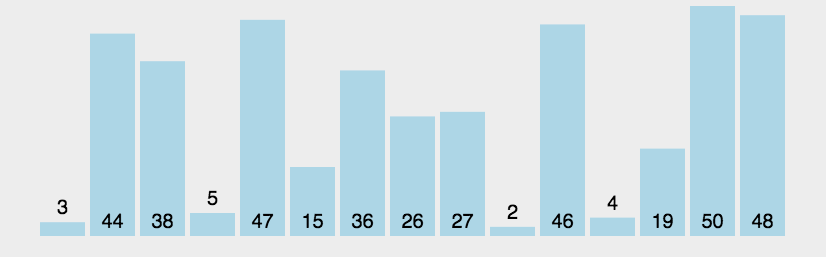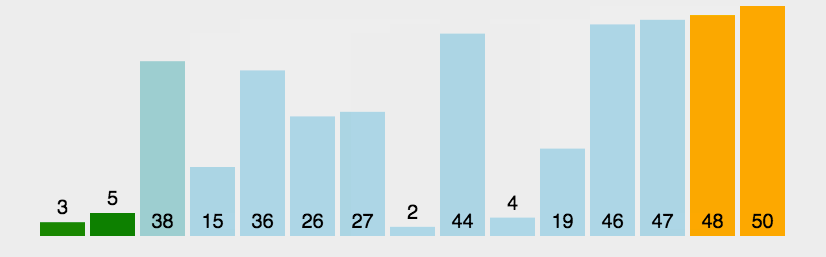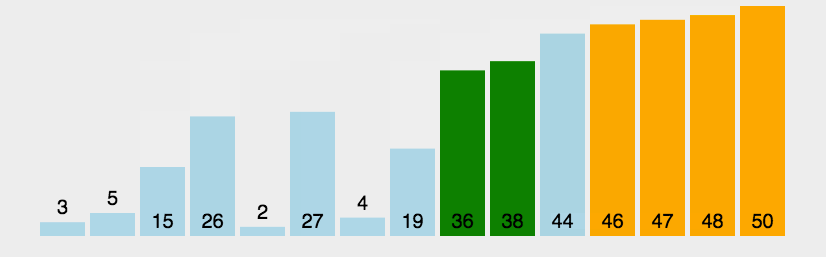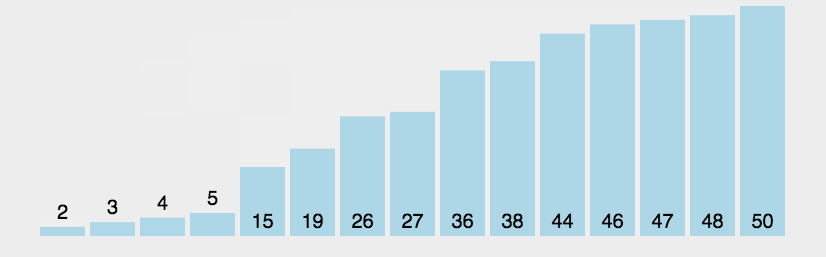所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。排序算法,就是如何使得记录按照要求排列的方法。排序算法在很多领域得到相当地重视,尤其是在大量数据的处理方面。一个优秀的算法可以节省大量的资源。在各个领域中考虑到数据的各种限制和规范,要得到一个符合实际的优秀算法,得经过大量的推理和分析。
两年前,我曾在博客园发布过一篇《十大经典排序算法最强总结(含JAVA代码实现)》博文,简要介绍了比较经典的十大排序算法,不过在之前的博文中,仅给出了Java版本的代码实现,并且有一些细节上的错误。所以,今天重新写一篇文章,深入了解下十大经典排序算法的原理及实现。
简介排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。常见的内部排序算法有:插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序等,本文只讲解内部排序算法。用一张图概括:

图片名词解释:
n:数据规模
k:“桶”的个数
In-place:占用常数内存,不占用额外内存
Out-place:占用额外内存
术语说明稳定:如果A原本在B前面,而A=B,排序之后A仍然在B的前面。
不稳定:如果A原本在B的前面,而A=B,排序之后A可能会出现在B的后面。
内排序:所有排序操作都在内存中完成。
外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行。
时间复杂度: 定性描述一个算法执行所耗费的时间。
