
对于A中每一个操作块,只有每一行的第一个元素会不命中,所以为8次不命中;对于B中每一个操作块,只有每一列的第一个元素会不命中,所以也为 8 次不命中。总共miss次数为:8 × 16 × 2 = 256
跑出结果:
miss次数为343,与我们计算的结果差距非常大,没有得到满分,这是为什么呢?这就要考虑到对角线上的块了。A与B对角线上的块在缓存中对应的位置是相同的,而它们在转置过程中位置不变,所以复制过程中会发生相互冲突。
以A的一个对角线块p,B与p相应的对角线块q为例,复制前, p 在缓存中。 复制时,q会驱逐p。 下一个开始复制 p 又被重新加载进入缓存驱逐 q,这样就会多产生两次miss。
如何解决这种问题呢?题目给了我们提示:
You are allowed to define at most 12 local variables of type int per transpose function
考虑使用 8 个本地变量一次性存下 A 的一行后,再复制给 B。代码如下:
void transpose_submit(int M, int N, int A[N][M], int B[M][N]) { for(int i = 0; i < 32; i += 8) for(int j = 0; j < 32; j += 8) for (int k = i; k < i + 8; k++) { int a_0 = A[k][j]; int a_1 = A[k][j+1]; int a_2 = A[k][j+2]; int a_3 = A[k][j+3]; int a_4 = A[k][j+4]; int a_5 = A[k][j+5]; int a_6 = A[k][j+6]; int a_7 = A[k][j+7]; B[j][k] = a_0; B[j+1][k] = a_1; B[j+2][k] = a_2; B[j+3][k] = a_3; B[j+4][k] = a_4; B[j+5][k] = a_5; B[j+6][k] = a_6; B[j+7][k] = a_7; } }对于非对角线上的块,本身就没有额外的冲突;对于对角线上的块,写入A每一行的第一个元素后,这一行的元素都进入了缓存,我们就立即用本地变量存下这 8 个元素,随后再复制给B。这样,就避免了第一个元素复制时,B把A的缓冲行驱逐,导致没有利用上A的缓冲。
结果如下:
miss次数为 287,满分!
64 × 64每 4 行就会占满一个缓存,先考虑 4 × 4 分块,结果如下:
结果还不错,虽然没有得到满分。
还是考虑 8 × 8 分块,由于存在着每 4 行就会占满一个缓存的问题,在分块内部处理时就需要技巧了,我们把分块内部分成 4 个 4 × 4 的小分块分别处理:
第一步,将A的左上和右上一次性复制给B
第二步,用本地变量把B的右上角存储下来
第三步,将A的左下复制给B的右上
第四步,利用上述存储B的右上角的本地变量,把A的右上复制给B的左下
第五步,把A的右下复制给B的右下
画出图解如下:
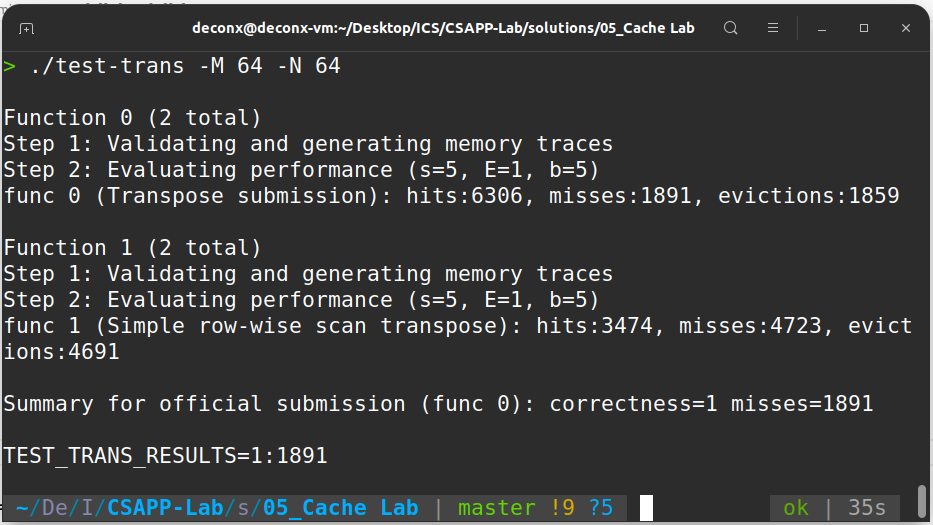
这里的A和B均表示两个矩阵中的 8 × 8 块
第 1 步:
此时B的前 4 行就在缓存中了,接下来考虑利用这个缓存 。可以看到,为了利用A的缓存,第 2 块放置的位置实际上是错的,接下来就用本地变量保存B中 2 块的内容
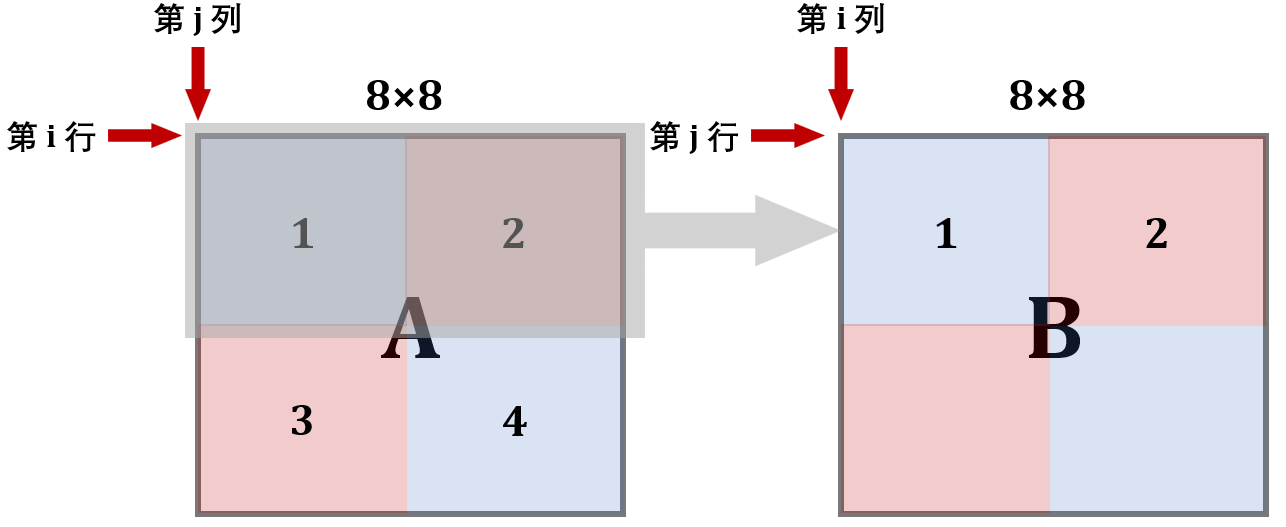
第 2 步:
用本地变量把B的 2 块存储下来
for (int k = j; k < j + 4; k++){ a_0 = B[k][i + 4]; a_1 = B[k][i + 5]; a_2 = B[k][i + 6]; a_3 = B[k][i + 7]; }第 3 步:
