但缺点也显而易见。我们上面用车间来类比进程,用工人来类比线程,显然「建一座车间」比「招聘一个工人」消耗的资源要大得多——哪怕车间只有一个工人——这里比较明显的是对内存的消耗。

为了避免过大的内存消耗,Chrome 把一些服务做了聚合:
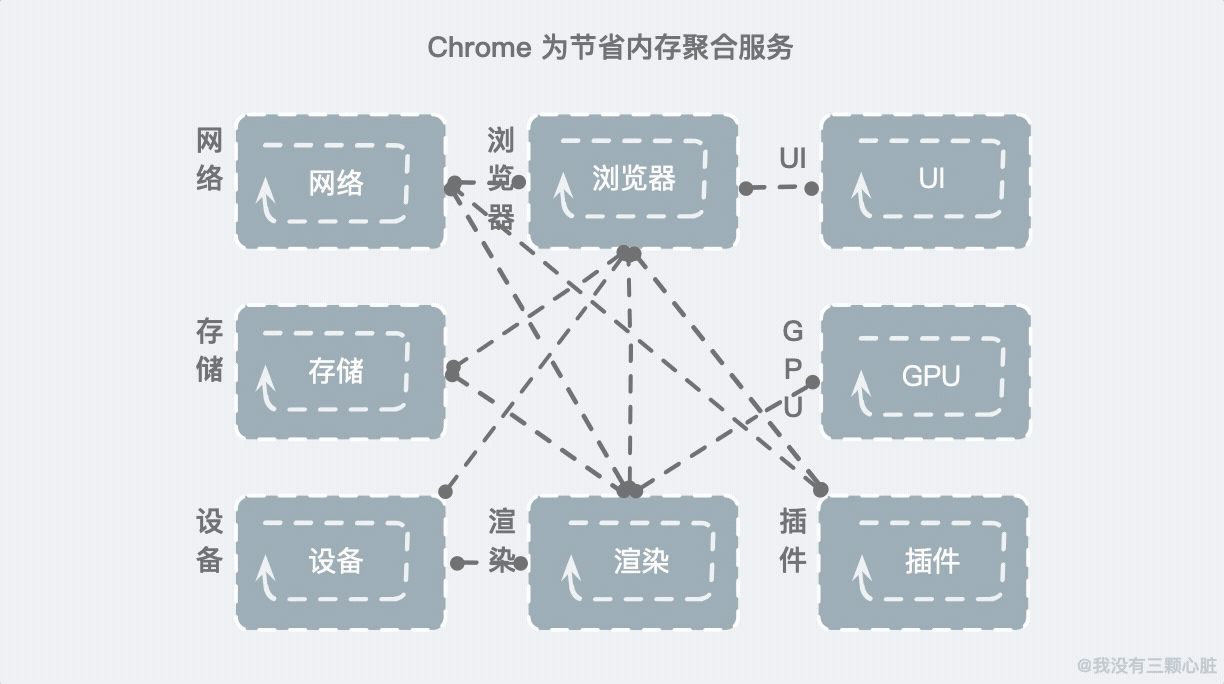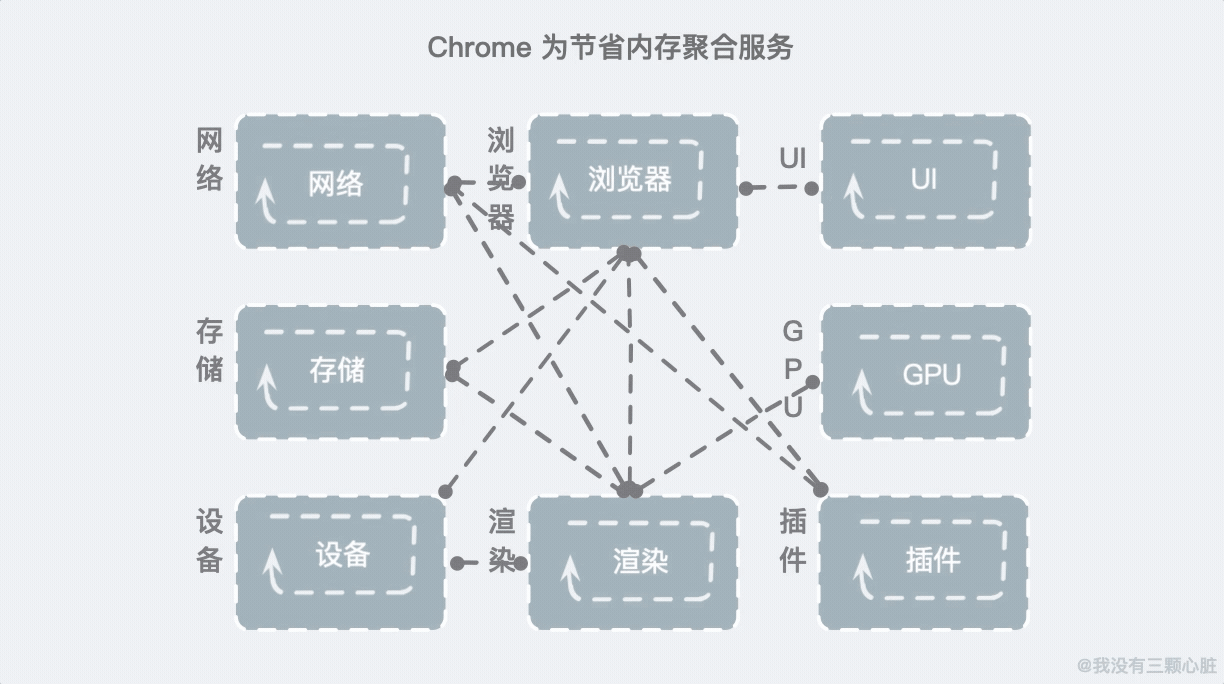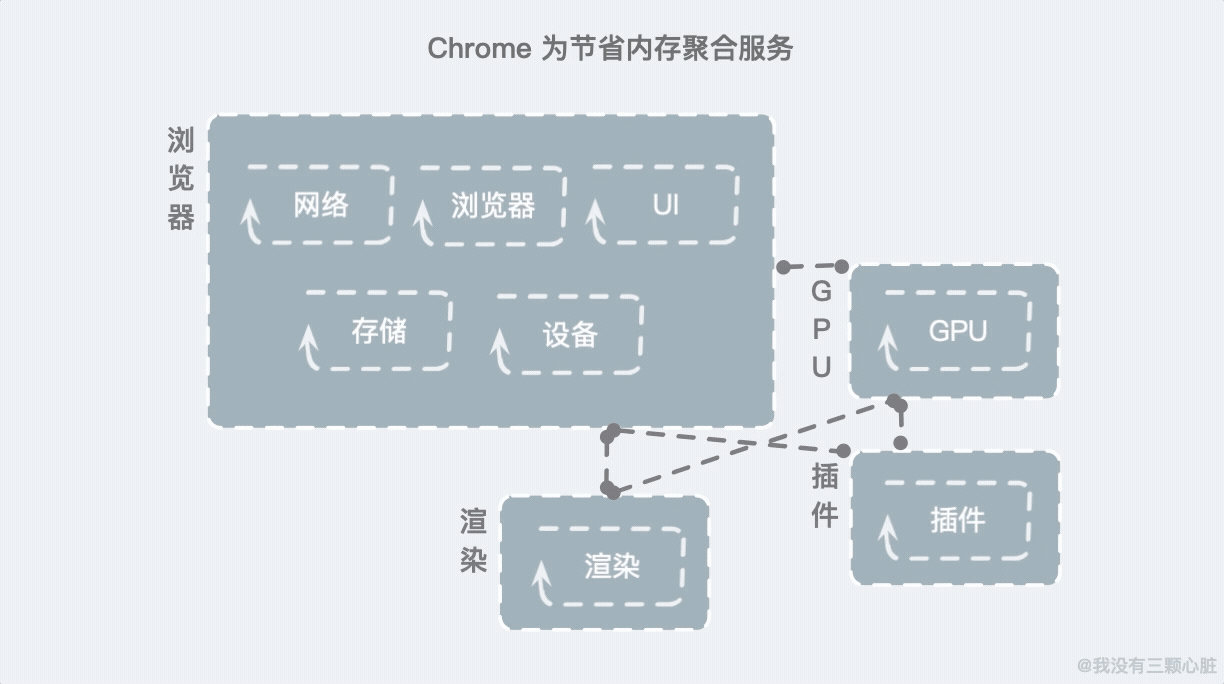