
InnoDB、MyISAM、Memory、CSV、Archive、Blackhole、Merge、Federated、Example
用的最广泛的,就是 InnoDB 了。打从 MySQL 5.5 之后,InnoDB 就是 MySQL 默认的存储引擎了。
所以,存储引擎其实并不是什么高大上的东西,跟什么大学拿去交作业的图书馆管理系统区别,就差了亿点而已。
或者,我再举个例子。我们往我们电脑上的文件中写入数据,此时由于 OS 的优化,数据并不会直接写入磁盘,因为 I/O 操作相当的昂贵。数据会先进入到 OS 的 Cache 中,由 OS 之后刷入磁盘。而 MySQL 在整个的逻辑结构上,跟计算机写文件差不多。
从上面的例子看出,存储引擎可以分为两部分:
内存
磁盘
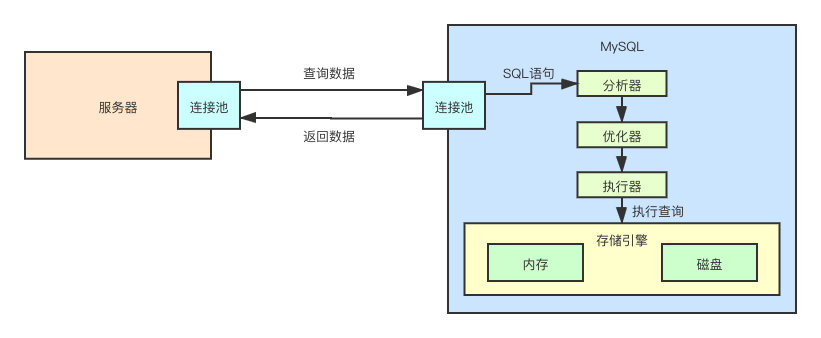
所以,从宏观上来说,MySQL 就是把数据在缓存在内存中,鼓捣鼓捣,然后在某些时候刷入磁盘中去,就这么回事。
接下来,就让我们深入存储引擎 InnoDB 的底层原理中相当重要的一部分——内存架构。
简单来说,InnoDB 的内存由以下两部分组成:
Buffer Pool
Log Buffer
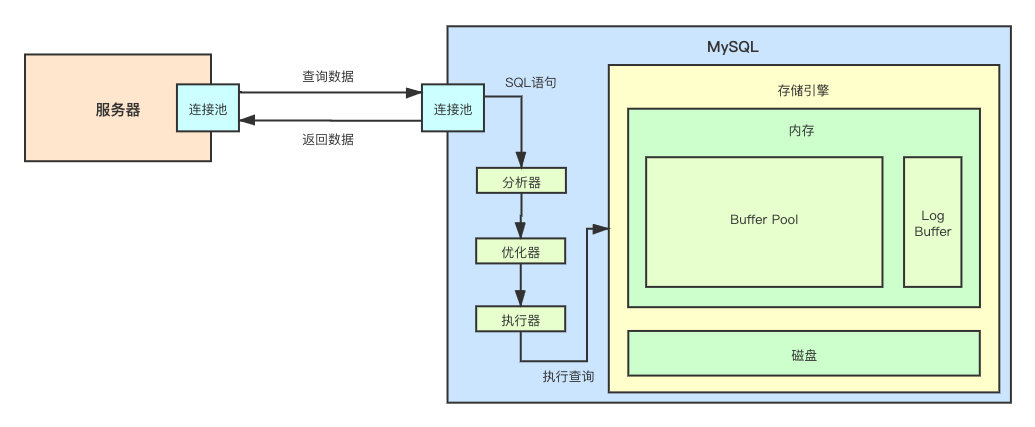
