
Ceph是当前非常流行的开源分布式存储系统,具有高扩展性、高性能、高可靠性等优点,同时提供块存储服务(rbd)、对象存储服务(rgw)以及文件系统存储服务(cephfs),Ceph在存储的时候充分利用存储节点的计算能力,在存储每一个数据时都会通过计算得出该数据的位置,尽量的分布均衡。。目前也是OpenStack的主流后端存储,随着OpenStack在云计算领域的广泛使用,ceph也变得更加炙手可热。国内目前使用ceph搭建分布式存储系统较为成功的企业有x-sky,深圳元核云,上海UCloud等三家企业。
Ceph架构介绍Ceph使用RADOS提供对象存储,通过librados封装库提供多种存储方式的文件和对象转换。外层通过RGW(Object,有原生的API,而且也兼容Swift和S3的API,适合单客户端使用)、RBD(Block,支持精简配置、快照、克隆,适合多客户端有目录结构)、CephFS(File,Posix接口,支持快照,社会和更新变动少的数据,没有目录结构不能直接打开)将数据写入存储。
高性能
a. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高
b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等
c. 能够支持上千个存储节点的规模,支持TB到PB级的数据
高可扩展性
a. 去中心化
b. 扩展灵活
c. 随着节点增加而线性增长
特性丰富
a. 支持三种存储接口:块存储、文件存储、对象存储
b. 支持自定义接口,支持多种语言驱动
Ceph核心概念 RADOS全称Reliable Autonomic Distributed Object Store,即可靠的、自动化的、分布式对象存储系统。RADOS是Ceph集群的精华,用户实现数据分配、Failover等集群操作。
LibradosRados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持。
CrushCrush算法是Ceph的两大创新之一,通过Crush算法的寻址操作,Ceph得以摒弃了传统的集中式存储元数据寻址方案。而Crush算法在一致性哈希基础上很好的考虑了容灾域的隔离,使得Ceph能够实现各类负载的副本放置规则,例如跨机房、机架感知等。同时,Crush算法有相当强大的扩展性,理论上可以支持数千个存储节点,这为Ceph在大规模云环境中的应用提供了先天的便利。
PoolPool是存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本分布策略,支持两种类型:副本(replicated)和 纠删码( Erasure Code);
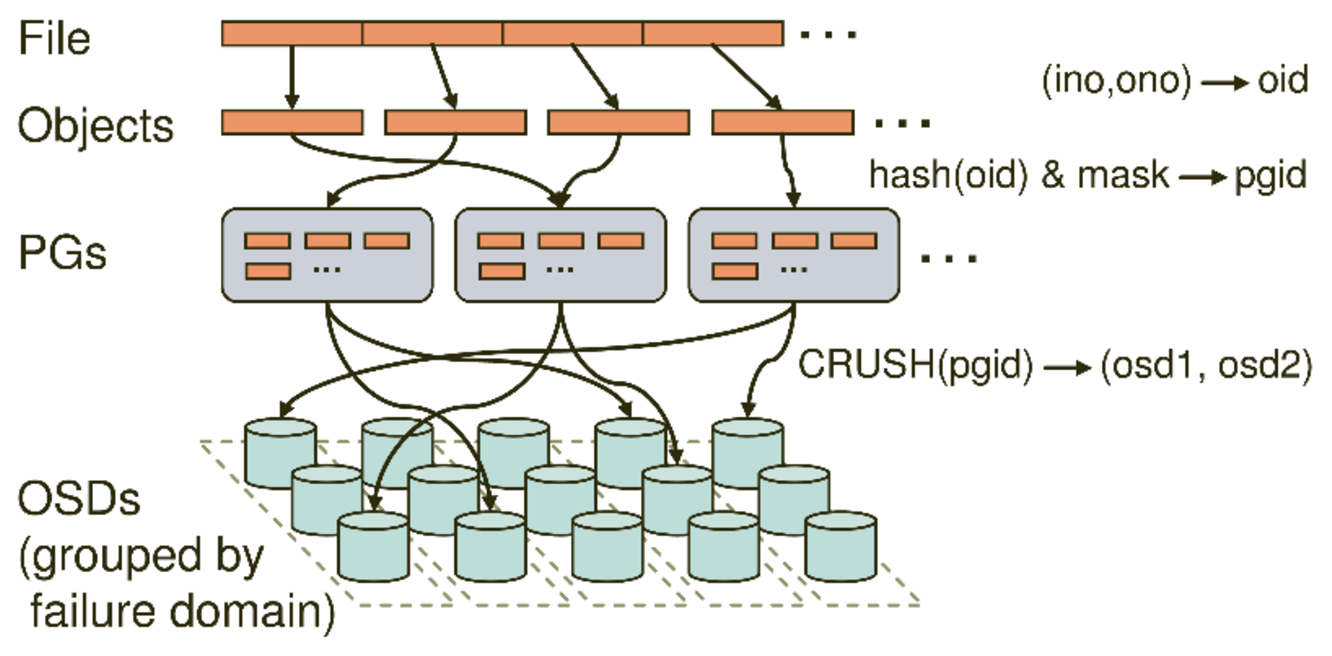
