

我们提出一个概念叫Auto Data Warehouse,我们希望通过智能化的方式把大数据做得更聪明。整体上可以分成3个阶段:
第一阶段是计算层面和效率层面,我们尝试寻找计算的第一层原理,我们去找百万到千万级别里面的哪些作业是相似的,因此可以合并,通过这种方式来节省成本,还有当你有千万级别的表之后,究竟哪些表建索引全局是最优的,以及我们怎么去做冷热的数据分层和做自适应编码。
第二阶段是资源规划,AI和Auto Data Warehouse可以帮助我们做更好的资源优化,包括我们有3种的执行作业模式,哪一种模式更好,是可以通过学习的方式学出来的,还有包括作业的运行预测和自动预报警,这套系统保证了大家看得到或者看不到的阿里关键作业的核心,比如每过一段时间大家会刷一下芝麻信用分,每天早上九点阿里的商户系统会和下游系统做结算,和央行做结算,这些基线是由千百个作业组成的一条线,从每天早上凌晨开始运行到早上八点跑完,系统因为各种各样的原因会出现各种的状况,可能个别的机器会宕机。我们做了一个自动预测系统,去预测这个系统是否能够在关键时间点上完成,如果不能够完成,会把更多的资源加进来,保证关键作业的完成。这些系统保证了我们大家日常看不见的关键数据的流转,以及双十一等重要的资源弹性。
第三阶段是智能建模,当数据进来之后和里面已有的数据究竟有多少的重叠?这些数据有多少的关联?当数据是几百张表时,搞DBA手工的方式可以调优的,现在阿里内部的系统有超过千万级别的表,我们有非常好的开发人员理解表里面完全的逻辑关系。这些自动调优和自动建模能够帮助我们在这些方面做一些辅助性的工作。
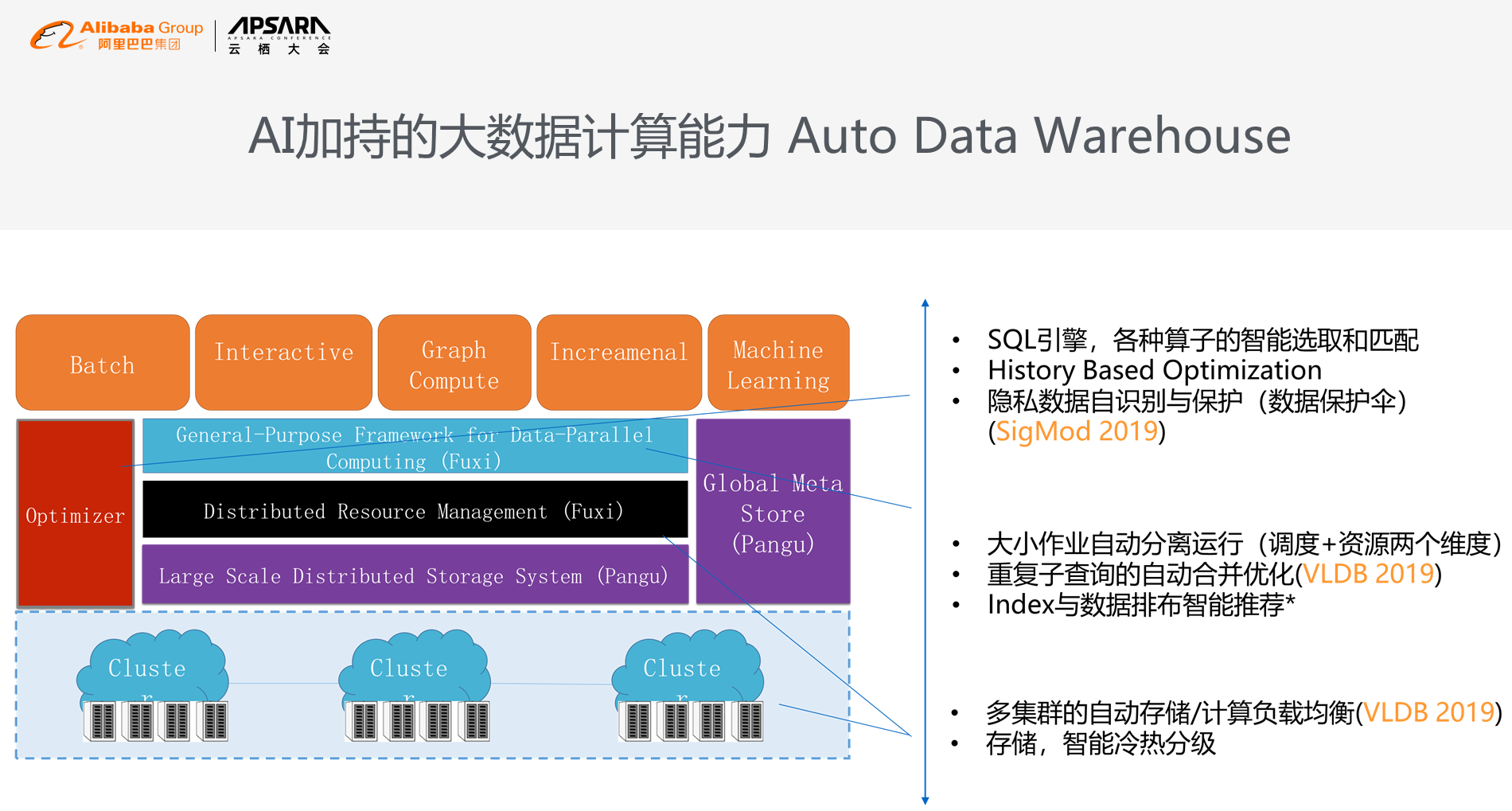
这是Auto Data Warehouse系统架构图,从多集群的负载均衡到自动冷存,到中间的隐形作业优化,再到上层的隐私数据自动识别,这是我们和蚂蚁一起开发的技术,当隐私的数据自动显示到屏幕上来,系统会自动检测并打码。我们其中的三项技术,包括自动隐私保护,包括重复子查询自动合并优化,包括多集群的自动容灾,我们有3篇paper发表,大家有兴趣的话可以去网站上读一下相关的论文。
MaxCompute 产品官网 >>>
DataWorks 产品官网 >>>
双11福利来了!先来康康#怎么买云服务器最便宜# [并不简单]参团购买指定配置云服务器仅86元/年,开团拉新享三重礼:1111红包+瓜分百万现金+31%返现,爆款必买清单,还有iPhone 11 Pro、卫衣、T恤等你来抽,马上来试试手气:https://www.aliyun.com/1111/2019/home?utm_content=g_1000083110