哈希算法也叫散列算法, 不过英文单词都是 Hash, 简单一句话概括, 就是可以把任意长度的输入信息通过算法变换成固定长度的输出信息, 输出信息也就是哈希值, 通常哈希值的格式是16进制或者是10进制, 比如下面的使用 md5 哈希算法的示例
md5("123456") => "e10adc3949ba59abbe56e057f20f883e"主要特点:
不可逆 从哈希值不能推导出原始数据, 所以Hash算法广泛应用在现代密码体系中
无碰撞 不同的信息进行哈希后得到的值应该是不同的, 但是从理论上来说, 哈希算法其实是有可能发生碰撞的, 输入的信息是无穷的, 而输出的哈希值长度是固定的, 所以是有限的。好比要把10个苹果放到9个抽屉里面, 肯定会有一个抽屉装了多个苹果, 只不过哈希算法的碰撞的概率是非常小的, 比如128位的哈希值, 就有2的128次方的空间。
效率高 在处理比较大的原生值时, 也能能快速的计算出哈希值
无规律 原始输入信息修改一点信息, 得到的哈希值也是大不相同的
哈希算法的实现有很多, 常见的有 MD5, SHA-1, 还有像 C#, Java 一些语言都有直接的 GetHashCode(), hashCode() 函数可以直接来用。
分布式存储场景在互联网场景中, 通常面对的都是海量的数据,海量的用户, 那为了要满足大量数据的写入和查询, 以及高可用, 一台单机的存储服务器肯定是不能满足需求的, 通常需要使用多台服务器形成分布式存储。
场景描述:
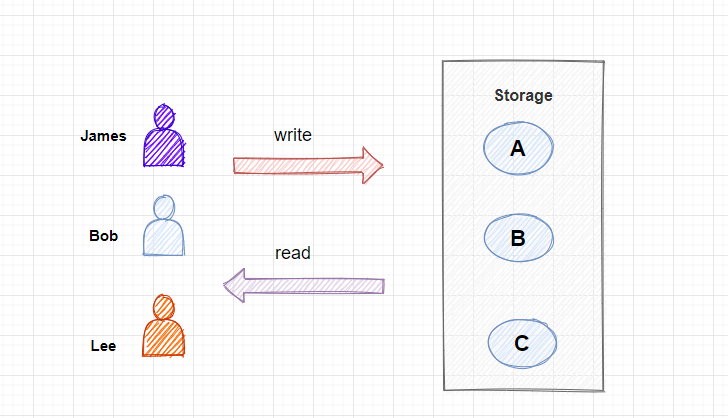
在本文中, 为了方便大家更好的理解, 这里列出了一个简单的例子, 有三位用户, 分别是 James、 Bob、 Lee, 我们需要把用户的图片写入到存储服务器节点, 这里有ABC三个节点, 而且当查询用户的图片时, 还需要快速定位到这个用户的图片是在哪个节点存储的, 然后直接从这个节点进行查询, 需要满足高效率的查询。
实现思路:
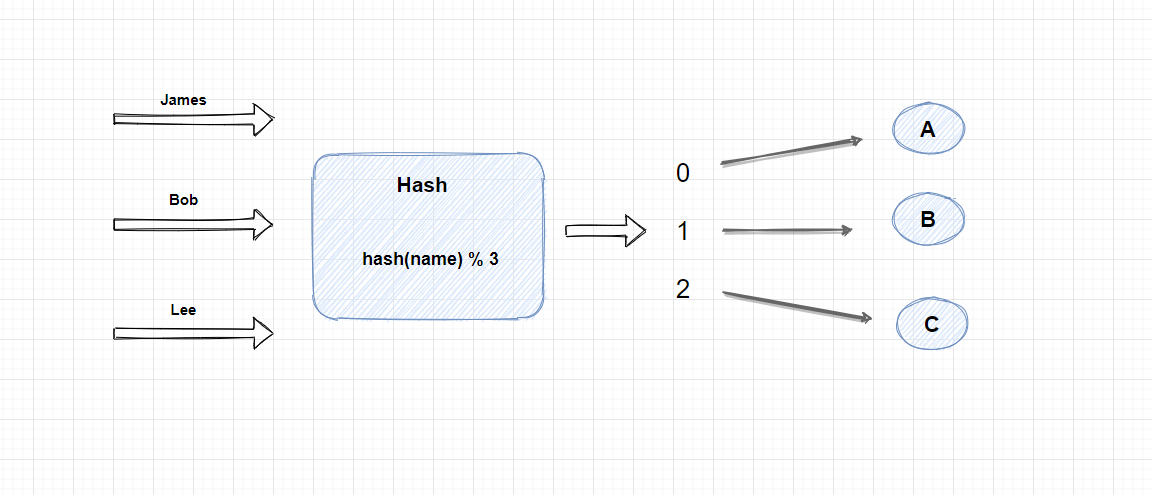