从上面画的图就能够看出,Buffer Pool 是 InnoDB 中非常重要的一部分,MySQL 之所以这么快其中一个重要的原因就是其数据都存在内存中,而这个内存就是 Buffer Pool。
Buffer Pool一般来说,宿主机的 80% 的内存都会分配给 Buffer Pool。这个很好理解,内存越大,就能够存下更多的数据。这样一来更多的数据将可以直接在内存中读取,可以大大的提升操作效率。
那 Buffer Pool 中到底是如何存储数据的呢?如果其底层的数据存储不进行特殊的设计、优化,那么 InnoDB 在取数据的时候除了整个遍历之外,没有其他的捷径。而如果那样做,MySQL 也不会获得今天这样的地位。
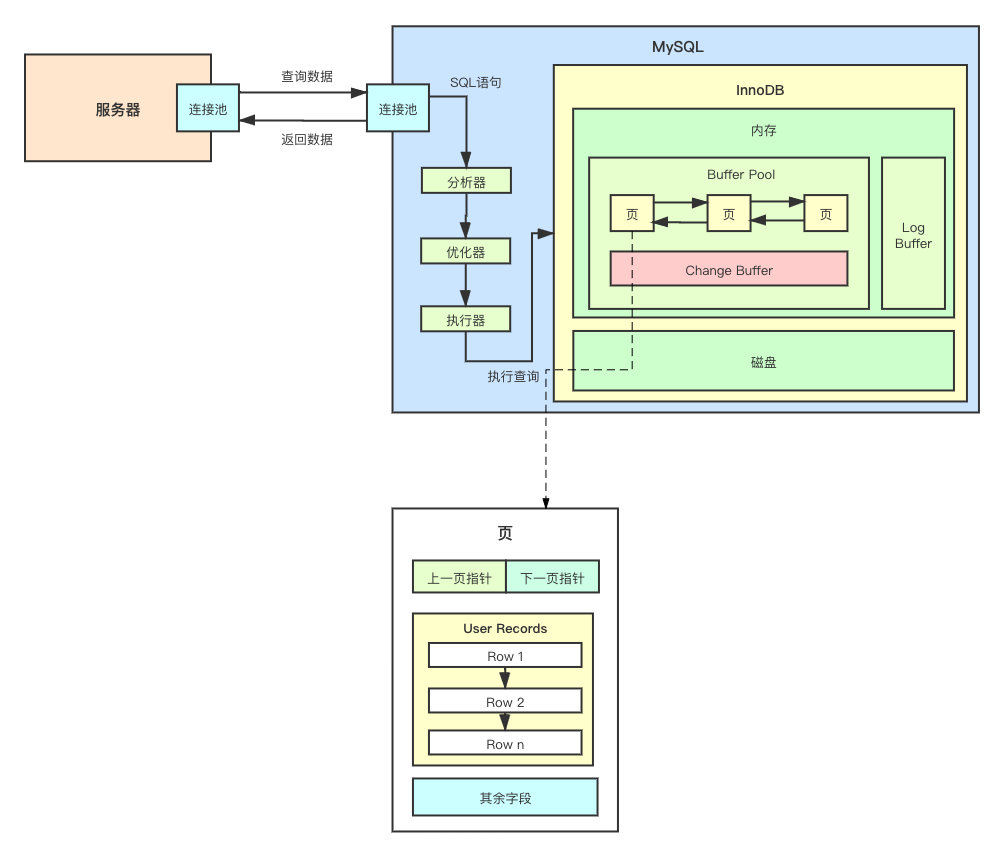
页如果我们能想象一下,InnoDB 会如何组织内存的数据。想象一下,图书馆的书是直接一本一本的摊在地上好找,还是按照类目、名称进行分类、放到对应的书架上、再进行编号好找?结论自然不言而喻。Buffer Pool 也采用了同样的数据整合措施。
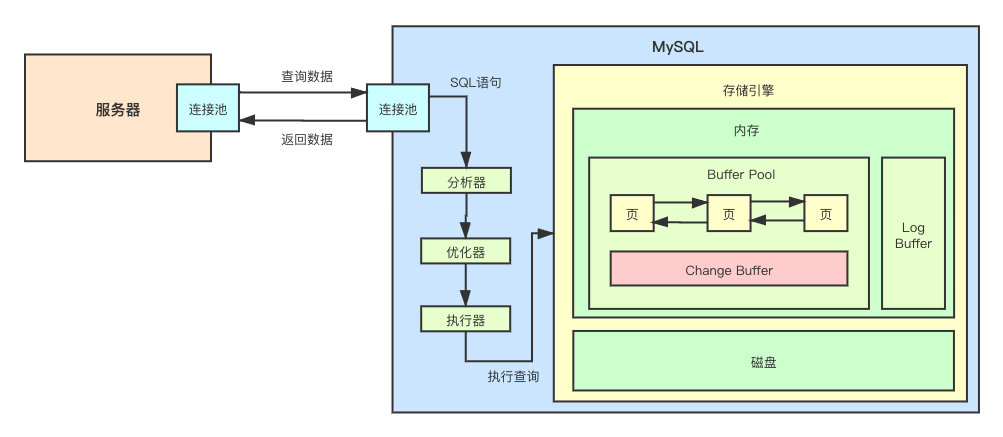
InnoDB 将 Buffer Pool 分成了一张一张的页(Pages),同时还有个 Change Buffer(后面会详细讲,这里先知道就行)。分成一页一页的数据就能够提升查询效率吗?那这个页里面到底是个啥呢?