现在缓存中还是存着B中上两块的内容,所以将A的 3 块内容复制给它
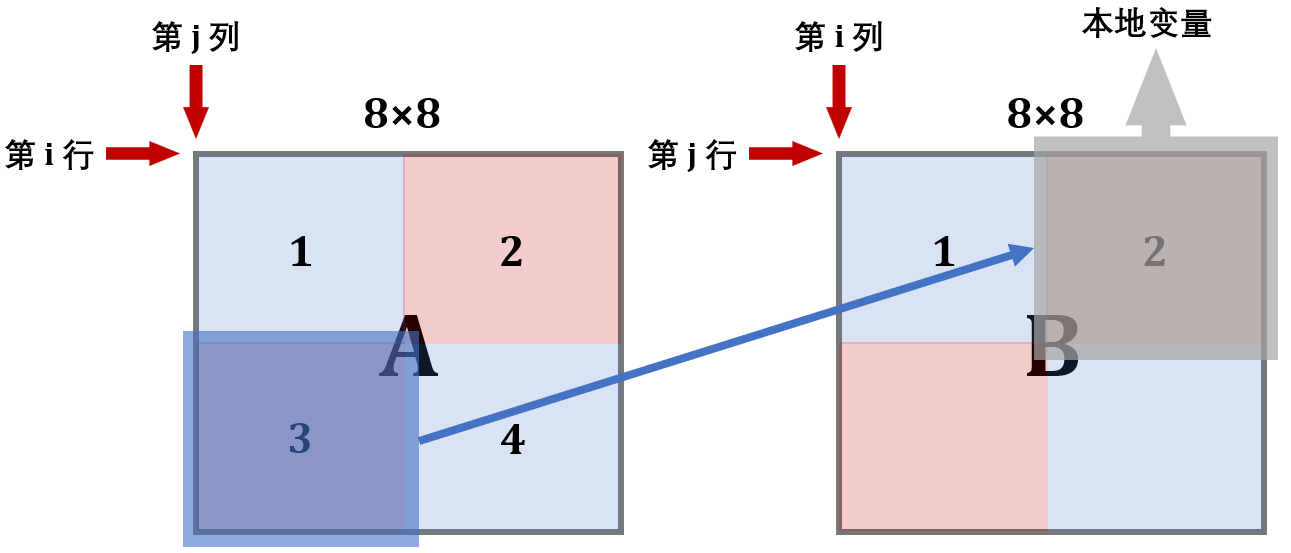
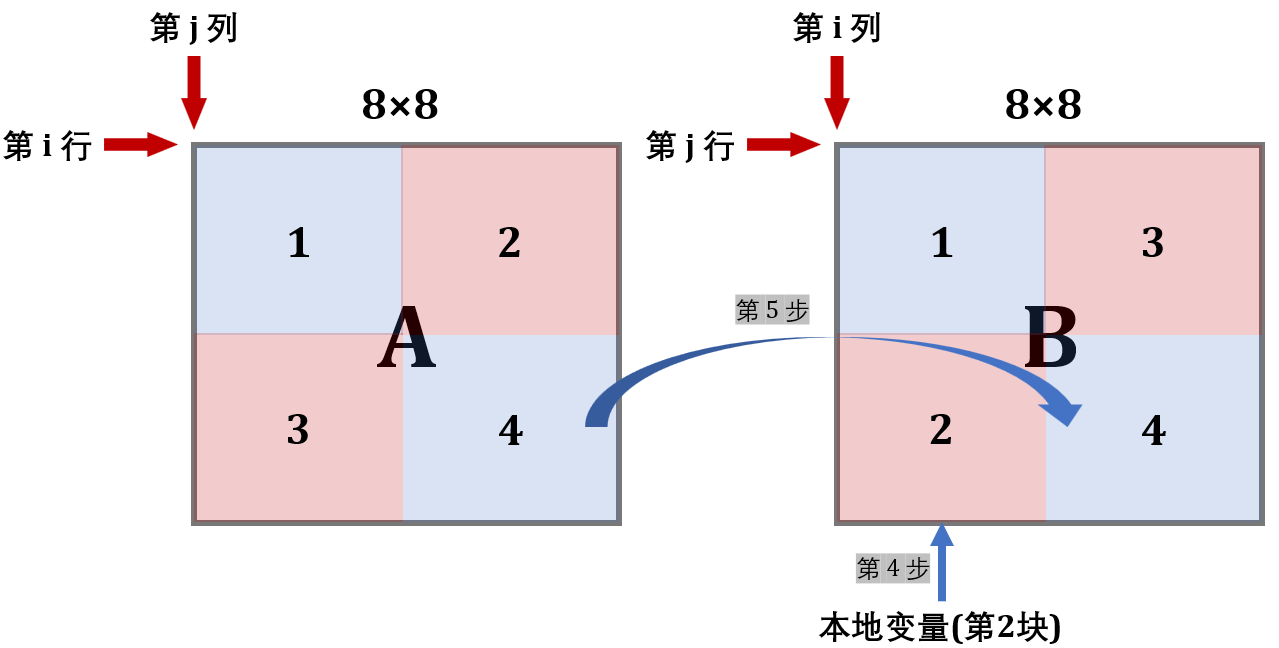
第 4/5 步:
现在缓存已经利用到极致了,可以开辟B的下面两块了
这样就实现了转置,且消除了同一行中的冲突,具体代码如下:
void transpose_64x64(int M, int N, int A[N][M], int B[M][N]) { int a_0, a_1, a_2, a_3, a_4, a_5, a_6, a_7; for (int i = 0; i < 64; i += 8){ for (int j = 0; j < 64; j += 8){ for (int k = i; k < i + 4; k++){ // 得到A的第1,2块 a_0 = A[k][j + 0]; a_1 = A[k][j + 1]; a_2 = A[k][j + 2]; a_3 = A[k][j + 3]; a_4 = A[k][j + 4]; a_5 = A[k][j + 5]; a_6 = A[k][j + 6]; a_7 = A[k][j + 7]; // 复制给B的第1,2块 B[j + 0][k] = a_0; B[j + 1][k] = a_1; B[j + 2][k] = a_2; B[j + 3][k] = a_3; B[j + 0][k + 4] = a_4; B[j + 1][k + 4] = a_5; B[j + 2][k + 4] = a_6; B[j + 3][k + 4] = a_7; } for (int k = j; k < j + 4; k++){ // 得到B的第2块 a_0 = B[k][i + 4]; a_1 = B[k][i + 5]; a_2 = B[k][i + 6]; a_3 = B[k][i + 7]; // 得到A的第3块 a_4 = A[i + 4][k]; a_5 = A[i + 5][k]; a_6 = A[i + 6][k]; a_7 = A[i + 7][k]; // 复制给B的第2块 B[k][i + 4] = a_4; B[k][i + 5] = a_5; B[k][i + 6] = a_6; B[k][i + 7] = a_7; // B原来的第2块移动到第3块 B[k + 4][i + 0] = a_0; B[k + 4][i + 1] = a_1; B[k + 4][i + 2] = a_2; B[k + 4][i + 3] = a_3; } for (int k = i + 4; k < i + 8; k++) { // 处理第4块 a_4 = A[k][j + 4]; a_5 = A[k][j + 5]; a_6 = A[k][j + 6]; a_7 = A[k][j + 7]; B[j + 4][k] = a_4; B[j + 5][k] = a_5; B[j + 6][k] = a_6; B[j + 7][k] = a_7; } } } }运行结果:
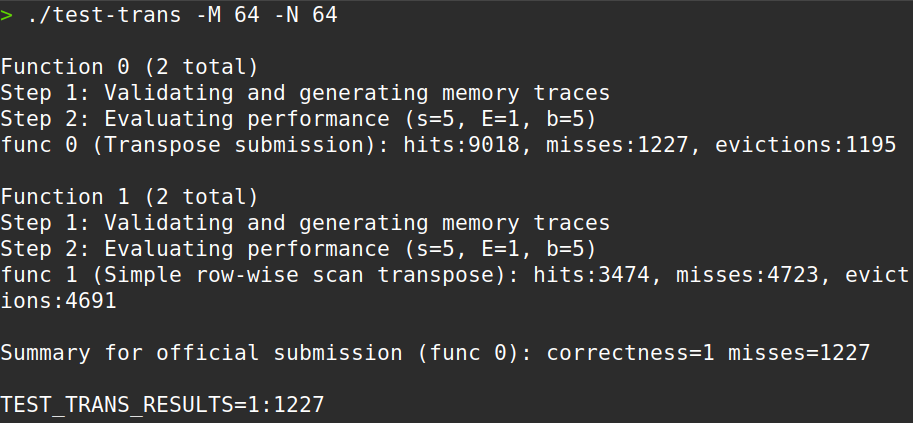
miss为 1227,通过!
61 × 67这个矩阵的转置要求很松,miss为 2000 以下就可以了。我也无心进行更深入的优化,直接 16 × 16 的分块就能通过。
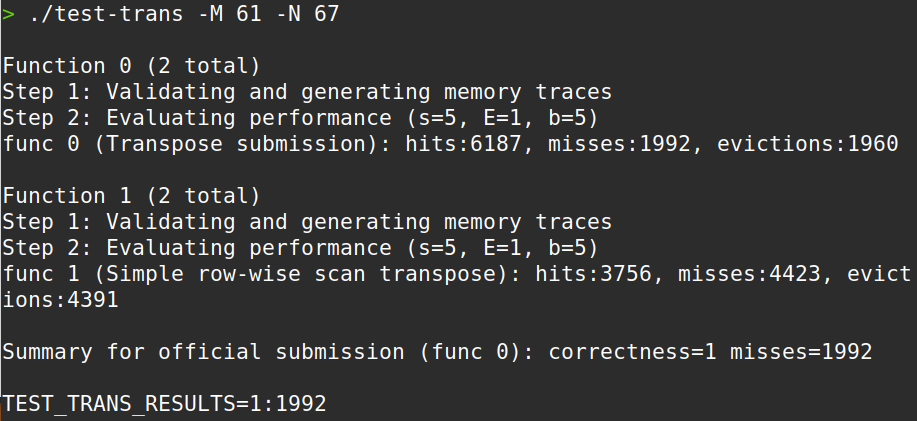
miss为 1992,擦线满分!