首先,我们可以对用户标识进行 Hash 计算, 这里我为了方便演示, 使用了用户名作为Hash对象, 当然你还可以对用户的IP或者是UserId 进行Hash计算, Hash计算后会生成一个int类型的数字, 然后再根据存储节点的数量进行取模, 这里的公式就是 hash(name) % 3, 计算得出的结果只有三种情况, 分别是 0,1,2, 然后我们再把这三种结果和三个存储节点做一个映射, 0 ==> A, 1 ==> B, 2 == C。 因为Hash算法对一个值多次计算后都会得到同样的hash值, 所以上面的公式, 一个用户的图片每次都会固定的写入的其中一个节点, 这样做查询的话, 也可以通过hash算法快速找到这个用户的图片所在的节点。
缺点:
上面我们使用Hash算法实现了负载均衡, 可以根据用户名路由到图片所在的节点, 但是上面的方法也有一个很大的缺点, 那就是当服务器的数量增加或者减少时, 我们通过Hash算法生成的路由规则就再不准确了。
试想一下, 如果新增或者减少一个节点, 上面的公式就会变成 hash(name) % 4 或者 hash(name) % 2, 这里的关键点是, 我们之前用3取模, 现在变成用4或者2取模, 结果当然大概率是不一样了, 当然如果 Hash后是12的话,用3或者4取模得到的结果都是为0, 不过这种概率比较小。
这个问题带来的影响是, 路由规则不再准确, 大部分的查询请求都扑了空。那么如何解决这个问题呢?相信有的同学这时应该有了一些想法, 是的没错, 关键点就在于, 不管节点的数量怎么变化, 都应该使用一个固定的值来进行取模! 只有这样才能保证每次进行Hash计算后, 得出的结果是不变的!
一致性Hash算法同样的,一致性Hash算法也是利用取模的方式, 不过通常是用一个很大的数字进行求模, 你可以用整数的最大值 int.Max, 2的32次方, 当然这个并没有要求, 不过越大的数字, 平均分配的概率就越大(后面会具体介绍这个问题)。
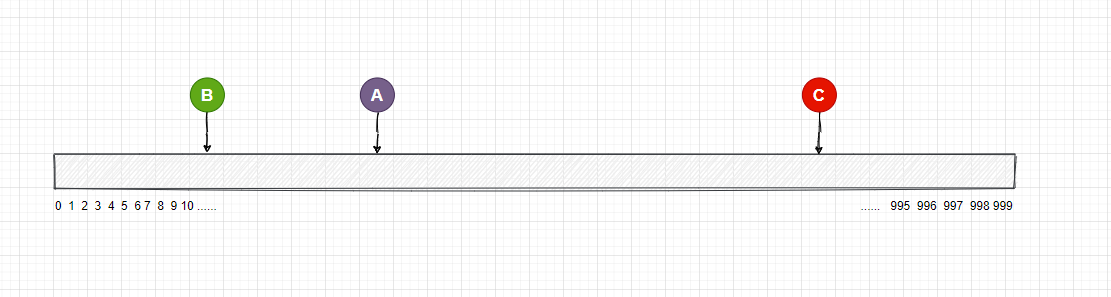
为了方便理解, 这里我用 1000 来取模, 我们可以用一个长度为1000的数组表示它,就像这样

接下来, 我们先不对用户的图片进行Hash处理, 而是先对每个节点进行 Hash 处理和映射, 现在的公式分别是 hash(A) % 1000, hash(B) % 1000,hash(C) % 1000, 这样得出的结果一定是在0-999 之间, 然后把这个值映射到数组中, 在代码中, 你可以用一个字典集合来保存这个映射关系。
对应的存储节点和数组的映射可能如下: