
EM 的英文是 Expectation Maximization,所以 EM 算法也叫最大期望算法。
我们先看一个简单的场景:假设你炒了一份菜,想要把它平均分到两个碟子里,该怎么分?
很少有人用称对菜进行称重,再计算一半的分量进行平分。大部分人的方法是先分一部分到碟子 A 中,然后再把剩余的分到碟子 B 中,再来观察碟子 A 和 B 里的菜是否一样多,哪个多就匀一些到少的那个碟子里,然后再观察碟子 A 和 B 里的是否一样多……整个过程一直重复下去,直到份量不发生变化为止。
你能从这个例子中看到三个主要的步骤:初始化参数、观察预期、重新估计。首先是先给每个碟子初始化一些菜量,然后再观察预期,这两个步骤实际上就是期望步骤(Expectation)。如果结果存在偏差就需要重新估计参数,这个就是最大化步骤(Maximization)。这两个步骤加起来也就是 EM 算法的过程。
/*请尊重作者劳动成果,转载请标明原文链接:*/
/* https://www.cnblogs.com/jpcflyer/p/11143638.html * /
二、EM 算法的工作原理
说到 EM 算法,我们先来看一个概念“最大似然”,英文是 Maximum Likelihood,Likelihood 代表可能性,所以最大似然也就是最大可能性的意思。
什么是最大似然呢?举个例子,有一男一女两个同学,现在要对他俩进行身高的比较,谁会更高呢?根据我们的经验,相同年龄下男性的平均身高比女性的高一些,所以男同学高的可能性会很大。这里运用的就是最大似然的概念。
最大似然估计是什么呢?它指的就是一件事情已经发生了,然后反推更有可能是什么因素造成的。还是用一男一女比较身高为例,假设有一个人比另一个人高,反推他可能是男性。最大似然估计是一种通过已知结果,估计参数的方法。
那么 EM 算法是什么?它和最大似然估计又有什么关系呢?EM 算法是一种求解最大似然估计的方法,通过观测样本,来找出样本的模型参数。
再回过来看下开头我给你举的分菜的这个例子,实际上最终我们想要的是碟子 A 和碟子 B 中菜的份量,你可以把它们理解为想要求得的 模型参数 。然后我们通过 EM 算法中的 E 步来进行观察,然后通过 M 步来进行调整 A 和 B 的参数,最后让碟子 A 和碟子 B 的参数不再发生变化为止。
实际我们遇到的问题,比分菜复杂。我再给你举个一个投掷硬币的例子,假设我们有 A 和 B 两枚硬币,我们做了 5 组实验,每组实验投掷 10 次,然后统计出现正面的次数,实验结果如下:
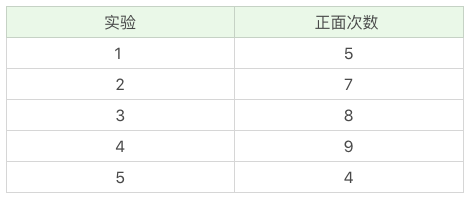
投掷硬币这个过程中存在隐含的数据,即我们事先并不知道每次投掷的硬币是 A 还是 B。假设我们知道这个隐含的数据,并将它完善,可以得到下面的结果:
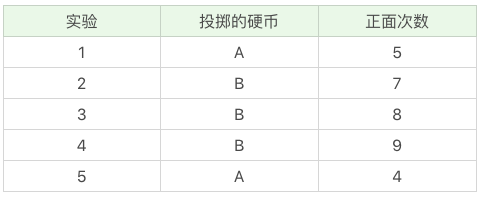
我们现在想要求得硬币 A 和 B 出现正面次数的概率,可以直接求得:
而实际情况是我不知道每次投掷的硬币是 A 还是 B,那么如何求得硬币 A 和硬币 B 出现正面的概率呢?
这里就需要采用 EM 算法的思想。
1. 初始化参数。我们假设硬币 A 和 B 的正面概率(随机指定)是θA=0.5 和θB=0.9。
2. 计算期望值。假设实验 1 投掷的是硬币 A,那么正面次数为 5 的概率为:
公式中的 C(10,5) 代表的是 10 个里面取 5 个的组合方式,也就是排列组合公式,0.5 的 5 次方乘以 0.5 的 5 次方代表的是其中一次为 5 次为正面,5 次为反面的概率,然后再乘以 C(10,5) 等于正面次数为 5 的概率。
假设实验 1 是投掷的硬币 B ,那么正面次数为 5 的概率为:
所以实验 1 更有可能投掷的是硬币 A。
然后我们对实验 2~5 重复上面的计算过程,可以推理出来硬币顺序应该是{A,A,B,B,A}。
这个过程实际上是通过假设的参数来估计未知参数,即“每次投掷是哪枚硬币”。
3. 通过猜测的结果{A, A, B, B, A}来完善初始化的参数θA 和θB。
然后一直重复第二步和第三步,直到参数不再发生变化。