
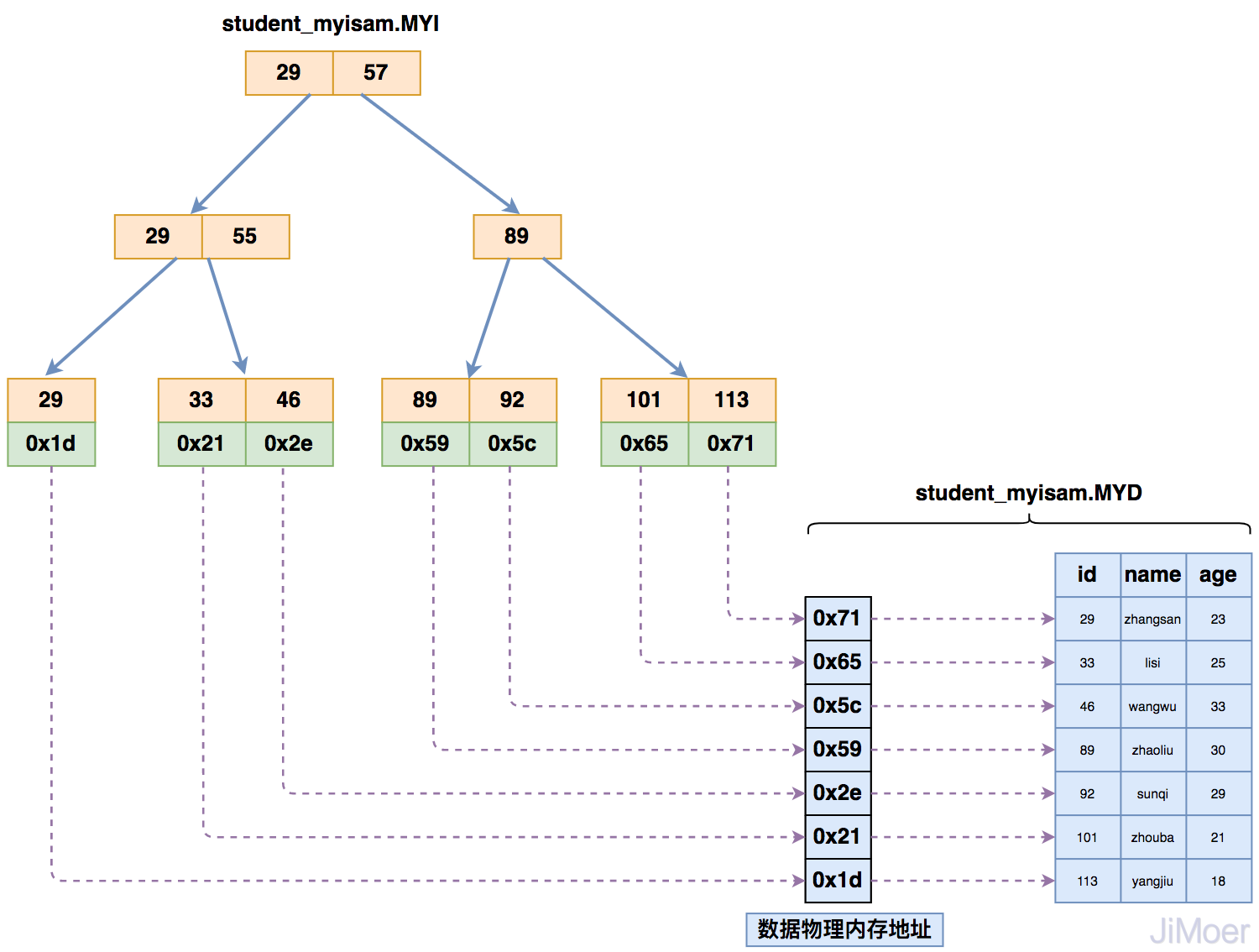
那么当存在多个索引时,多个索引都指向相同的物理地址。
如下图所示:
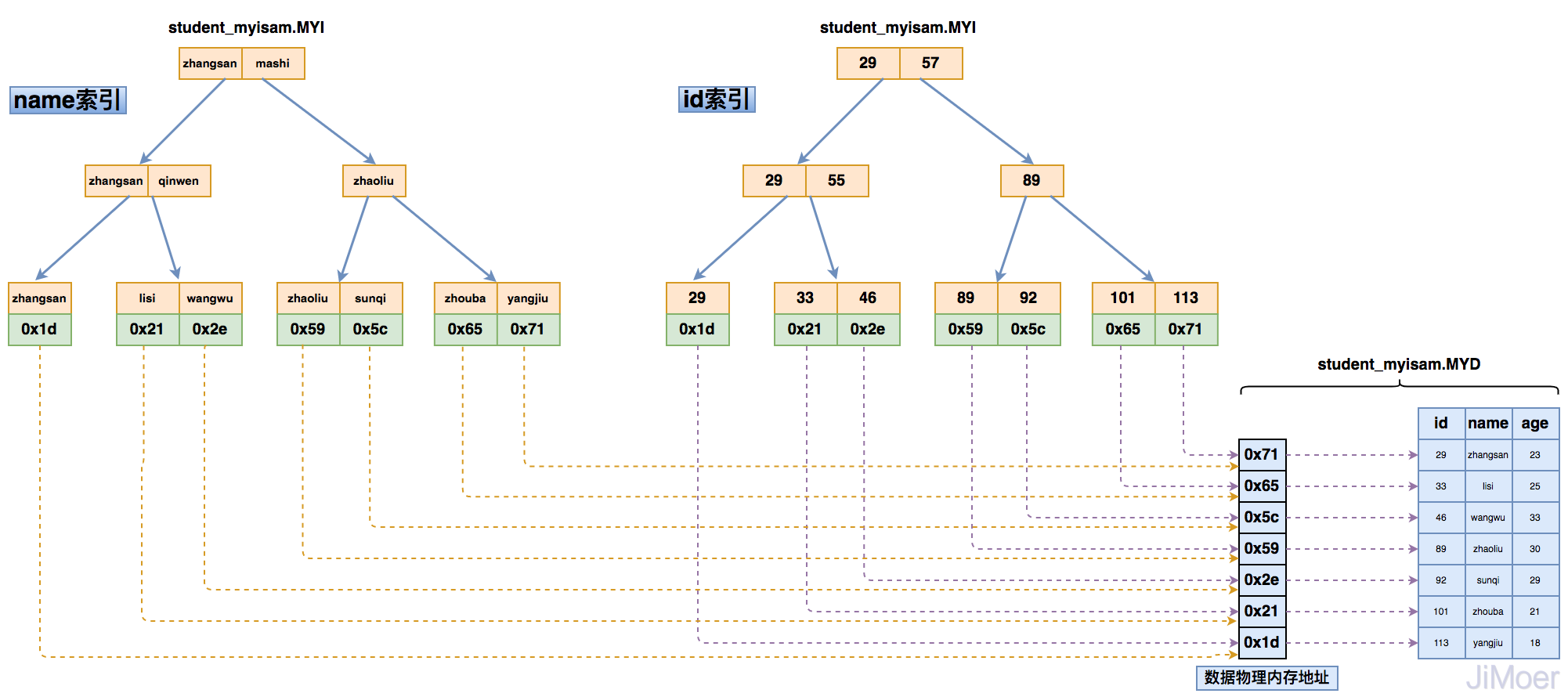
通过这个结构,我们可以看出来,MyISAM的存储引擎的索引都是同级别的,主键和非主键索引结构和查询方式完全一样。 InnoDB数据存储引擎,索引与数据的存储结构
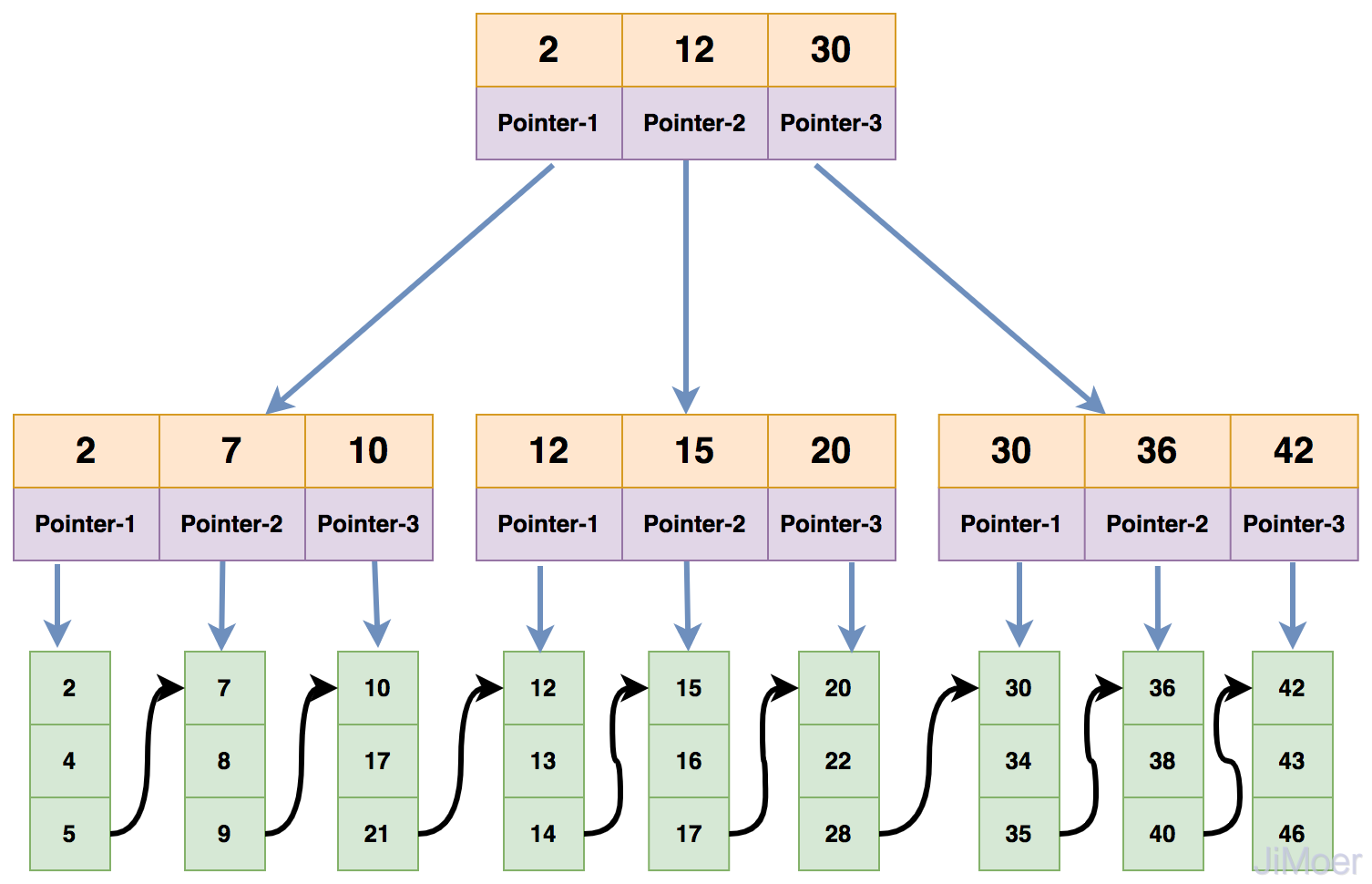
首先InnoDB的索引分为聚簇索引和非聚簇索引,聚簇索引即保存关键字又保存数据,在B+Tree的每个分支节点上保存关键字,叶子节点上保存数据。
