
除了计算模块,它还有存储模块,存储分为4个象限。一四象限是存储数据本身的压缩能力,数据增长最直接的成本就是存储成本的上升,我们怎么做更好的压缩和编码以及indexing?这是一四象限做的相关工作;二三象限是在性能节省上做的相关工作,我们存储层其实是基于开源ORC的标准,我们在上面做了非常多的改进和优化,其中白框里面都有非常多的标准改动,我们读取性能对比开源Java ORC 均快 50%,我们是ORC社区过去两年最大贡献者,贡献了2W+行代码,这是我们在算子层和存储层的优化,这是最底层的架构。

但是从另外一个层面上来讲,单一的算子和部分的算子组合很难满足部分的场景需求,所以我们就提到灵活的算子组合。举几个数字,我们在Join上有4种模式,有3种Shuffling模式提供,有3种作业运行模式,有多种硬件支持和多种存储介质支持。图右是怎样去动态判别Join模式,使得运算效率更高。通过这种动态的算子组合,是我们优化的第二个维度。
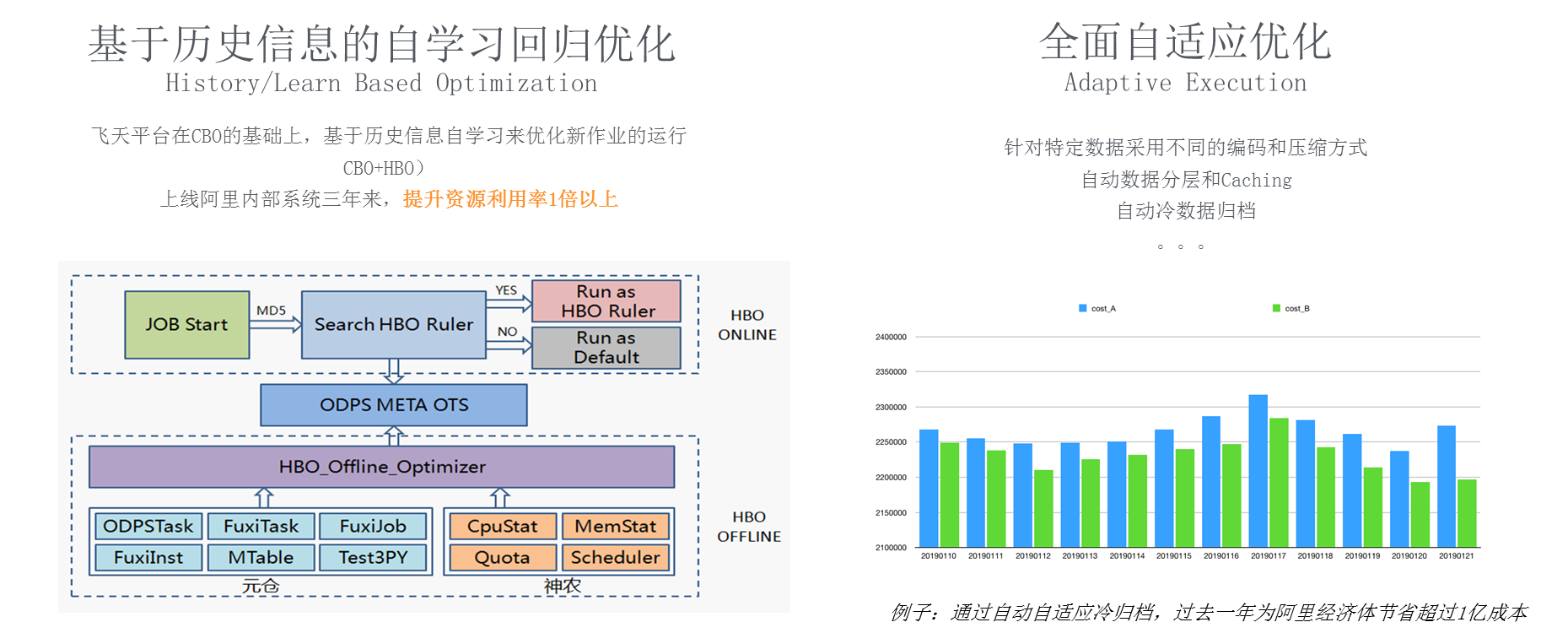
从引擎优化到自学习调优是我们在最近1年多的时间里花精力比较多的,我们在考虑如何用人工智能及自学习技术来做大数据系统,大家可以想象学骑自行车,刚开始骑得不好,速度比较慢甚至有的时候会摔倒,通过慢慢的学习,人的能力会越来越好。对于一个系统而言,我们是否可以用同样的方式来做?当一个全新的作业提交到这个系统时,系统对作业的优化是比较保守的,比如稍微多给一点资源,那么我选择的执行计划会相对比较保守一点,使得至少能够跑过去,当跑过之后就能够搜集到信息和经验,通过这些经验再反哺去优化数据,所以我们提出一个基于历史信息的自学习回归优化,底层是如图的架构图,我们把历史信息放在OFFLINE system去做各种各样的统计分析,当作业来了之后我们把这些信息反哺到系统之中去,让系统进行自学习。通常情况下,一个相似的作业大概跑了3到4次的时候,进入到一个相对比较优的过程,优指的是作业运行时间和系统资源节省。这套系统大概在阿里内部3年前上线的,我们通过这样的系统把阿里的水位线从40%提升到70%以上。
