
(3)硬标签与软标签:对于一段音频,如果三个标注人员的标注结果是[L, L, M],那硬标签就是L,即[1, 0, 0];软标签则是[0.67, 0.33, 0],即三个类别的占比数。
(4)实验:比单独个人的标签建模提升1-4个百分点,软硬标签的设计有助于提升SER效果。只需标注目标人物50%的数据,就能取得标注100%的效果。意思是对于新来一个用户,他只需标注IEMOCAP 50%的数据,该模型就能取得他标注100%数据效果。
(5)总结:原理上确实众包的标注有利于推测个人的标签,但是没有跟其他模型进行对比,不过这也不是本文的重点。
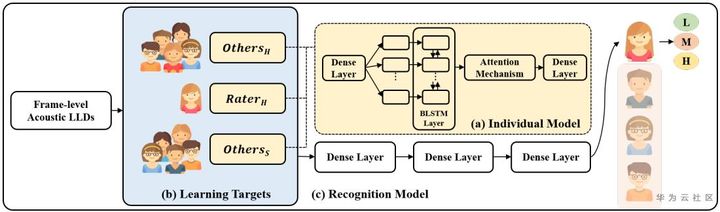
(1)数据处理:IEMOCAP数据四分类,Session1-4训练,Session5测试。特征提取23维的log-Mel filterbank。
(2)模型方法:一个utterance分成多帧,一份输入BLSTM+Attention模型,另一个输入CNN+Attention模型。然后将两个模型的结果融合。
(3)实验:采用WA,UA作为评价指标,但是文章定义UA错误,UA的定义实际为WA。而WA的定义也存疑。实验效果UA达80.1%,实为segment-level的Accuracy。并没有通用的句子级的Accuracy,也是评价的一个trick。
(4)总结:论文就是两个主流模型的结果级融合,创新性不高。提升只体现在segment-level的准确率,参考意义不大。