“聚簇”的意思是数据行被按照一定顺序一个个紧密地排列在一起存储。一个表只能有一个聚簇索引,因为在一个表中数据的存放方式只有一种,一般是主键作为聚簇索引,如果没有主键,InnoDB会默认生成一个隐藏的列作为主键。
如下图所示:
非聚簇索引,又称为二级索引,虽然也是在B+Tree的每个分支节点上保存关键字,但是叶子节点不是保存的数据,而是保存的主键值。通过二级索引去查询数据会先查询到数据对应的主键,然后再根据主键查询到具体的数据行。
如下图所示:
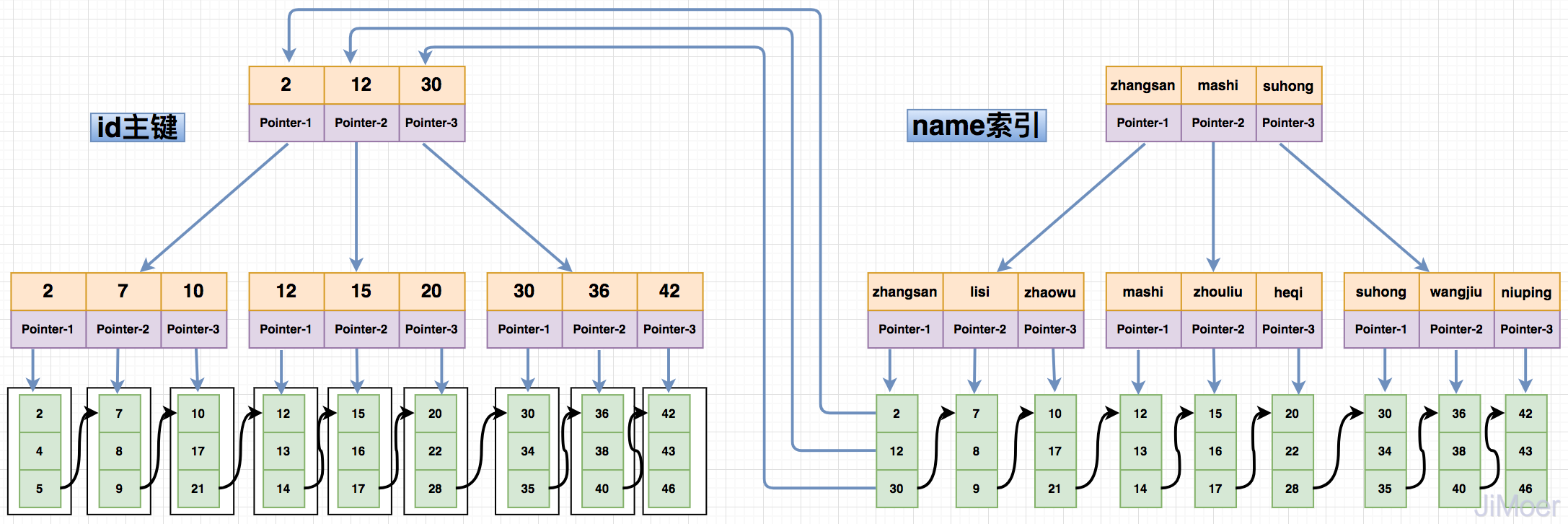
由于非聚簇索引的设计结构,导致了,非聚簇索引在查询的时候要进行两次索引检索,这样设计的好处,可以保证了一旦发