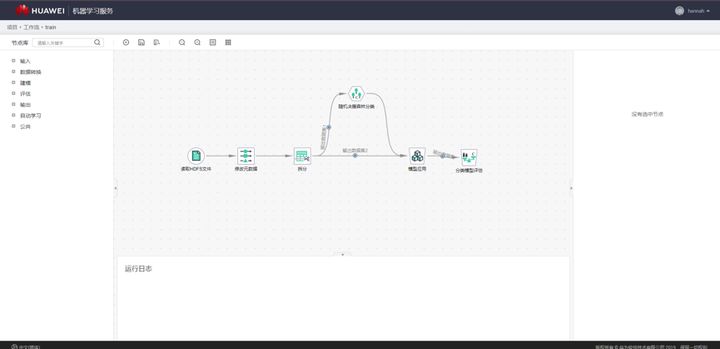
数据规整后,通常需要对数据集进行切分。当数据量比较大的时候,可以切分出训练集、验证集与测试集,直接使用训练集训练模型,用验证集确定最佳的模型参数,用测试集评估模型性能;当数据量较小的时候,通常不切割出专门的验证集,而采用交叉验证的方式确定模型参数,以确保模型得到充分的训练。信用卡申请欺诈检测数据,往往总量特别大,但其中真正发生了欺诈行为的数据却很少,即存在非常严重的数据不均衡问题。因此,在数据集切分过程中,要确保欺诈类的数据能够以一定比例进入到各个数据集中。下面这张截图包含数据分割算子的平台。
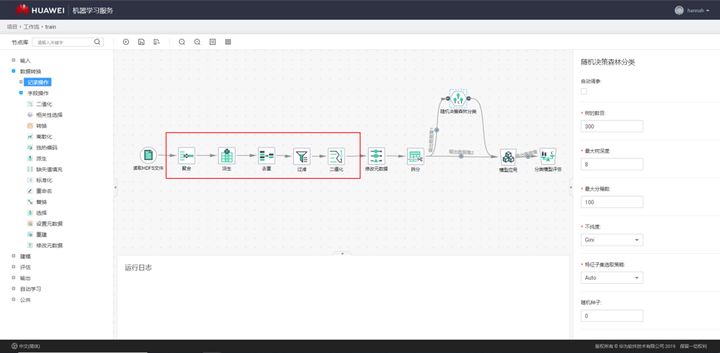
数据处理完成后,便进入了复杂精巧的特征工程阶段。在传统的机器学习类项目中,数据处理和特征工程具有极高的地位,甚至有人提出数据和特征决定了机器学习的上限,而算法和模型不过是逼近这一上限而已。在我们的实践中,数据处理和特征工程的整个过程至少占据了整个项目的百分之七十以上的开发人力,通常还需要在建模过程中回过头对特征进行反复打磨。下面这张图是特征工程工作流截图。
终于,用于建模的数据准备好了,我们可以开始进行高大上的建模工作了。我更乐意把这个过程叫成模型工程,涵盖了模型选择、模型训练、模型评估和模型推理等子过程。模型选择的过程,通常既要用到很多机器学习的基本功,又需要对数据、业务等有深刻理解,还可能需要一定的建模经验(别人的经验也是经验)。
我们知道,机器学习任务通常可以根据数据集是否有标签而划分为有监督、无监督或半监督等类别,根据预测的数据是离散值还是连续值又可以划分为分类问题和回归问题两类。对于信用卡申请欺诈检测这个问题而言,最简单的处理方式就是把它当成有监督的二分类问题,即我们只需要判断用户发起的一个申请是或不是欺诈申请。现在我们用得比较多的是LGBM、XGBoost、RF等,如下图所示。
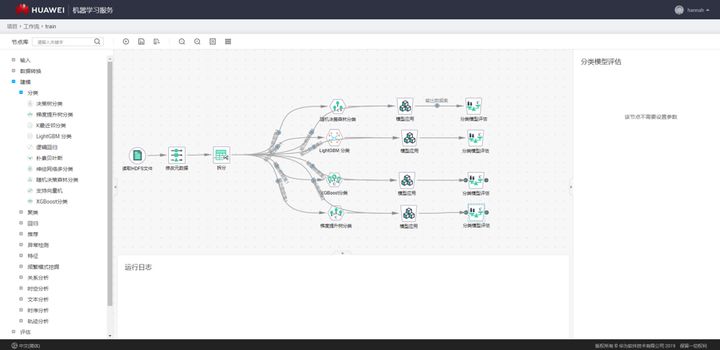
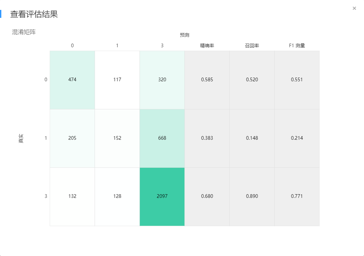
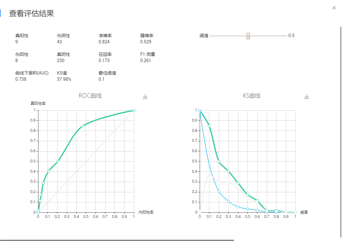
模型选定后,就进入模型训练、推理和评估的过程了。模型的训练过程就是要把准备好的训练数据喂给模型,让模型以参数等形式学习到数据中蕴含的规律和规则等。通常,在这个过程中,你要设置好模型需要的各类超参数。现在各类开源的机器学习库、便捷易用的机器学习平台俯拾皆是,大部分情况下,我们并不需要从零开始构建一个机器学习模型,只简单地做个“调包侠”调一下各种开源机器学习包或者在机器学习平台上拖拽几个算子即可。模型推理的过程很好理解,就是把测试集中的数据喂进训练好的模型中,让模型预测出结果即可。比如对于信用卡申请欺诈检测问题而言,就是将待预测的数据丢进模型中,由模型给出每一条数据对应的预测结论。模型评估过程则是通过各类指标对预测结果进行评估,度量预测结果与真实结果之间的差距。对于分类问题而言,常见的有精确率、准确率、召回率、F1值等度量指标,对于回归问题而言,常见的有MAE、MSE等度量指标。