可以从上图看到,页和页之间,实际上是有关联的,他们通过双向链表进行连接,可以方便的从某一页跳到下一页。
那数据在页中具体是如何存储的呢?
User Records当然,光跳来跳去的并不能说明任何问题,我们还是揭开页(Pages)这个黑盒的面纱吧。
!
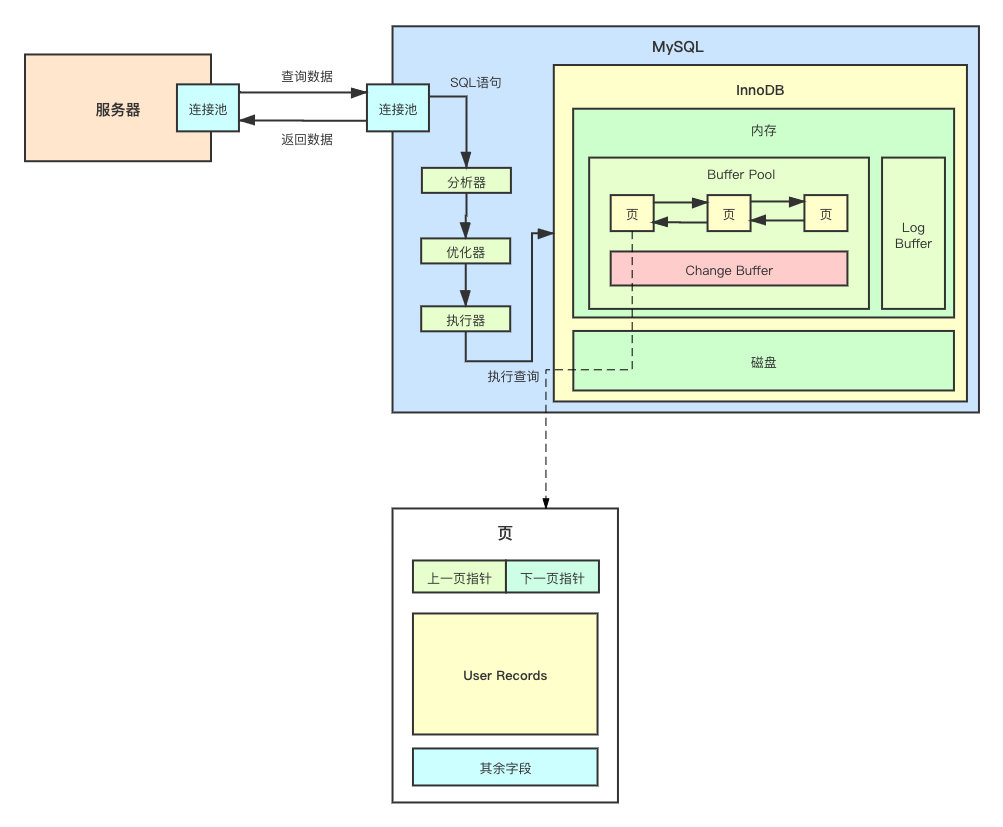
可以看到,主要就分为
上一页指针
下一页指针
User Records
其余字段
为了方便理解,其余字段我后续会补充
上一页指针、下一页指针就不多赘述,就是一个指针。重点我们需要了解 User Records。
User Records 就是一行一行的数据**(Rows)最终存储的地方,其中,行与行之间形成了单向链表**。
看了这个单向链表不知道你有没有一个疑问。
我们知道,在聚簇索引中,Key 实际上会按照 Primary Key 的顺序来进行排列。那在 User Records 中也会这样吗?我们插入一条新的数据到 User Records 中时,是否也会按照 Primary Key 的顺序来对已有的数据重排序?