总结先附上满分完结图:
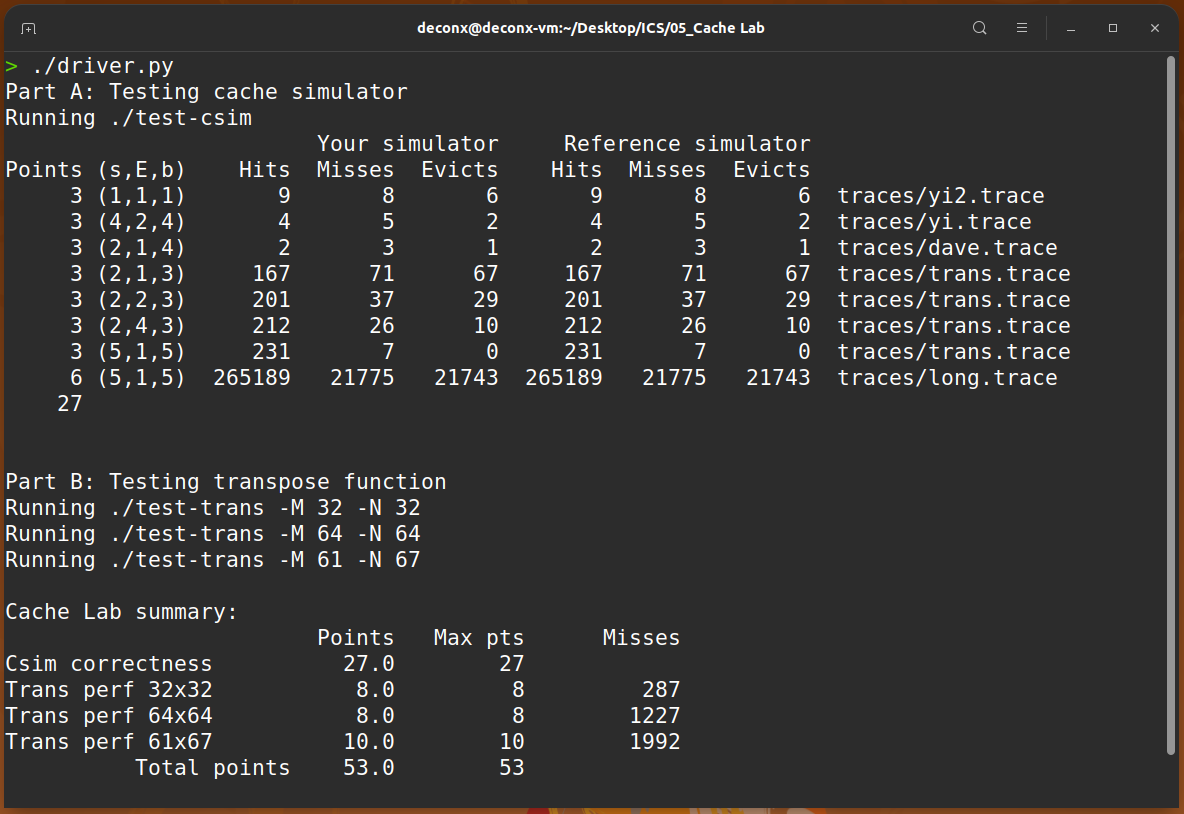
Cache Lab 是我在做前 5 个实验中感觉最痛苦的一个,主要原因在于我的代码能力较弱,逻辑思维能力较差,以后应该加强这方面的训练