
这篇文章的题目,是我真实在面试过程中遇到的问题,某互联网众筹公司在考察面试者MySQL相关知识的第一个问题,我当时还是比较懵的,没想到这年轻人不讲武德,不按套路出牌,一般的问MySQL的相关知识的时候,不都是问索引优化以及索引失效等相关问题吗?怎么还出来了,存储文件的不同?哪怕考察个MVCC机制也行啊。所以这次我就好好总结总结这部分知识点。
为什么需要建立索引首先,我们都知道建立索引的目的是为了提高查询速度,那么为什么有了索引就能提高查询速度呢?
我们来看一下,一个索引的示意图。

如果我有一个SQL语句是:select * from Table where id = 15 那么在没有索引的情况下其实是会进行全表扫描的,就是挨个去找,直到找到id=15的这条记录,时间复杂度是O(n);
如果在有索引的情况下去进行查询呢。首先会根据id=15,在索引值里面进行二分查找,二分查找的效率是很高的,它的时间复杂度是O(logn);
这就是索引为什么能提高查询效率了,但是索引数据的量也是比较大的,所以一般并不是存储在内存中的,都是直接存储在磁盘中的,所以对磁盘中的文件内容进行读取,免不了要进行磁盘IO。
MySQL的索引为什么使用B+Tree上面我们也说了,索引数据一般是存储在磁盘中的,但是计算数据都是要在内存中进行的,如果索引文件很大的话,并不能一次都加载进内存,所以在使用索引进行数据查找的时候是会进行多次磁盘IO,将索引数据分批的加载到内存中,因此一个好的索引的数据结构,在得到正确的结果前提下,一定是磁盘IO次数最少的。
Hash类型目前MySQL其实是有两种索引数据类型可以选择的,一个是BTree(实际是B+Tree)、一个Hash。
但是为什么在实际的使用过程中,基本上大部分都是选择BTree呢?
因为如果使用Hash类型的索引,MySQL在创建索引的时候,会对索引数据进行一次Hash运算,这样根据Hash值就能快速的定位到磁盘指针了,就算数据量很大,也能快速精准的定位到数据。
但是像select * from Table where id > 15这种范围查询,Hash类型的索引就搞不定了,对这种范围查询,会直接全表扫描,另外Hash类型的索引也搞不定排序。
还有就是虽然MySQL底层做了一系列的处理,但还是不能完全的保证,不产生Hash碰撞。
二叉树那MySQL为什么没有二叉树作为它的索引数据结构呢?我们都知道,二叉树是通过二分查找来进行定位数据的,所以效果还是不错的,时间复杂度是O(logn);
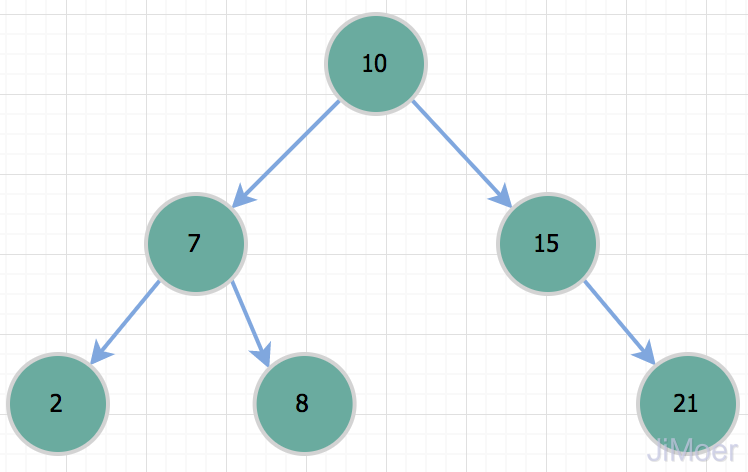
但是二叉树有个问题,就是在特殊情况下,它会退化成一根棍子,也就是一个单向链表。这个时候,它的时间复杂度就会退化成O(n);
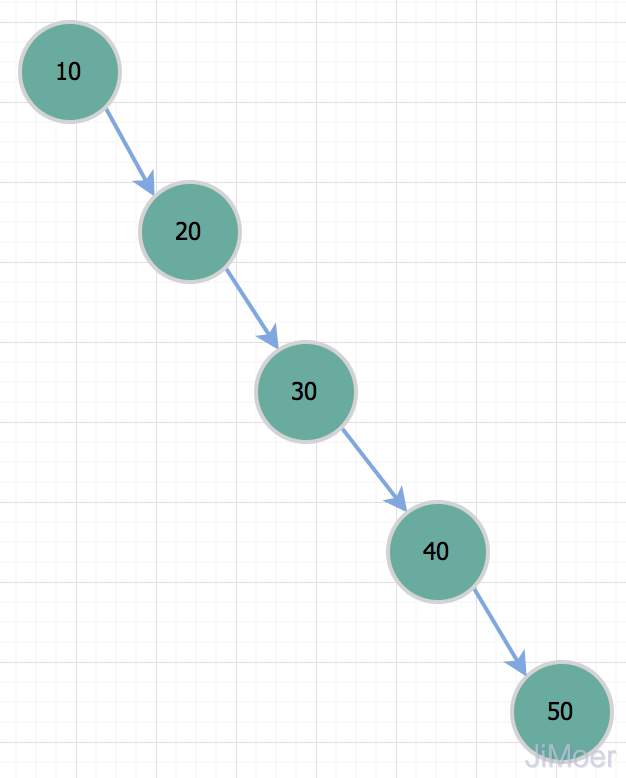
所以当我们要查询id=50的记录时,其实和全表扫描是一样的了。所以因为存在这种情况,二叉树不适合作为索引的数据结构。 平衡二叉树
那么既然二叉树,在特殊情况下会退化成链表,那么平衡二叉树为什么不可以呢?