空间复杂度:定性描述一个算法执行所需内存的大小。
算法分类十种常见排序算法可以分类两大类别:比较类排序和非比较类排序。
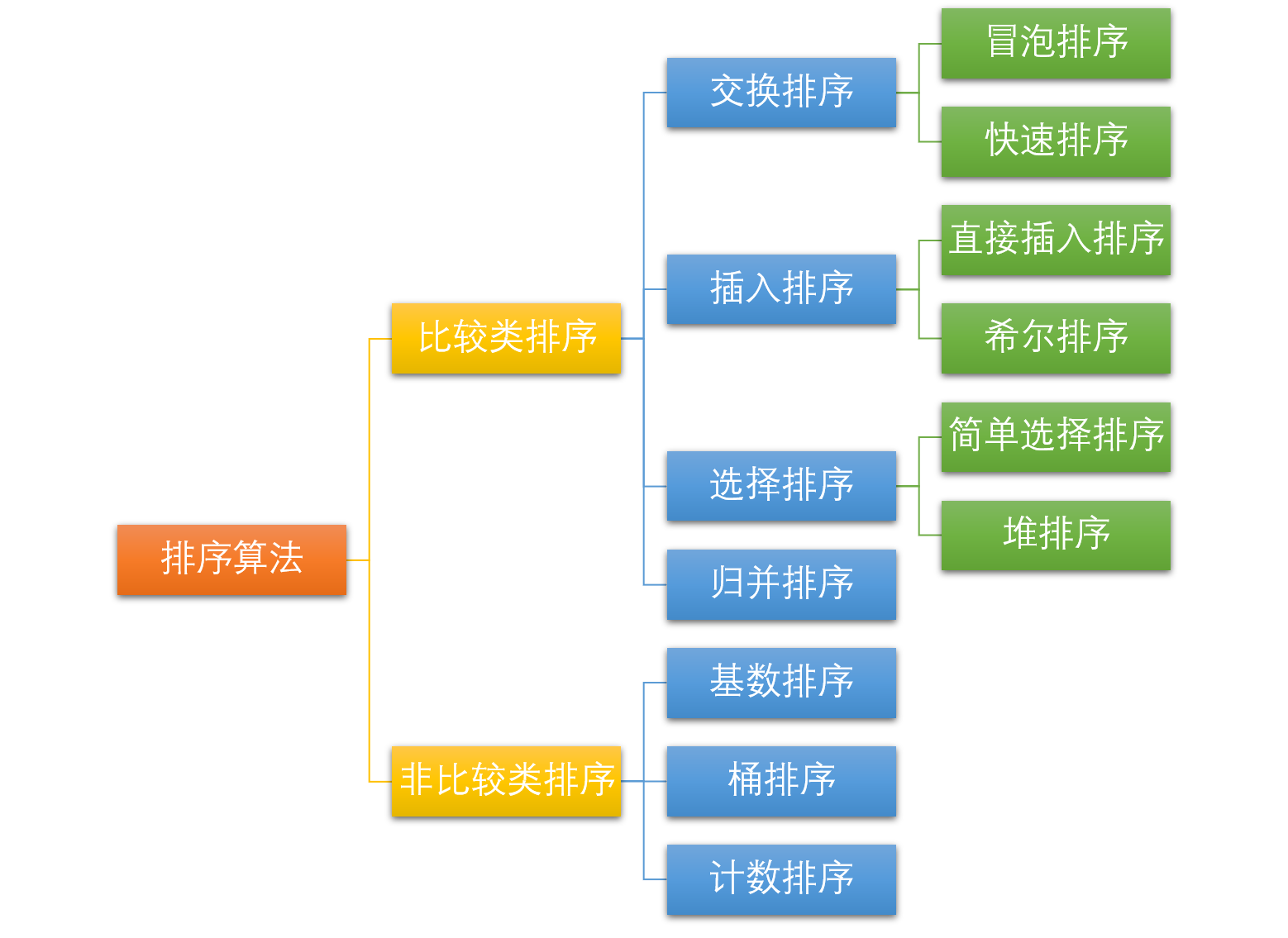
常见的快速排序、归并排序、堆排序以及冒泡排序等都属于比较类排序算法。比较类排序是通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序。在冒泡排序之类的排序中,问题规模为n,又因为需要比较n次,所以平均时间复杂度为O(n²)。在归并排序、快速排序之类的排序中,问题规模通过分治法消减为logn次,所以时间复杂度平均O(nlogn)。
比较类排序的优势是,适用于各种规模的数据,也不在乎数据的分布,都能进行排序。可以说,比较排序适用于一切需要排序的情况。
而计数排序、基数排序、桶排序则属于非比较类排序算法。非比较排序不通过比较来决定元素间的相对次序,而是通过确定每个元素之前,应该有多少个元素来排序。由于它可以突破基于比较排序的时间下界,以线性时间运行,因此称为线性时间非比较类排序。 非比较排序只要确定每个元素之前的已有的元素个数即可,所有一次遍历即可解决。算法时间复杂度O(n)。
非比较排序时间复杂度底,但由于非比较排序需要占用空间来确定唯一位置。所以对数据规模和数据分布有一定的要求。
冒泡排序(Bubble Sort)冒泡排序是一种简单的排序算法。它重复地遍历要排序的序列,依次比较两个元素,如果它们的顺序错误就把它们交换过来。遍历序列的工作是重复地进行直到没有再需要交换为止,此时说明该序列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
算法步骤比较相邻的元素。如果第一个比第二个大,就交换它们两个;
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
针对所有的元素重复以上的步骤,除了最后一个;
重复步骤1~3,直到排序完成。
图解算法