okhttp3.MediaType mediaType = okhttp3.MediaType.parse("application/octet-stream");
RequestBody body =RequestBody.create(mediaType, sql);
Request request =newRequest.Builder()
.url(tdengineHost)
.post(body)
.addHeader("Authorization","Basic cm9vdDp0YW9zZGF0YQ==")
.addHeader("cache-control","no-cache")
.build();
mOkHttpClient.newCall(request).enqueue(callback);
}catch(Exception e){
logger.error("执行tdengine操作报错:"+ e.getMessage());
}
}
3)Java打包镜像
长期压力测试显示,每秒执行200次RESTful插入请求,单次请求包含100条数据,每条数据包含5组标签,Java服务内存稳定在300M~600M。而且上述模拟规模仅针对单个Java应用而言,在Kubernetes可以跑多个这样pod来消费不同的MQTT主题,所以并发能力完全够用。打包镜像时,堆内存最大值设为1024MB,主要语句为:
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-XX:MaxRAM=2000m","-Xms1024m","-jar","/app.jar"]
3.3 性能测试
1)RESTful插入性能
按照3.2小节中的RESTful代码进行数据插入,Java程序和TDengine集群均运行在私有云中,虚拟机之间配备万兆光纤交换机,Java程序具体如3.2小节所示,TDengine集群部署在3个虚拟机中,配置均为1TB硬盘、12核、12GB(私有云中CPU比较充裕,但内存比较紧张),经过大约三周的生产环境运行,性能总结如下:
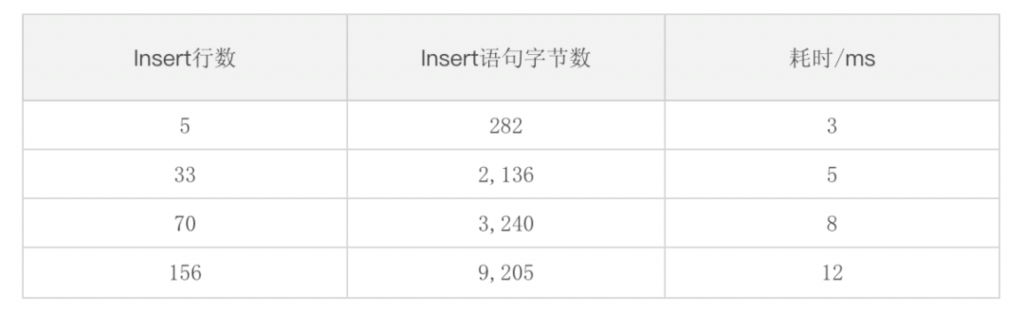
生产环境下,单条插入性能极高,完全满足需求,当然前期也进行过稍大规模的插入场景模拟,主要是基于2.0.4.0以后的版本,注意到2.0.4.0之前的TDengine版本RESTful的SQL语句上限为64KB。模拟环境下,RESTful插入性能非常优秀,具体如下表所示。
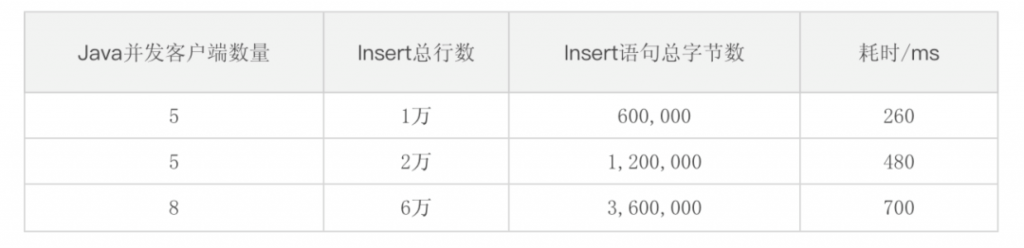
2)RESTful查询性能
使用RESTful进行SQL查询时,性能也是非常好,目前真实生产环境中,数据总量为800万,相对单薄,所以查询性能测试在模拟环境下进行,在8亿数据量下,LAST_ROW函数可以达到10ms响应速度,count、interval、group by等相关函数执行速度均在百毫秒量级上。
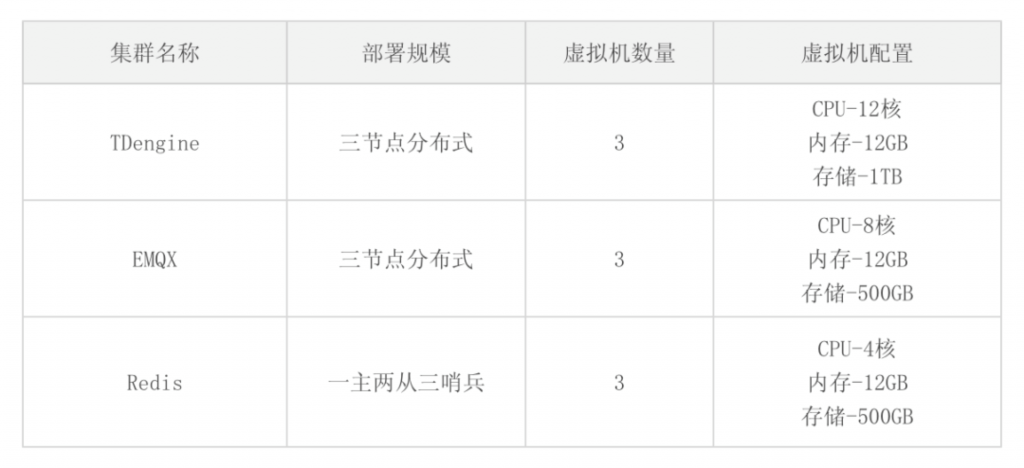
3.4 实施方案
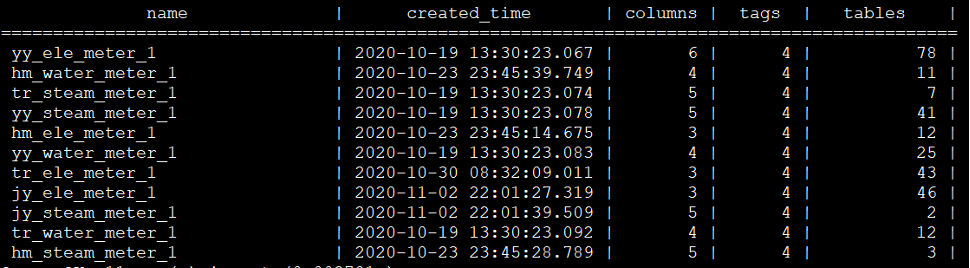
本项目针对双汇发展下属的6个分厂(后续会继续扩充)进行能源数据采集,大约1200多块仪表(后续会继续扩充),每块仪表包括3至5个采集标签,采集频率均为1分钟,数据接入规模不大。六个厂各自有独立的租户空间,为了方便各自的时序数据库管理,同时也方便各厂间的聚合查询(目前六个分厂均从属双汇发展总部),所以各分厂分别建立超级表,每个超级表包括4个tag,分别为厂编号、仪表级别、所属工序和仪表编号,具体超级表建表情况如下图所示。
主要用到的集群包括TDengine集群、EMQX集群和Redis集群,其中Redis集群在数据采集方面,仅仅用于缓存仪表连接状态,其重点在于缓存业务系统数据;EMQX集群用于支撑MQTT数据的发布与订阅,部署在Kubernetes中,可以实现资源灵活扩展;TDengine集群部署在IaaS虚拟机中,支持大规模时序数据的存储与查询。