
摘要:2019云栖大会大数据&AI专场,阿里云智能计算平台事业部研究员关涛、资深专家徐晟来为我们分享《AI加持的阿里云飞天大数据平台技术揭秘》。本文主要讲了三大部分,一是原创技术优化+系统融合,打破了数据增长和成本增长的线性关系,二是从云原生大数据平台到全域云数仓,阿里开始从原生系统走入到全域系统模式,三是大数据与AI双生系统,讲如何更好的支撑AI系统以及通过AI系统来优化大数据系统。
直播回放 >>>
以下是精彩视频内容整理
说到阿里巴巴大数据,不得不提到的是10年前王坚博士率领建构的飞天大数据平台,十年磨一剑,今天飞天大数据平台已是阿里巴巴10年大平台建设最佳实践的结晶,是阿里大数据生产的基石。飞天大数据平台在阿里巴巴集团内每天有数万名数据和算法开发工程师在使用,承载了阿里99%的数据业务构建。同时也已经广泛应用于城市大脑、数字政府、电力、金融、新零售、智能制造、智慧农业等各领域的大数据建设。

在2015年的时候,我们开始关注到数据的海量增长对系统带来了越来越高的要求,随着深度学习的需求增长,数据和数据对应的处理能力是制约人工智能发展的关键问题,我们在给客户聊到一个摆在每个CIO/CTO面前的现实问题——如果数据增长10倍,应该怎么办?