
这是why的第86篇原创文章

在早期文章里面我曾经写过布隆过滤器:
哎,这糟糕透顶的排版,一言难尽.......
其实写文章和写代码一样。
看到一段辣眼睛的代码,正想口吐芬芳:这是哪个煞笔写的代码?
结果定睛一看,代码上写的作者居然是自己。
甚至还不敢相信,还要打开看一下 git 的提交记录。
发现确实是自己几个月前亲手敲出来,并且提交的代码。
于是默默的改掉。
出现这种情况我也常常安慰自己:没事,这是好事啊,说明我在进步。
好了,说正事。
当时的文章里面我说布隆过滤器的内部原理我说不清楚。
其实我只是懒得写而已,这玩意又不复杂,有啥说不清楚的?

布隆过滤器,在合理的使用场景中具有四两拨千斤的作用,由于使用场景是在大量数据的场景下,所以这东西类似于秒杀,虽然没有真的落地用过,但是也要说的头头是道。
常见于面试环节:比如大集合中重复数据的判断、缓存穿透问题等。
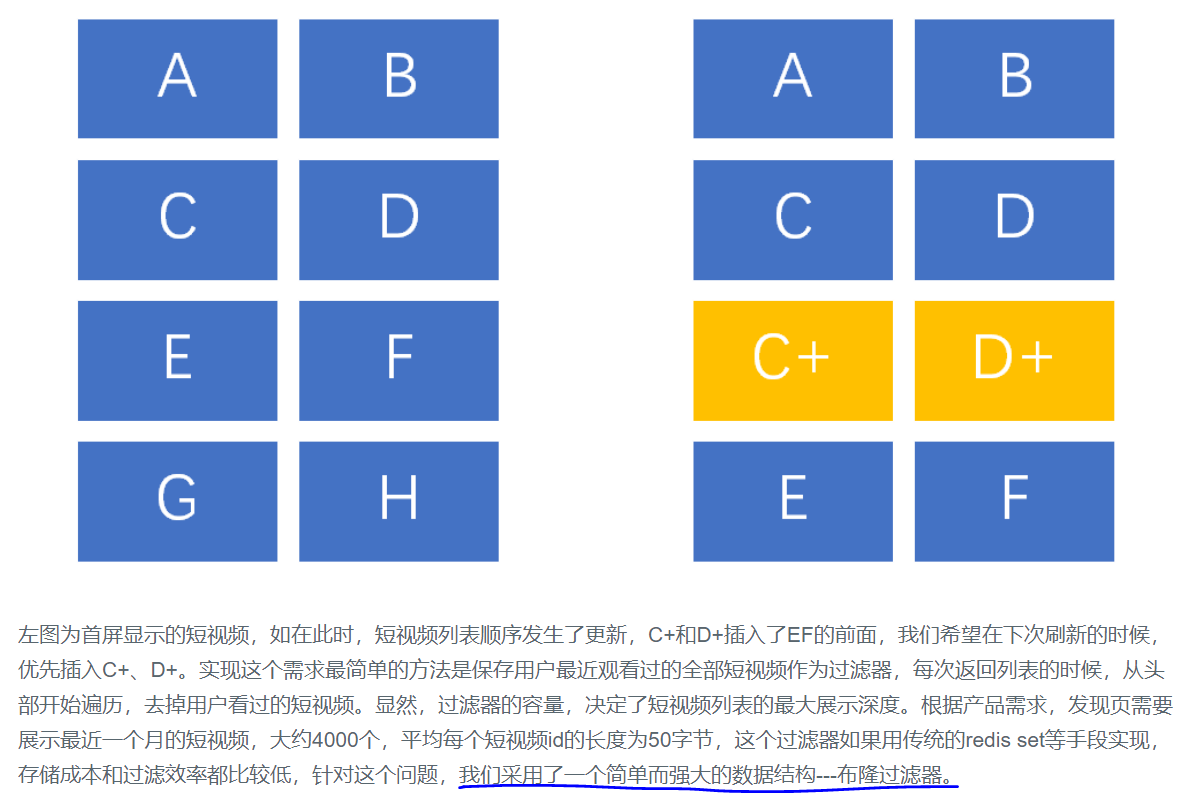
先分享一个布隆过滤器在腾讯短视频产品中的真实案例:
https://toutiao.io/posts/mtrvsx/preview
首先,布隆过滤器并不存储原始数据,因为它的功能只是针对某个元素,告诉你该元素是否存在而已。并不需要知道布隆过滤器里面有哪些元素。
当然,如果我们知道容器里面有哪些元素,就可以知道一个元素是否存在。
但是,这样我们需要把出现过的元素都存储下来,大数据量的情况下,这样的存储就非常的占用空间。
布隆过滤器是怎么做到不存储元素,又知道一个元素是否存在呢?