平衡二叉树的子节点高度差不能超过1,像下图中的二叉树,关键字为15的节点,它的左子节点高度为0,右子节点高度为1,高度差不超过1,所以下面这棵树是一棵平衡二叉树。
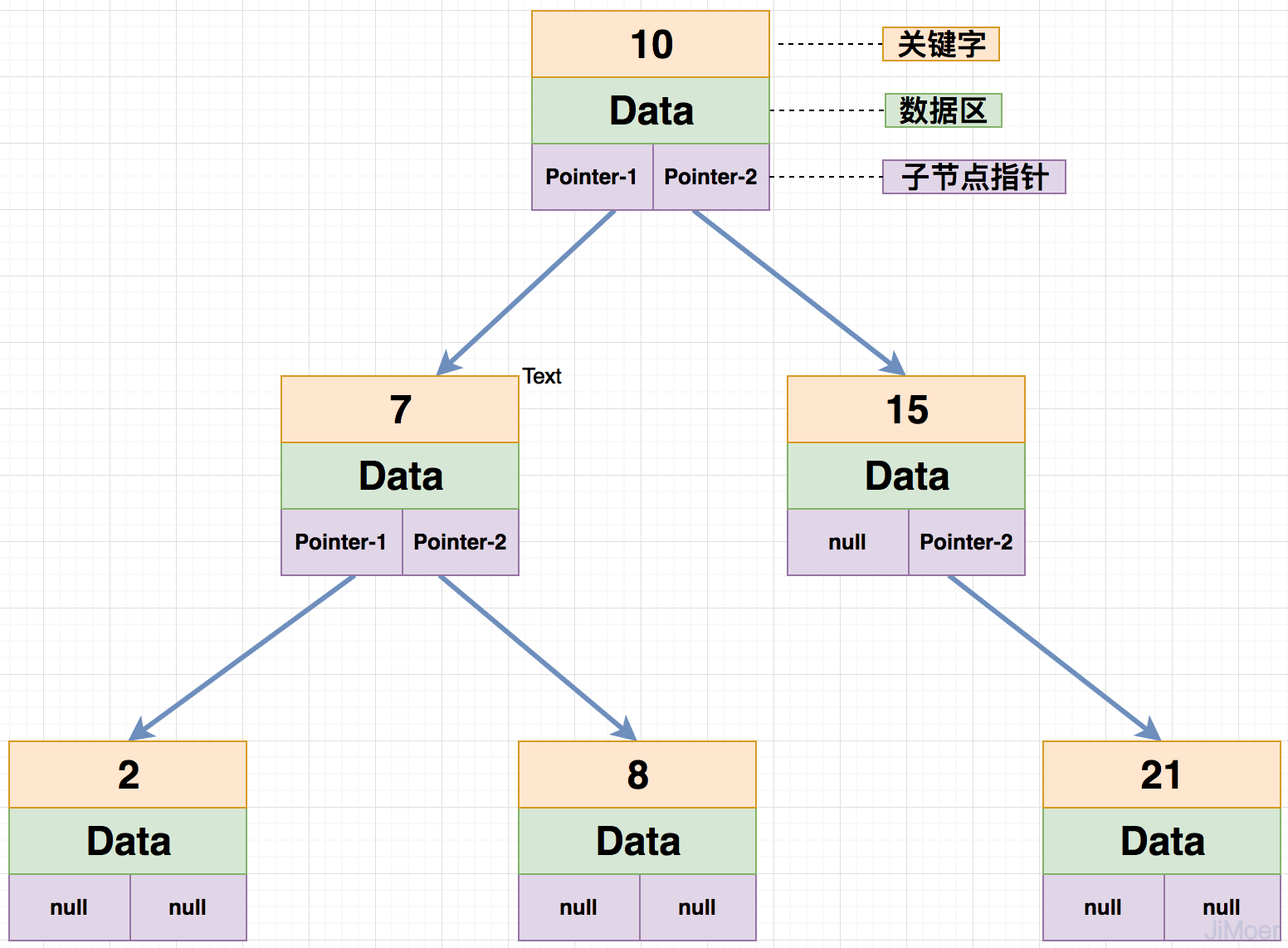
因为能保持平衡,所以它的查询时间复杂度为O(logN),至于怎么保持平衡的,主要是做一些左旋,右旋等,具体保持平衡的细节不是本文主要内容,想了解的可自行搜索。
用这个数据结构来做MySQL的索引会有 什么问题呢?
磁盘IO过多:在MySQL当中,一次IO操作只读取一个节点,那么一个节点若是最多就两个子节点的话,那么就只有这两个子节点的查询范围,所以要精确到具体的数据时,就需要进行多次读取,如果树非常深的话,那么将会进行大量的磁盘IO。性能自然下降了。