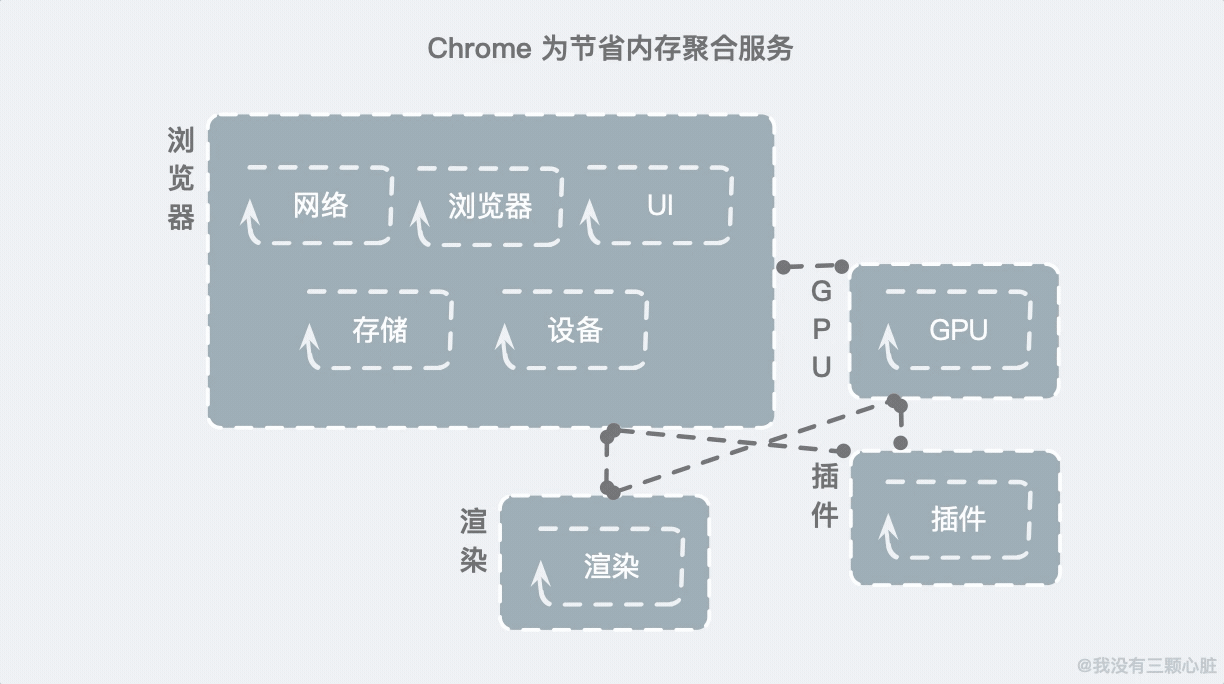
这样就能一定程度上减少内存的开销。
Part 3. 浏览器视角下的输入当在浏览器中键入一个 URL 地址,浏览器会做什么处理呢?