生数据迁移的时候,只需要更新主键索引即可,非聚簇索引并不用动,而且也规避了像MyISAM的索引那样存储物理地址,在数据迁移的时候的需要重新维护所有索引的问题。 总结
这次把MySQL的索引的数据结构,以及文件存储结构,总结清楚了,后面在实际的工作过程中,设计索引的时候能够考虑的更全了,通过了解了索引的数据结构,也能让自己在实际写SQL的时候,能考虑到哪些情况走索引哪些不走索引了。
MySQL使用B+Tree作为索引的数据结构,因为B+Tree的深度低,节点保存的关键字多,磁盘IO次数少,从而保证了查询效率更高。
B+Tree能够保证MySQL无论是主键索引还是非主键索引的查询效果都是稳定的,每次都要查询到叶子节点才能返回数据,B+Tree的叶子节点的深度是一样的,而且为了更好的支持自增主键,B+Tree的查询节点范围是左闭合右开放。
MySQL的MyISAM存储引擎,表数据和索引数据是分别放到两个文件中进行存储的,由于它本身的索引的B+Tree的叶子节点指向的表数据所在的磁盘地址,而且索引没有主键和非主键之分,所以分开存储,能够更好的统一管理索引;
MySQL的InnoDB存储引擎,表数据和索引数据是存储在一个文件中的,因为InnoDB的聚簇索引的叶子节点指向的具体的数据行,而且为了保证查询效果的稳定,InnoDB表中必须要有一个聚簇索引,二级索引在进行索引检索时,会先通过二级索引检索到数据的主键值,再根据主键去聚簇索引中检索到具体的数据。