如果每次插入数据都需要对 User Records 中的数据进行重排序,那么 MySQL 的江湖地位将再次不保。
虽然在图中看起来是按照「主键」的顺序存储的,但实际上是按照数据的插入顺序来存储的,先到的数据会在前面,后到的数据会在后面,只是每个 User Records 数据的指针指向的不是物理上的下一个,而是逻辑上的下一个。
用图来表示,大概如下:
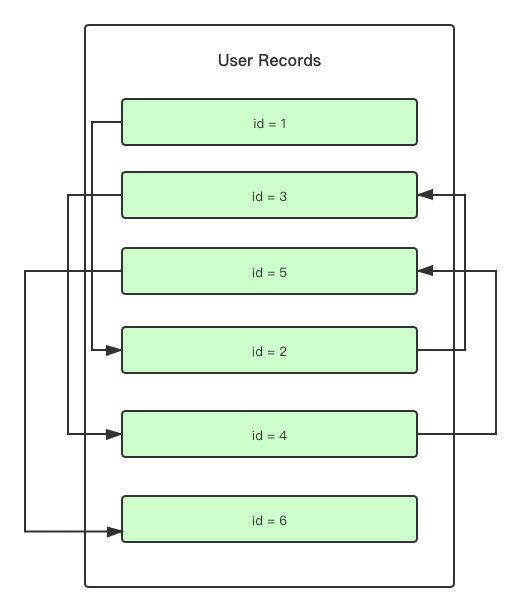
可以理解为数组和链表的区别。
看到这,那么问题来了,说好的不遍历呢?这不是打脸吗?因为从上图可以看出,我要找查找某个数据是否存在于当前的页(Pages)中,只能从头开始遍历这个单向链表。
就这?还敢号称高性能?当然,InnoDB 肯定不是这么搞的。这下就需要从「其余字段」中取出一部分字段了来解释了。
Infimum 和 Supremum分别代表当前页(Pages)中的最大和最小的记录。
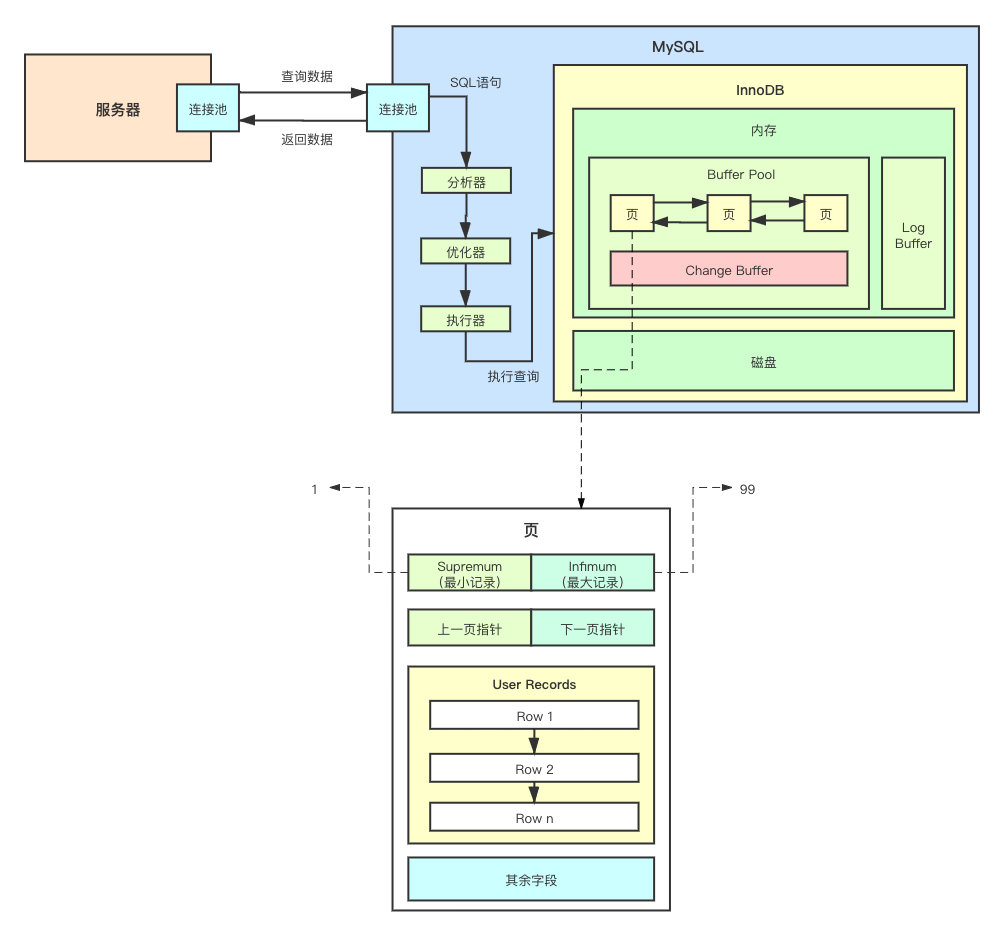
可以看到,有了 Infimum 和 Supremum,我们不需要再去遍历 User Records 就能够知道,要找的数据是否在当前的页中,大大的提升了效率。
但其实还是有问题,比如我需要查询的数据不在当前页中还好,那如果在呢?那是不是还是逃不了 O(N) 的链表遍历呢?算不算治标不治本?