我们已经习惯了一个链接打开就对应一个外部网站,但它还可能是浏览器本身的设置页(如 chrome://settings/),或是本地硬盘的地址(如 Mac 下的 \):

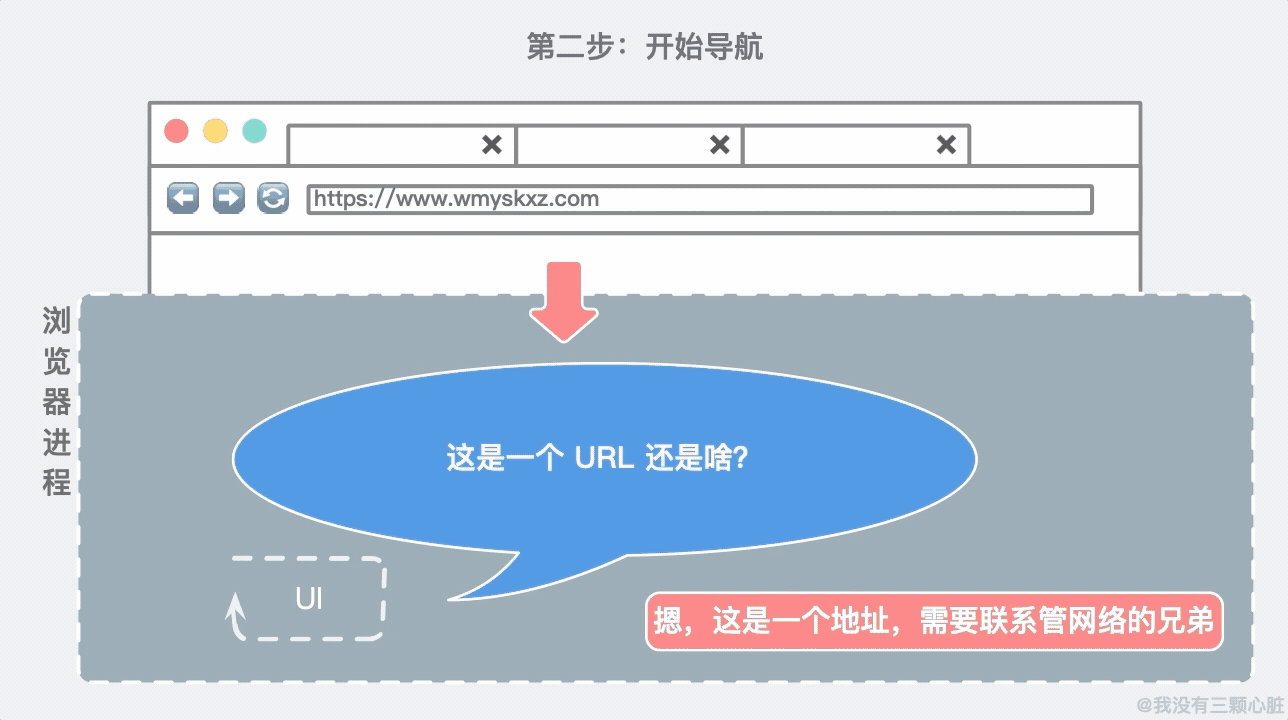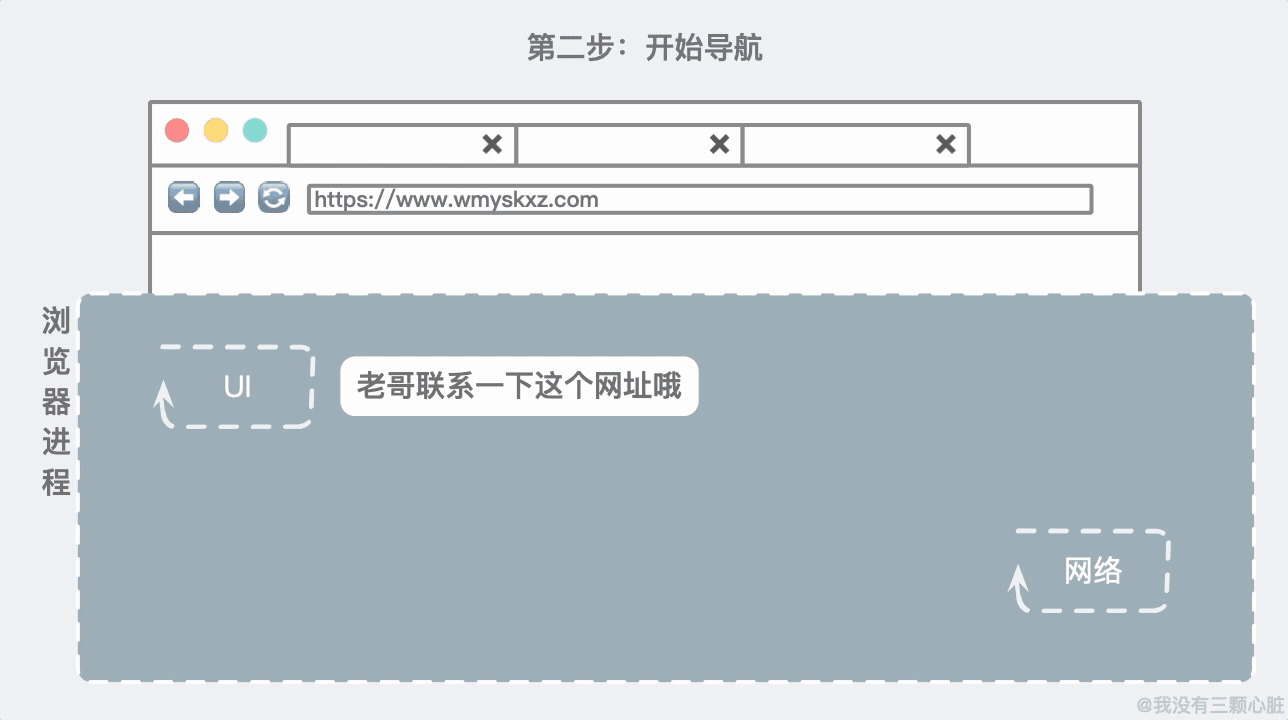