图中数字大家看得非常清晰,非常简单的拍立淘系统背后是PB的数据在做支撑,阿里小蜜客服系统有20个PB,大家每天在淘宝上日常使用的个性化推荐系统,后台要超过100个PB的数据来支撑后台的决策,10倍到100倍的数据增长是非常常见的。从这个角度上来讲,10倍的数据增长通常意味着什么问题?
第一,意味着10倍成本的增长,如果考虑到增长不是均匀的,会有波峰和波谷,可能需要30倍弹性要求;第二,实际上因为人工智能的兴起,二维结构性的关系型数据持续性增长的同时,带来的是非结构化数据,这种持续的数据增长里面,一半的增长来自于这种非结构化数据,我们除了能够处理好这种二维的数据化之后,我们如何来做好多种数据融合的计算?第三,阿里有一个庞大的中台团队,如果说我们的数据增长了10倍,我们的团队是不是增长了10倍?如果说数据增长了10倍,数据的关系复杂度也超过了10倍,那么人工的成本是不是也超过了10倍以上,我们的飞天平台在2015年后就是围绕这三个关键性的问题来做工作的。
当阿里巴巴的大数据走过10万台规模的时候,我们已经走入到技术的无人区,这样的挑战绝大多数公司不一定能遇到,但是对于阿里巴巴这样的体量来讲,这个挑战是一直摆在我们面前的。
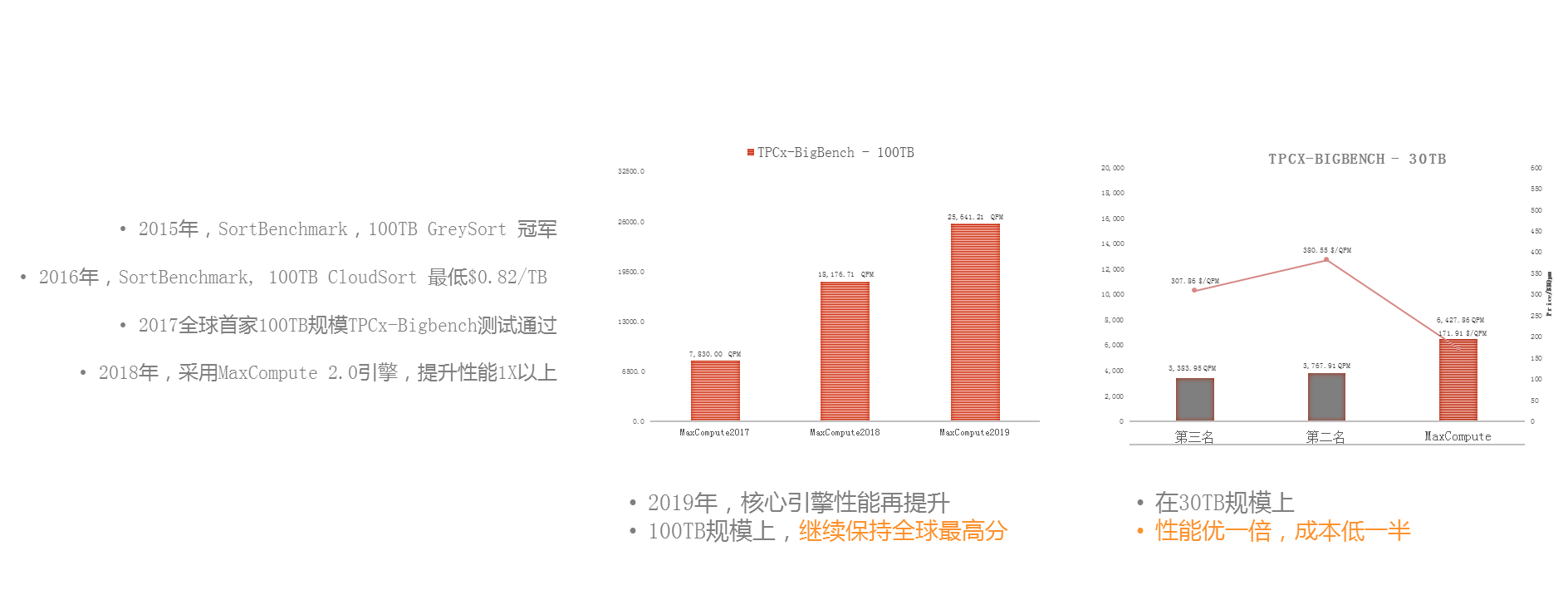