说破了其实就很简单:一个长长的数组加上几个 Hash 算法。
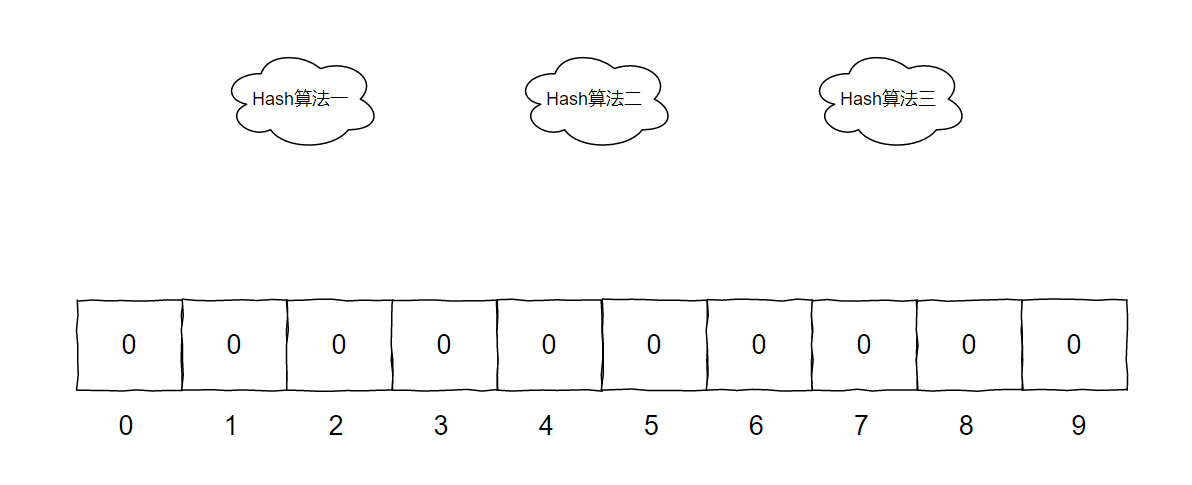
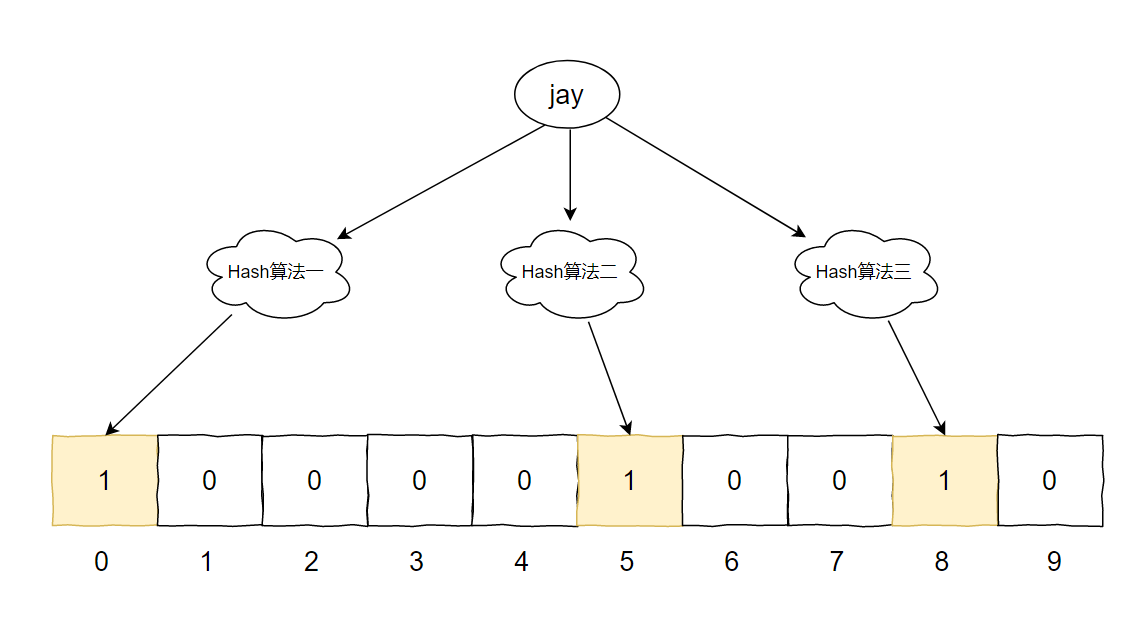
在上面的示意图中,一共有三个不同的 Hash 算法、一个长度为 10 的数组,数组里面存储的是 bit 位,只放 0 和 1。初始为 0。
假设现在有一个元素 [why] ,要经过这个布隆过滤器。
首先 [why] 分别经过三个 Hash 算法,得出三个不同的数字。
Hash 算法可以保证得出的数字是在 0 到 9 之间,即不超过数组长度。