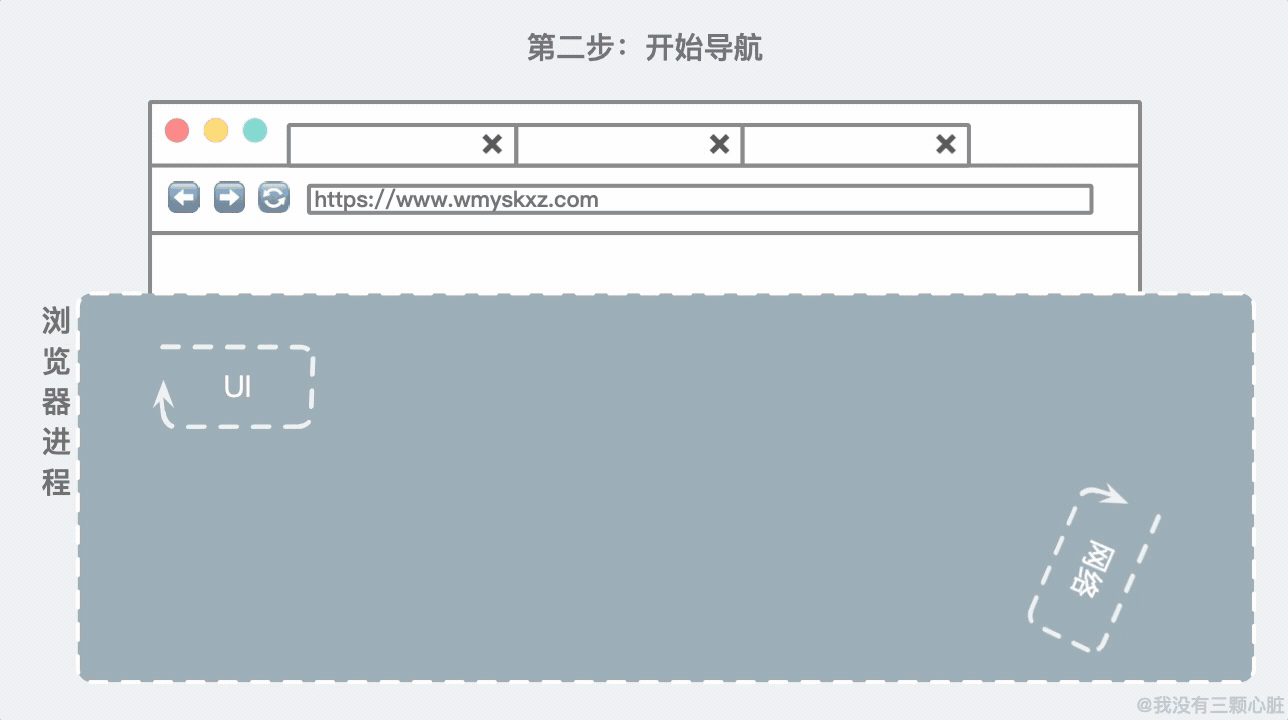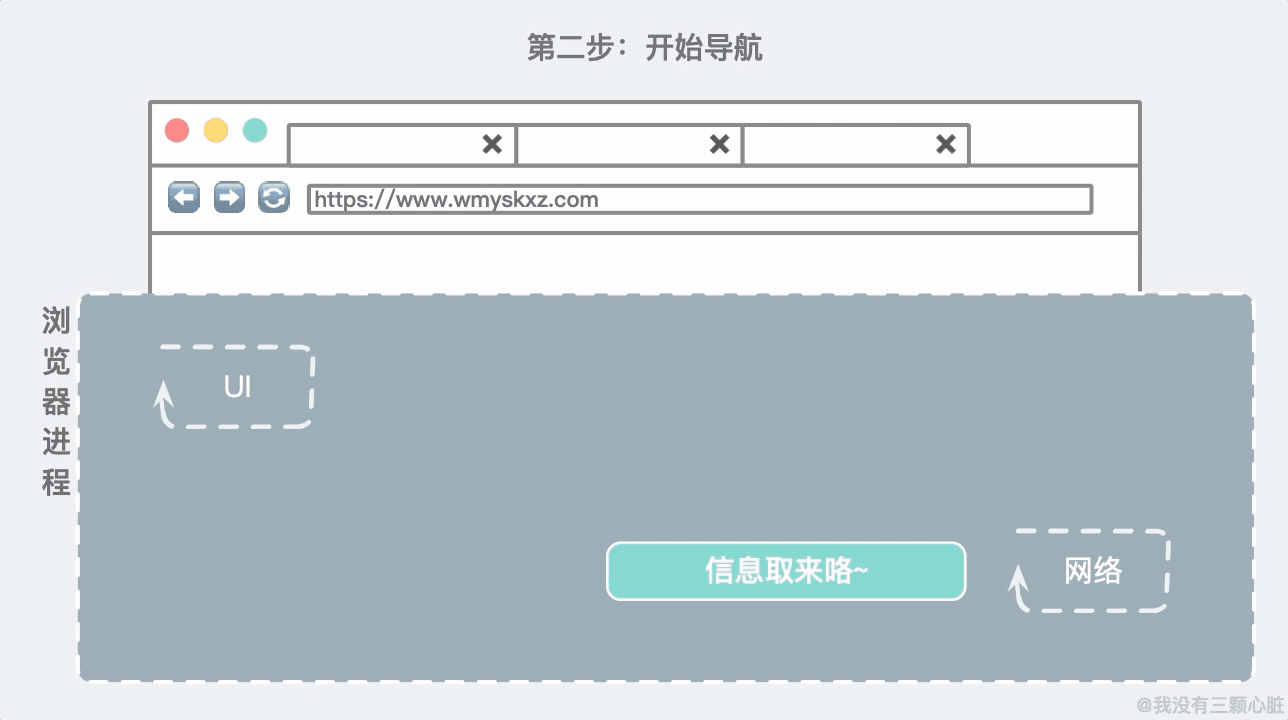