另外图中右侧也是一个自学习的例子,我们怎么区分热数据和冷数据,之前可以让用户自己去set,可以用一个普通的configuration去配置,后来发现我们采用动态的根据作业方式来做,效果会更好,这个技术是去年上线的,去年为阿里节约了1亿+人民币。从以上几个例子上来讲引擎层面和存储层面做的极致性能优化,性能优化又带来了用户成本的降低,在2019年9月1号,飞天大数据平台的整体存储成本降低了30%,同时我们发布了基于原生计算的新规格,可以实现最高70%的成本节省。
以上都是在引擎层面的优化,随着AI的普惠优化,AI的开发人员会越来越多,甚至很多人都不太具备代码的能力,阿里内部有10万名员工,每天有超过1万个员工在飞天大数据平台上做开发,从这个角度上来讲,不仅系统的优化是重要的,平台和开发平台的优化也是非常关键的。
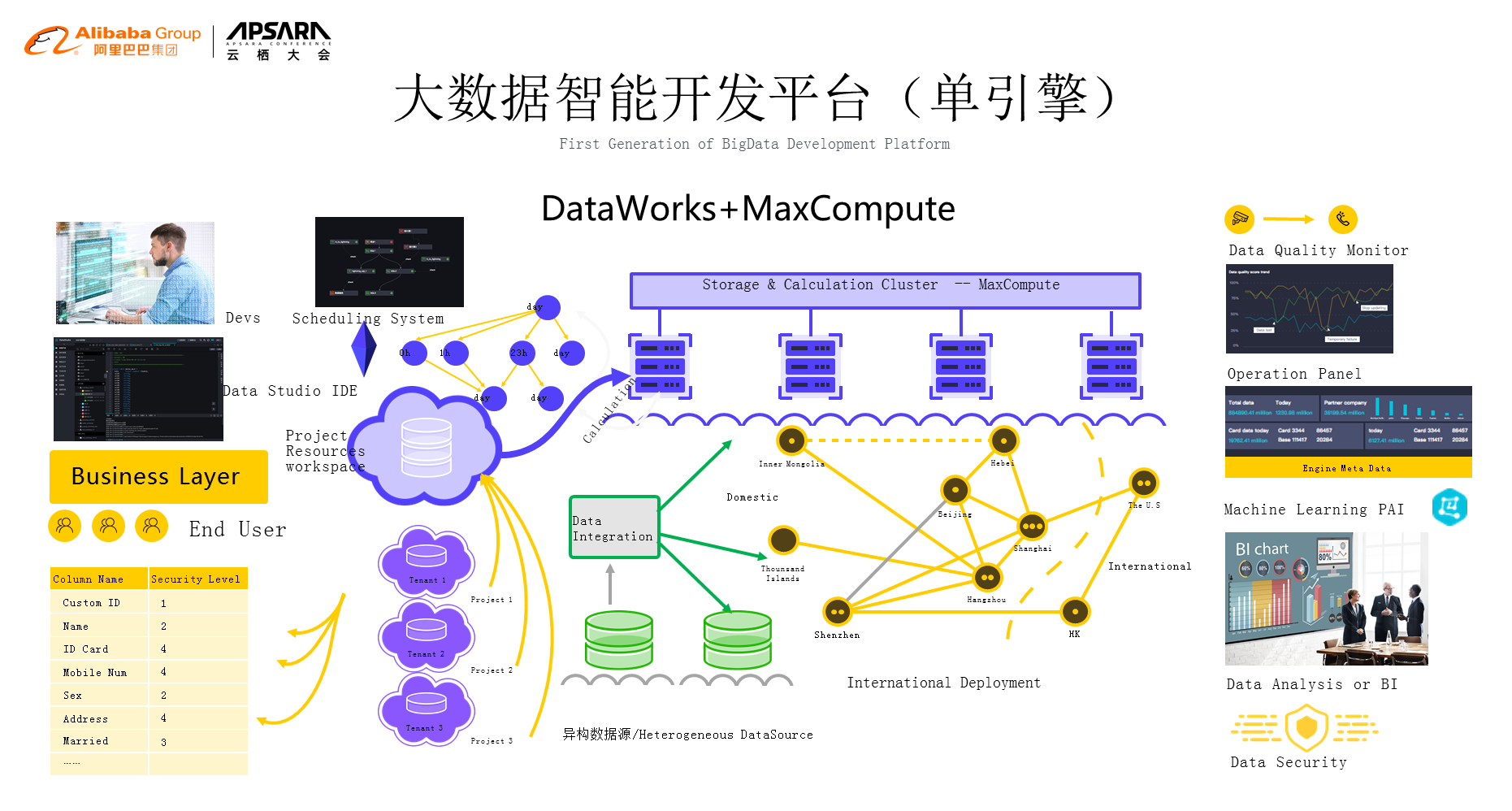
计算引擎对大家来说看不见摸不着,我们要去用它肯定希望用最简单的方式,先来看一下Maxcompute计算引擎。首先我们需要有用户,用户怎么来使用?需要资源隔离,也就是说每个用户在系统上面使用的时候会对应着账号,账号会对应着权限,这样就把整套东西串联起来。今天我的用户怎么用?用哪些部分?这是第一部分。第二部分是开发,开发有IDE,IDE用来写代码,写完代码之后提交,提交之后存在一个调度的问题,这么多的资源任务顺序是什么?谁先谁后,出了问题要不要中断,这些都由调度系统来管,我们的这些任务就有可能在不同的地方来运行,可以通过数据集成把它拉到不同的区域,让这些数据能够在整个的平台上跑起来,我们所有的任务跑起来之后我们需要有一个监控,同时我们的operation也需要自动化、运维化,再往下我们会进行数据的分析或者BI报表之类的,我们也不能够忘记machine learning也是在我们的平台上集成起来的。最后,最重要的就是数据安全,这一块整个东西构起一个大数据引擎的外沿+大数据引擎本身,这一套我们称之为单引擎的完备大数据系统,这一套系统我们在2017年的时候就具备了。