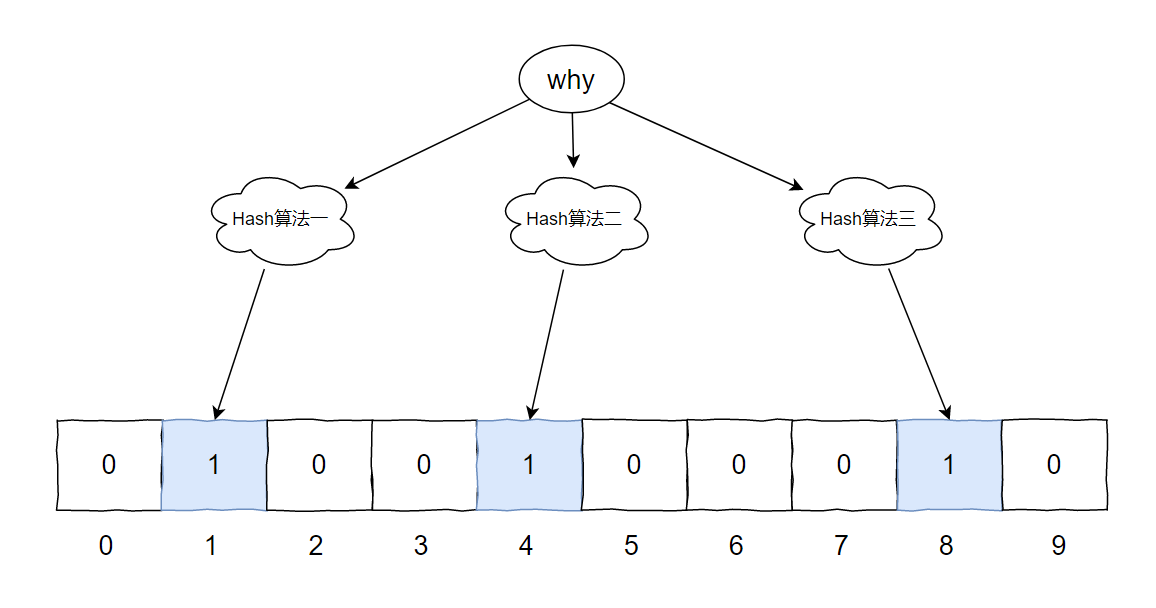
我们假设计算结果如下:
Hash1(why)=1
Hash2(why)=4
Hash3(why)=8
对应到图片中就是这样的:
这时,如果再来一个元素 [why],经过 Hash 算法得出的下标还是 1,4,8,发现数组对应的位置上都是 1。表明这个元素极有可能出现过。
注意,这里说的是极有可能。也就是说会存在一定的误判率。
我们先再存入一个元素 [jay]。
Hash1(jay)=0
Hash2(jay)=5
Hash3(jay)=8
此时,我们把两个元素汇合一下,就有了下面这个图片:
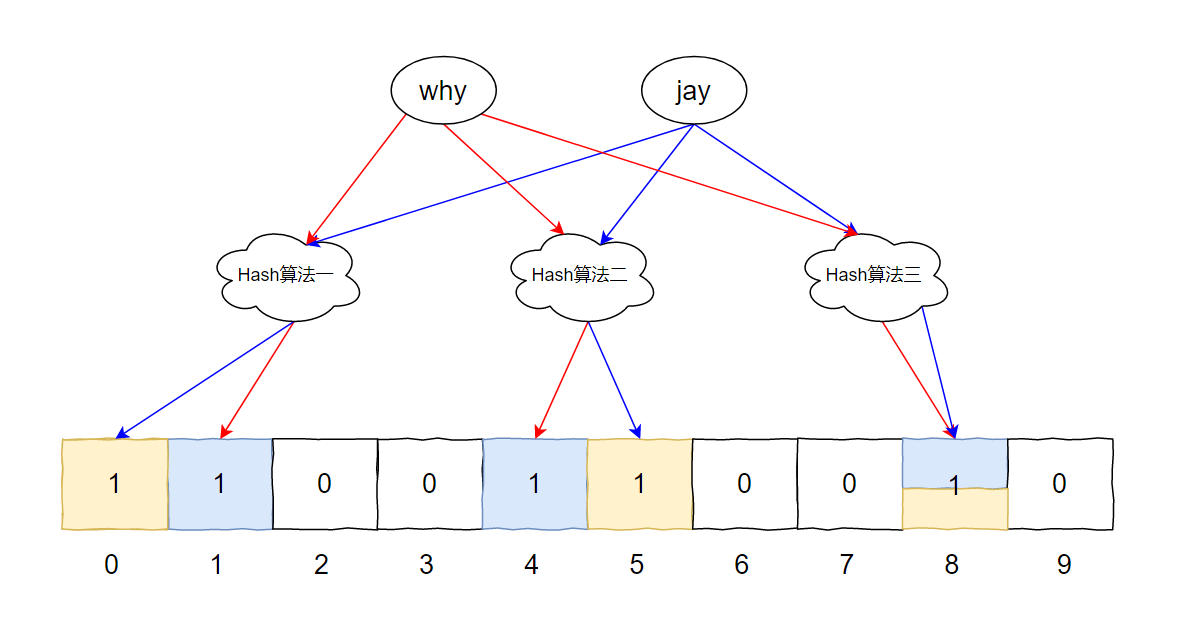
其中的下标为 8 的位置,比较特殊,两个元素都指向了它。
这个图片这样看起来有点难受,我美化一下:
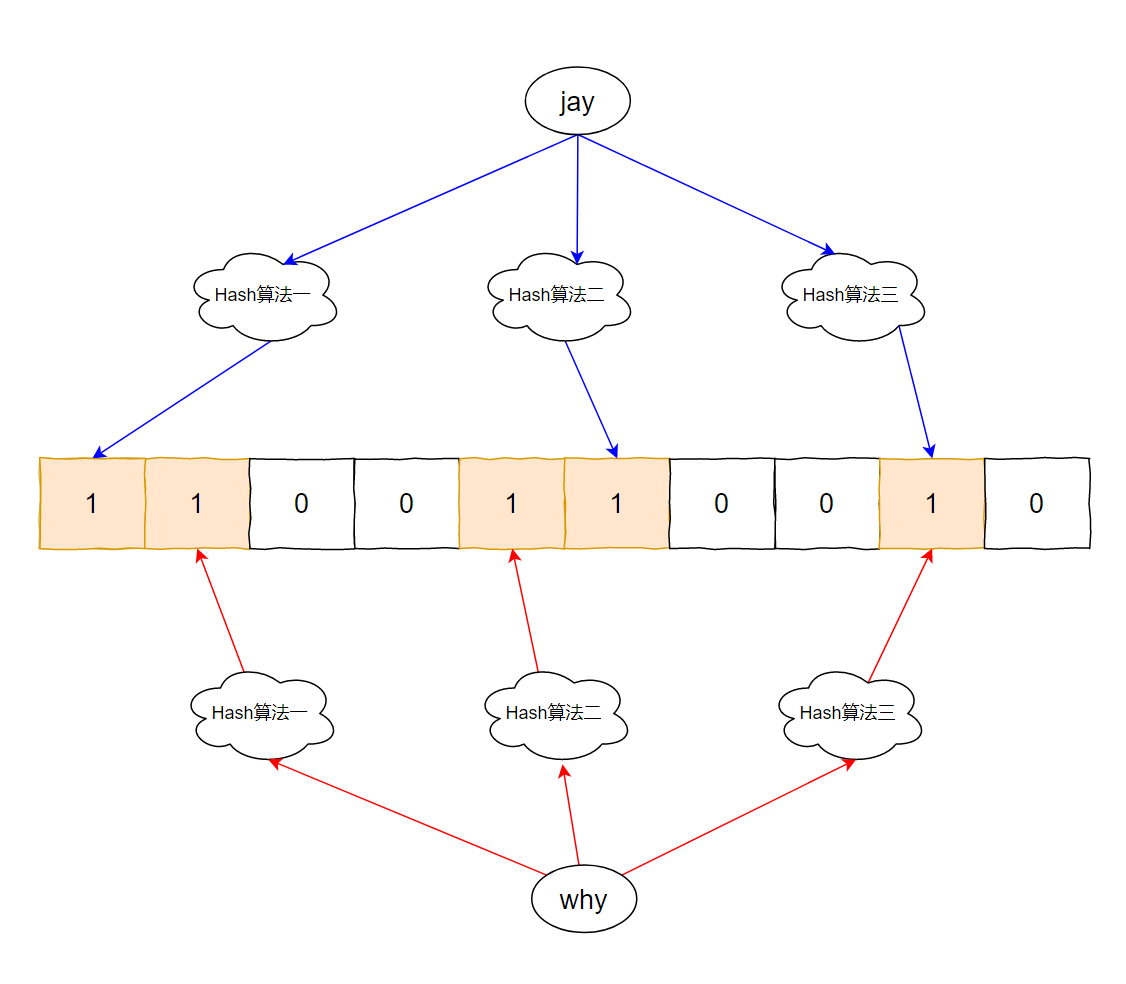
好了,现在这个数组变成了这样:

你说,你只看这个玩意,你能知道这个过滤器里面曾经有过 why 和 jay 吗?
别说你不知道了,就连过滤器本身都不知道。
现在,假设又来了一个元素 [Leslie],经过三个 Hash 算法,计算结果如下:
Hash1(Leslie)=0
Hash2(Leslie)=4