所以我们的第一步就是要判断这个输入到底是个啥:
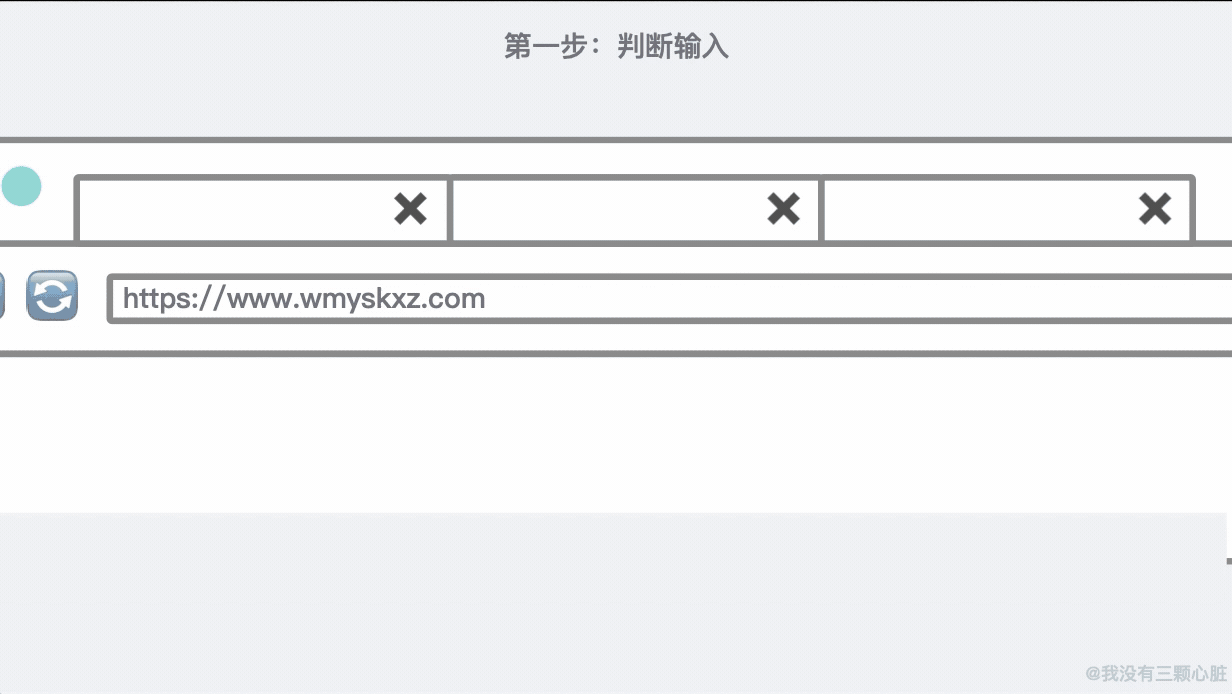