
双汇发展多个分厂的能源管控大数据系统主要采用两种技术栈:InfluxDB/Redis和Kafka/Redis/HBase/Flink,对于中小型研发团队来讲,无论是系统搭建,还是实施运维都非常棘手。经过对InfluxDB/Redis和TDengine大数据平台的功能和性能对比测试,最终将TDengine作为实施方案。
1. 项目背景基于双汇发展对能源管控的需求,利用云平台技术以及电气自动化处理手段,对双汇发展的一级、二级、三级能源仪表进行整体改造,实现仪表组网,进一步通过边缘网关进行能源在线监测数据的采集,并上报至云平台,建立统一能源管理信息化系统,实现能源的实时监控、报表统计、能源流向分析与预测,降低企业单位产品能源消耗,提高经济效益,最终实现企业能源精细化管理。
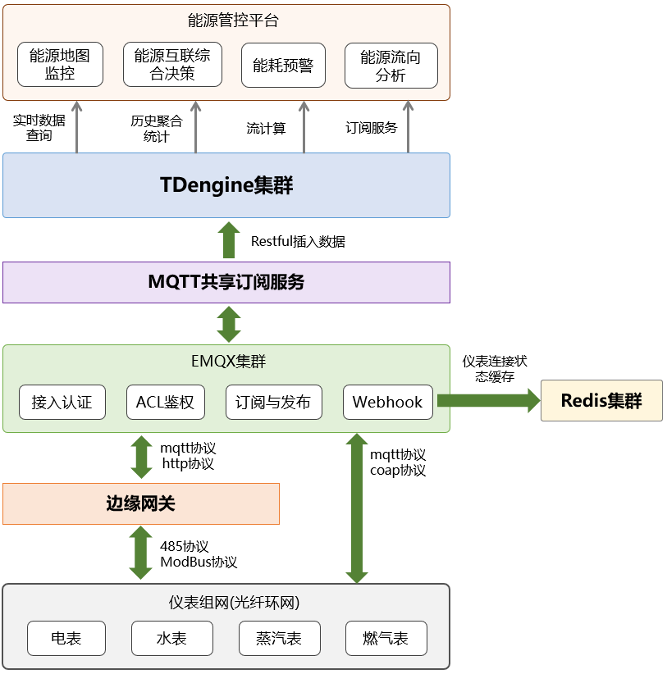
2. 总体架构能源管控平台基于私有云构建,包括完整的IaaS层、PaaS层和SaaS层,而能源采集系统作为管控平台中最为重要的一环,采用TDengine作为核心数据引擎,通过Restful接口进行仪表在线数据插入,并实现大规模时序数据的高效稳定存储,同时,也为能源管控应用层提供实时数据查询、历史聚合统计、流计算和订阅服务等功能,实现能源地图监控、能耗预警、能源流向预测和能源互联综合决策,具体架构如下图所示。
3.1 Connector选择
本项目数据采集最关键的环节,就是将订阅到的MQTT数据插入到TDengine中,于是也就涉及到了TDengine连接器的选择,我们平时项目中java使用居多,而且JDBC的性能也相对较强,理论上,应该选择JDBC API,但最终选择了RESTful Connector,主要考虑以下几点:
1)简洁性
毫无疑问,RESTful通用性最强,TDengine直接通过HTTP POST 请求BODY中包含的SQL语句来操作数据库,而且TDengine本身作为时序数据库并不提供存储过程或者事务机制,基本上都是每次执行单条SQL语句,所以RESTful在使用上很简便。
2)可移植性
本项目的Java应用都是部署在Kubernetes中,所以向TDengine插入数据的Java应用需要容器化部署,而之前了解到,JDBC需要依赖的本地函数库libtaos.so文件,所以容器化部署可能较为麻烦,而RESTful仅需采用OKHttp库即可实现,移植性较强。
3)数据规模
本项目数采规模不大,大约每分钟7000条数据,甚至后续数采功能扩展到其他分厂,RESTful也完全满足性能要求。
但总体来讲,JDBC是在插入与查询性能上具有一定优势的,而且支持从firstEp和secondEp选择有效节点进行连接(类似于Nginx的keepalive高可用),目前TDengine版本发布情况上看,JDBC的维护与提升也是重中之重,后续项目也可能会向JDBC迁移。
3.2 RESTful代码实现
1)ThreadPoolExecutor线程池
订阅EMQX和RESTful插入TDengine的代码写在了同一个java服务中,每接收到一条MQTT订阅消息,便开启一个线程向TDengine插入数据,线程均来自于线程池,初始化如下:
ExecutorService pool =newThreadPoolExecutor(150,300,1000,TimeUnit.MILLISECONDS,newArrayBlockingQueue<Runnable>(100),Executors.defaultThreadFactory(),newThreadPoolExecutor.DiscardOldestPolicy());
线程池采用基于数组的先进先出队列,采用丢弃早期任务的拒绝策略,因为本次场景中单次RESTful插入数据量大约在100~200条,执行速度快,迟迟未执行完极可能是SQL语句异常或连接taosd服务异常等原因,应该丢弃任务。核心线程数设为150,相对较高,主要为了保证高峰抗压能力。
2)OKHttp线程池
在每个ThreadPoolExecutor线程中,基于OKHttp库进行RESTful插入操作,也是采用ConnectionPool管理 HTTP 和 HTTP/2 连接的重用,以减少网络延迟,OKHttp重点配置如下:
publicConnectionPool pool(){returnnewConnectionPool(20,5,TimeUnit.MINUTES);}
即最大空闲连接数为20,每个连接最大空闲时间为5分钟,每个OKHttp插入操作采用异步调用方式,主要代码如下:
publicvoid excuteTdengineWithSqlAsync(String sql,Callback callback){
try{