
从一道亲身经历的面试题说起
半年前,我参加我现在所在公司的面试,面试官给了一道题,说有一个Y形的链表,知道起始节点,找出交叉节点.
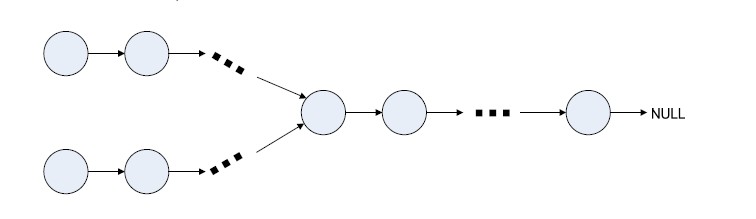
为了便于描述,我把上面的那条线路称为线路1,下面的称为线路2. 思路1
先判断线路1的第一个节点的下级节点是否是线路2的第一个节点,如果不是,再判断是不是线路2的第二个,如果也不是,判断是不是第三个节点,一直到最后一个.
如果第一轮没找到,再按以上思路处理线路一的第二个节点,第三个,第四个... 找到为止.
时间复杂度n2,相信如果我用的是这种方法,可肯定被Pass了.
首先,我遍历线路2的所有节点,把节点的索引作为key,下级节点索引作为value存入字典中.
然后,遍历线路1中节点,判断字典中是否包含该节点的下级节点索引的key,即dic.ContainsKey((node.next) ,如果包含,那么该下级节点就是交叉节点了.
时间复杂度是n.
那么问题来了,面试官问我了,为什么时间复杂度n呢?你有没有研究过字典的ContainsKey这个方法呢?难道它不是通过遍历内部元素来判断Key是否存在的呢?如果是的话,那时间复杂度还是n2才是呀?
我当时支支吾吾,确实不明白字典的工作原理,厚着面皮说 "不是的,它是通过哈希表直接拿出来的,不用遍历",面试官这边是敷衍过去了,但在我心里却留下了一个谜,已经入职半年多了,欠下的技术债是时候还了.
在看这篇文章前,不知道您使用字典的时候是否有过这样的疑问.
字典为什么能无限地Add呢?
从字典中取Item速度非常快,为什么呢?
初始化字典可以指定字典容量,这是否多余呢?
字典的桶buckets 长度为素数,为什么呢?
不管您以前有没有在心里问过自己这些问题,也不管您是否已经有了自己得答案,都让我们带着这几个问题接着往下走.
从哈希函数说起什么是哈希函数?
哈希函数又称散列函数,是一种从任何一种数据中创建小的数字“指纹”的方法。
下面,我们看看JDK中Sting.GetHashCode()方法.
可以看到,无论多长的字符串,最终都会返回一个int值,当哈希函数确定的情况下,任何一个字符串的哈希值都是唯一且确定的.
当然,这里只是找了一种最简单的字符数哈希值求法,理论上只要能把一个对象转换成唯一且确定值的函数,我们都可以把它称之为哈希函数.
这是哈希函数的示意图.

所以,一个对象的哈希值是确定且唯一的!. 字典
如何把哈希值和在集合中我们要的数据的地址关联起来呢?解开这个疑惑前我来看看一个这样不怎么恰当的例子:
有一天,我不小心干了什么坏事,警察叔叔没有逮到我本人,但是他知道是一个叫阿宇的干的,他要找我肯定先去我家,他怎么知道我家的地址呢?他不可能在全中国的家庭一个个去遍历,敲门,问阿宇是你们家的熊孩子吗?
正常应该是通过我的名字,找到我的身份证号码,然后我的身份证上登记着我的家庭地址(我们假设一个名字只能找到一张身份证).
阿宇-----> 身份证(身份证号码,家庭住址)------>我家
我们就可以把由阿宇找到身份证号码的过程,理解为哈希函数,身份证存储着我的号码的同时,也存储着我家的地址,身份证这个角色在字典中就是 bucket,它起一个桥梁作用,当有人要找阿宇家在哪时,直接问它,准备错的,字典中,bucket存储着数据的内存地址(索引),我们要知道key对应的数据的内存地址,问buckets要就对了.
key--->bucket的过程 ~= 阿宇----->身份证 的过程.

警察叔叔通过家庭住址找到了我家之后,我家除了住我,还住着我爸,我妈,他敲门的时候,是我爸开门,于是问我爸爸,阿宇在哪,我爸不知道,我爸便问我妈,儿子在哪?我妈告诉警察叔叔,我在书房呢.很好,警察叔叔就这样把我给逮住了.
字典也是这样,因为key的哈希值范围很大的,我们不可能声明一个这么大的数组作为buckets,这样就太浪费了,我们做法时HashCode%BucketSize作为bucket的索引.
假设Bucket的长度3,那么当key1的HashCode为2时,它数据地址就问buckets2要,当key2的HashCode为5时,它的数据地址也是问buckets2要的.