PGPG( placement group)是一个放置策略组,它是对象的集合,该集合里的所有对象都具有相同的放置策略,简单点说就是相同PG内的对象都会放到相同的硬盘上,PG是 ceph的逻辑概念,服务端数据均衡和恢复的最小粒度就是PG,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据;
Object简单来说块存储读写快,不利于共享,文件存储读写慢,利于共享。能否弄一个读写快,利于共享的出来呢。于是就有了对象存储。最底层的存储单元,包含元数据和原始数据。
Ceph核心组件 OSDOSD是负责物理存储的进程,一般配置成和磁盘一一对应,一块磁盘启动一个OSD进程。主要功能是存储数据、复制数据、平衡数据、恢复数据,以及与其它OSD间进行心跳检查,负责响应客户端请求返回具体数据的进程等;
Pool、PG和OSD的关系:
一个Pool里有很多PG;
一个PG里包含一堆对象,一个对象只能属于一个PG;
PG有主从之分,一个PG分布在不同的OSD上(针对三副本类型);
一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。负责监控整个Ceph集群运行的Map视图(如OSD Map、Monitor Map、PG Map和CRUSH Map),维护集群的健康状态,维护展示集群状态的各种图表,管理集群客户端认证与授权;
MDSMDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。负责保存文件系统的元数据,管理目录结构。对象存储和块设备存储不需要元数据服务;
Mgrceph 官方开发了 ceph-mgr,主要目标实现 ceph 集群的管理,为外界提供统一的入口。例如cephmetrics、zabbix、calamari、prometheus
RGWRGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
AdminCeph常用管理接口通常都是命令行工具,如rados、ceph、rbd等命令,另外Ceph还有可以有一个专用的管理节点,在此节点上面部署专用的管理工具来实现近乎集群的一些管理工作,如集群部署,集群组件管理等。
Ceph三种存储类型 块存储(RBD)优点:
通过Raid与LVM等手段,对数据提供了保护;
多块廉价的硬盘组合起来,提高容量;
多块磁盘组合出来的逻辑盘,提升读写效率;
缺点:
采用SAN架构组网时,光纤交换机,造价成本高;
主机之间无法共享数据;
使用场景
docker容器、虚拟机磁盘存储分配;
日志存储;
文件存储;
文件存储(CephFS)优点:
造价低,随便一台机器就可以了;
方便文件共享;
缺点:
读写速率低;
传输速率慢;
使用场景
日志存储;
FTP、NFS;
其它有目录结构的文件存储
对象存储(Object)(适合更新变动较少的数据)优点:
具备块存储的读写高速;
具备文件存储的共享等特性;
使用场景
图片存储;