大家可以看到,2015年的时候,我们整个的体系建立起来之后,就开始做各种各样的Benchmark,比如2015年100TB的Sorting,2016年我们做CloudSort,去看性价比,2017年我们选择了Bigbench。如图是我们最新发布的数据,在2017、2018和2019年,每年都有一倍的性能提升,同时我们在30TB的规模上比第二名的产品有一倍的性能增长,并且有一半的成本节省,这是我们的计算力持续上升的优化趋势。
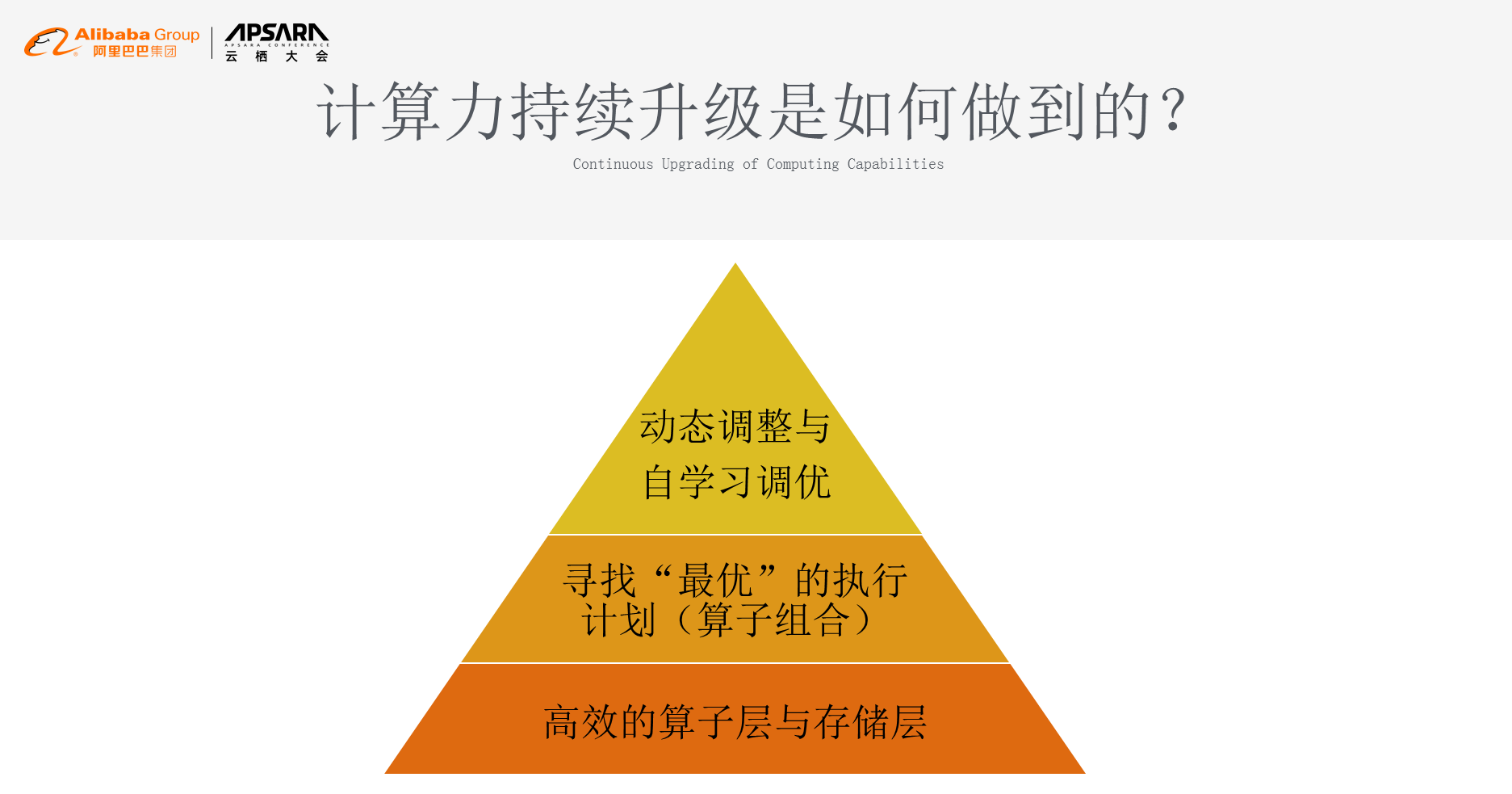
那么,计算力持续升级是如何做到的?如图是我们经常用到的系统升级的三角理论,最底层的计算模型是高效的算子层和存储层,这是非常底层的基础优化,往上面要找到最优的执行计划,也就是算子组合,再往上是新的方向,即怎么做到动态调整与自学习的调优。
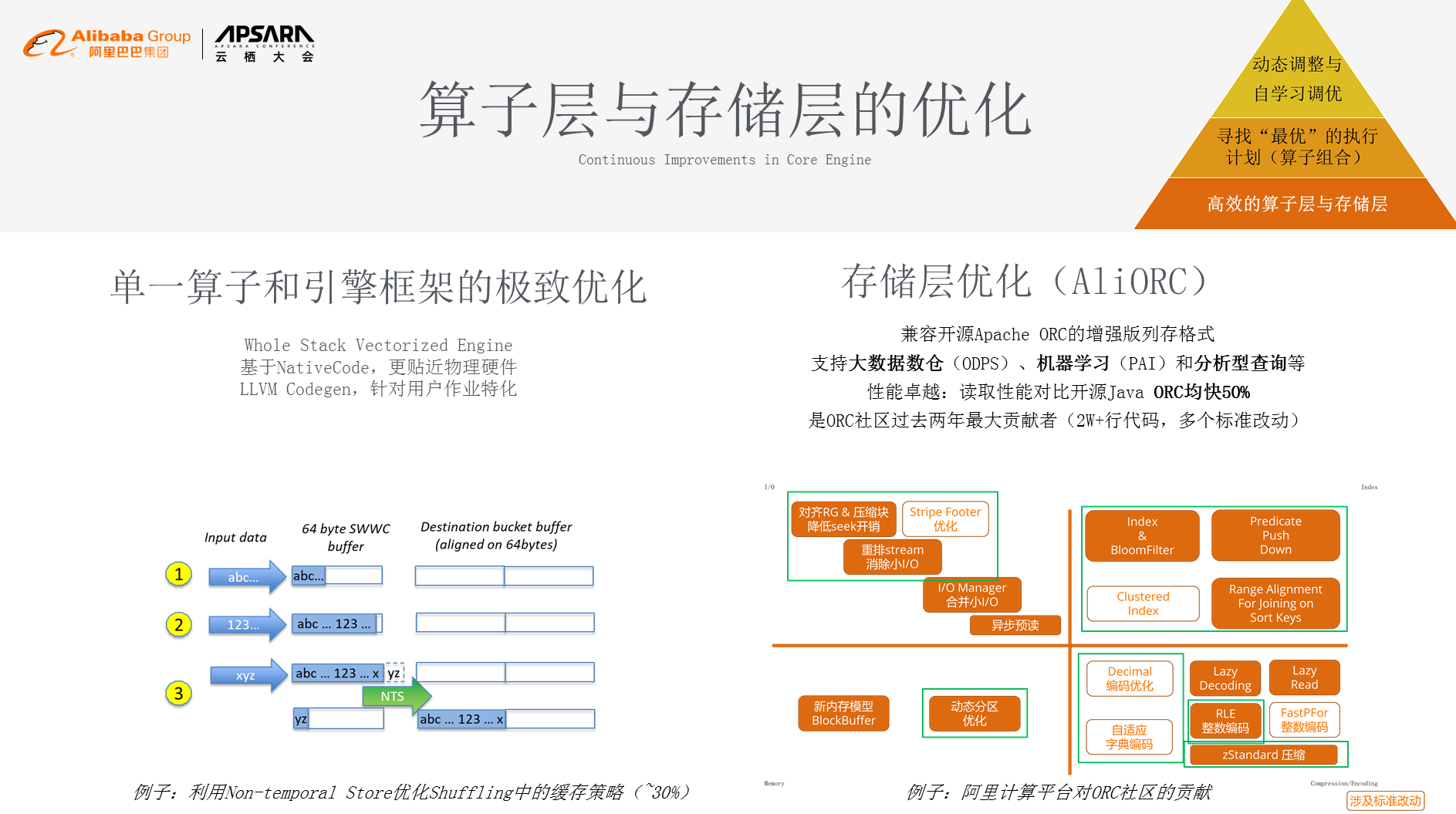
我们先来看单一算子和引擎框架的极致优化,我们用的是比较难写难维护的框架,但是因为它比较贴近物理硬件,所以带来了更极致的性能追求。对于很多系统来说可能5%的性能提升并不关键,但对于飞天技术平台来讲,5%的性能提升就是5千台的规模,大概就是2~3亿的成本。如图做了一个简单的小例子做单一算子的极致优化,在shuffle子场景中,利用Non-temporal Store优化shuffling中的缓存策略,在这样的策略上有30%的性能提升。