这个时候,我们又需要从「其余字段」中抽一个概念出来了。
Page Directory顾名思义,这玩意儿是个「目录」,可以看下图。
!
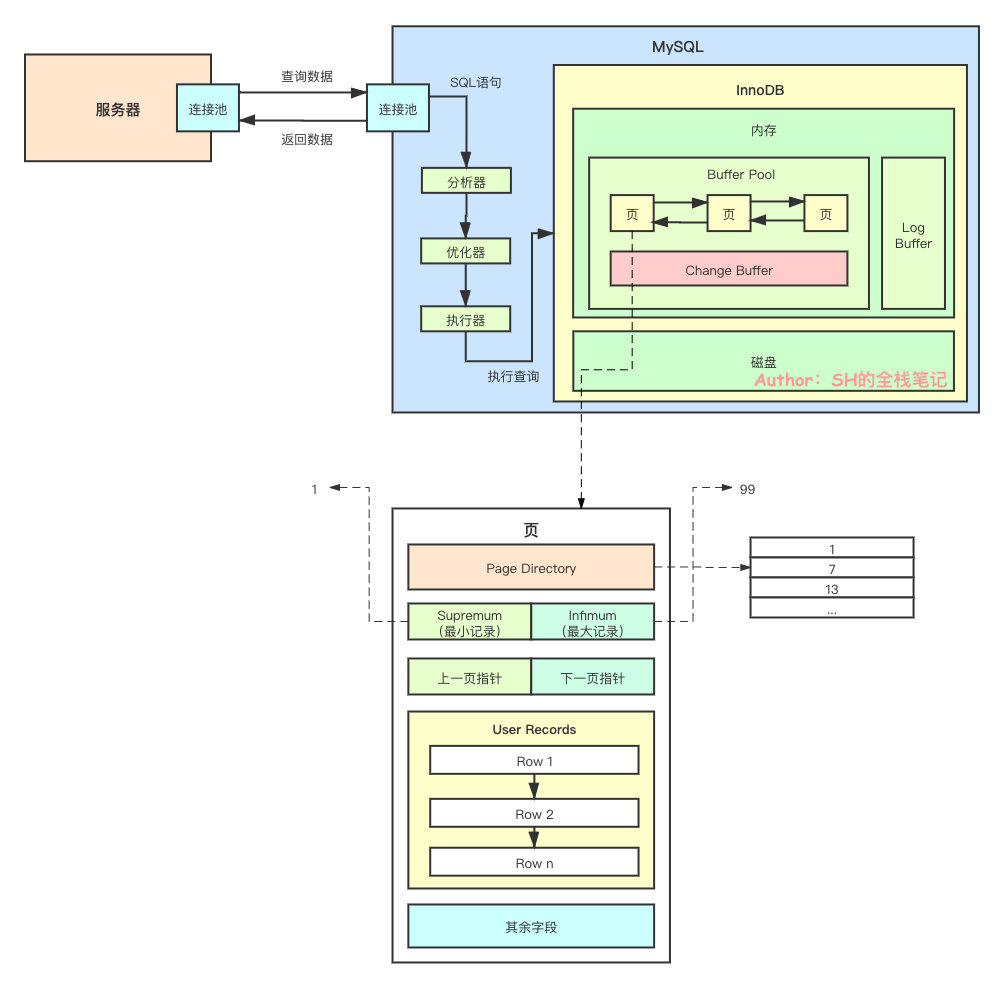
可以看到,每隔一段记录就会在 Page Directory 中有个记录,这个记录是一个指向 User Records 中记录的一个指针。
不知道这个设计有没有让你想起跳表(Skip List)。那这个 Page Directory 中的目录拿来干嘛呢?
有了 Page Directory,就可以对一页中的数据进行类似于跳表的中的查询。在 Page Directory 中找到对应的「位置」之后,再根据指针跳到对应的 User Records 上的单链表,进行查询。如此一来就避免了遍历全部的数据。
上面提到的「位置」,其实有个专业的名词叫「槽位(Slots)」。每一个槽位的数据都是一个指向了 User Records 某条记录的指针。
当我们新增每条数据的时候,就会同步的对 Page Directory 中的槽位进行维护。InnoDB 规定每隔 6 条记录就会创建一个 Slot。
了解到这里之后,关于如何高效地在 MySQL 查询数据就已经了解的差不多了。