布式应用中组合多个libraries,例如,Ray的tasks和Actors可能会call into 或called from在Ray上运行的分布式训练(e.g. torch.distributed)或者在线服务负载; 在这种场景下,Ray是作为一个“分布式胶水”系统,因为它提供通用API接口并且性能足以支撑许多不同工作负载类型。
Ray架构设计的核心原则是API的简单性和通用性
Ray的系统的核心目标是性能(低开销和水平可伸缩性)和可靠性。为了达成核心目标,设计过程中需要牺牲一些其他理想的目标,例如简化的系统架构。例如,Ray使用了分布式参考计数和分布式内存之类的组件,这些组件增加了体系结构的复杂性,但是对于性能和可靠性而言却是必需的。
为了提高性能,Ray建立在gRPC之上,并且在许多情况下可以达到或超过gRPC的原始性能。与单独使用gRPC相比,Ray使应用程序更容易利用并行和分布式执行以及分布式内存共享(通过共享内存对象存储)。
为了提高可靠性,Ray的内部协议旨在确保发生故障时的正确性,同时又减少了常见情况的开销。 Ray实施了分布式参考计数协议以确保内存安全,并提供了各种从故障中恢复的选项。
由于Ray使用抽象资源而不是机器来表示计算能力,因此Ray应用程序可以无缝的从便携机环境扩展到群集,而无需更改任何代码。 Ray通过分布式溢出调度程序和对象管理器实现了无缝扩展,而开销却很低。
相关系统上下文集群管理系统:Ray可以在Kubernetes或SLURM之类的集群管理系统之上运行,以提供更轻量的task和Actor而不是容器和服务。
并行框架:与Python并行化框架(例如multiprocessing或Celery)相比,Ray提供了更通用,更高性能的API。 Ray系统还明确支持内存共享。
数据处理框架: 与Spark,Flink,MARS或Dask等数据处理框架相比,Ray提供了一个low-level且较简化的API。这使API更加灵活,更适合作为“分布式胶水”框架。另一方面,Ray对数据模式,关系表或流数据流没有内在的支持。仅通过库(例如Modin,Dask-on-Ray,MARS-on-Ray)提供此类功能。
Actor框架:与诸如Erlang和Akka之类的专用actor框架不同,Ray与现有的编程语言集成,从而支持跨语言操作和语言本机库的使用。 Ray系统还透明地管理无状态计算的并行性,并明确支持参与者之间的内存共享。
HPC系统:HPC系统都支持MPI消息传递接口,MPI是比task和actor更底层的接口。这可以使应用程序具有更大的灵活性,但是开发的复杂度加大了很多。这些系统和库中的许多(例如NCCL,MPI)也提供了优化的集体通信原语(例如allreduce)。 Ray应用程序可以通过初始化各组Ray Actor之间的通信组来利用此类原语(例如,就像RaySGD的torch distributed)。
系统设计 逻辑架构: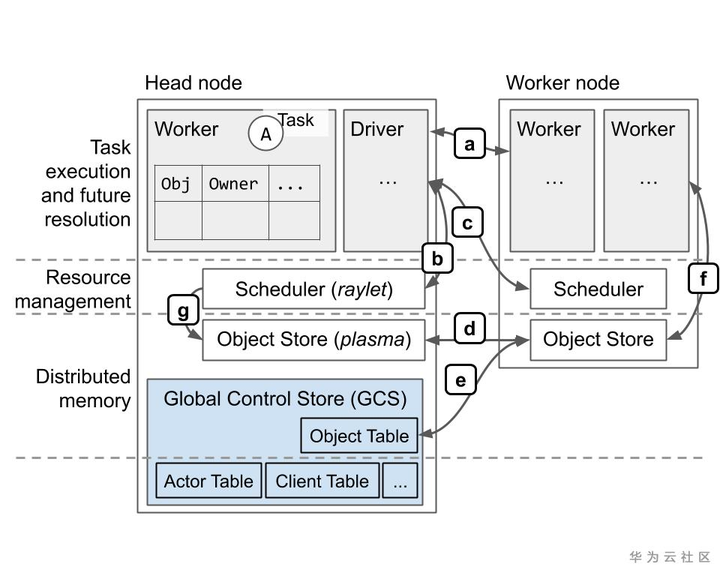
Task:在与调用者不同的进程上执行的单个函数调用。任务可以是无状态的(@ ray.remote函数)或有状态的(@ ray.remote类的方法-请参见下面的Actor)。任务与调用者异步执行:.remote()调用立即返回一个ObjectRef,可用于检索返回值。
Object:应用程序值。这可以由任务返回,也可以通过ray.put创建。对象是不可变的:创建后就无法修改。工人可以使用ObjectRef引用对象。
Actor:有状态的工作进程(@ ray.remote类的实例)。 Actor任务必须使用句柄或对Actor的特定实例的Python引用来提交。
Driver: 程序根目录。这是运行ray.init()的代码。
Job:源自同一驱动程序的(递归)任务,对象和参与者的集合
集群设计