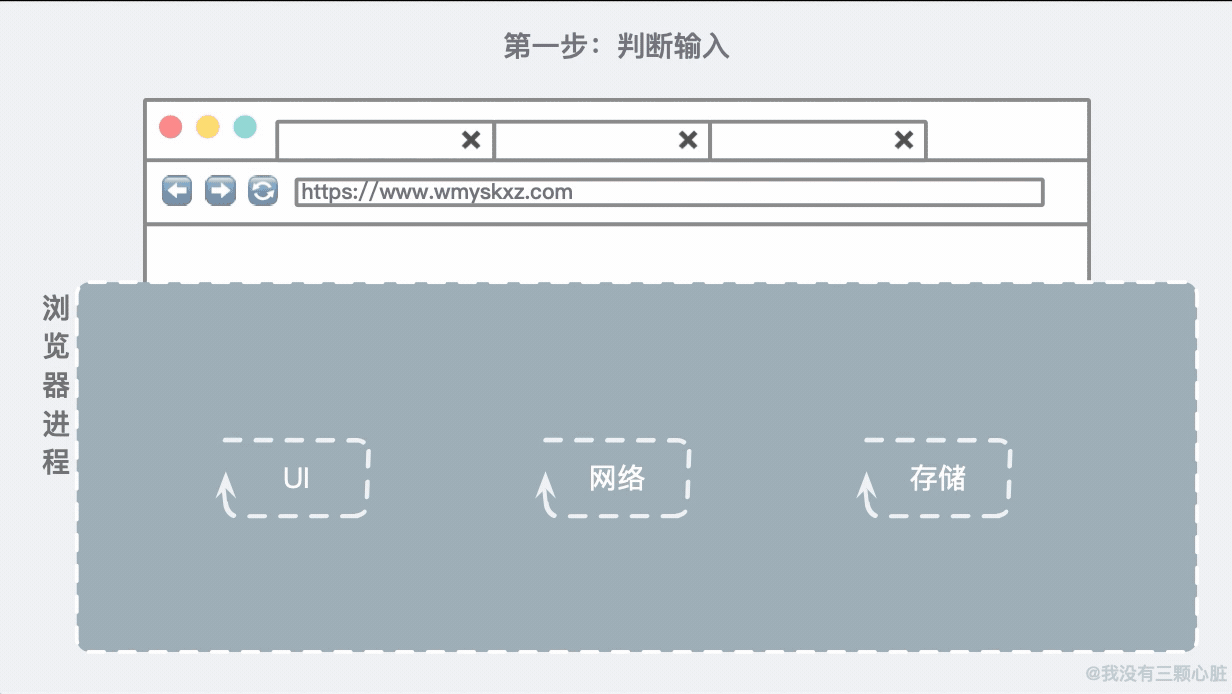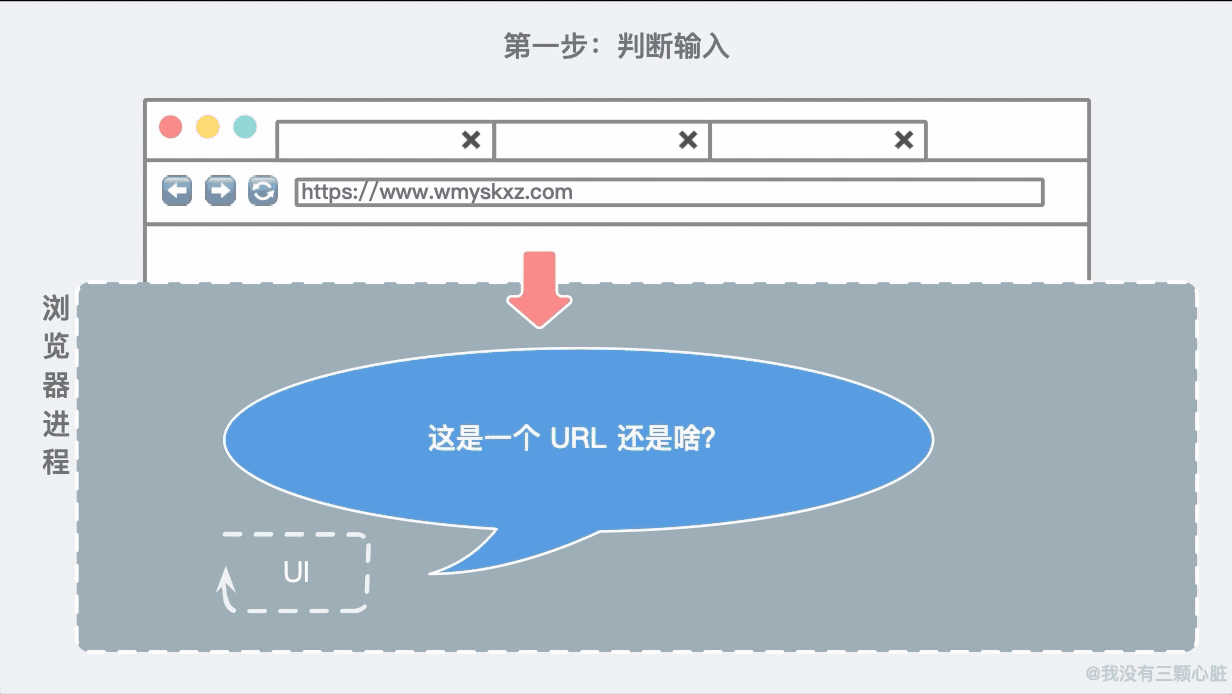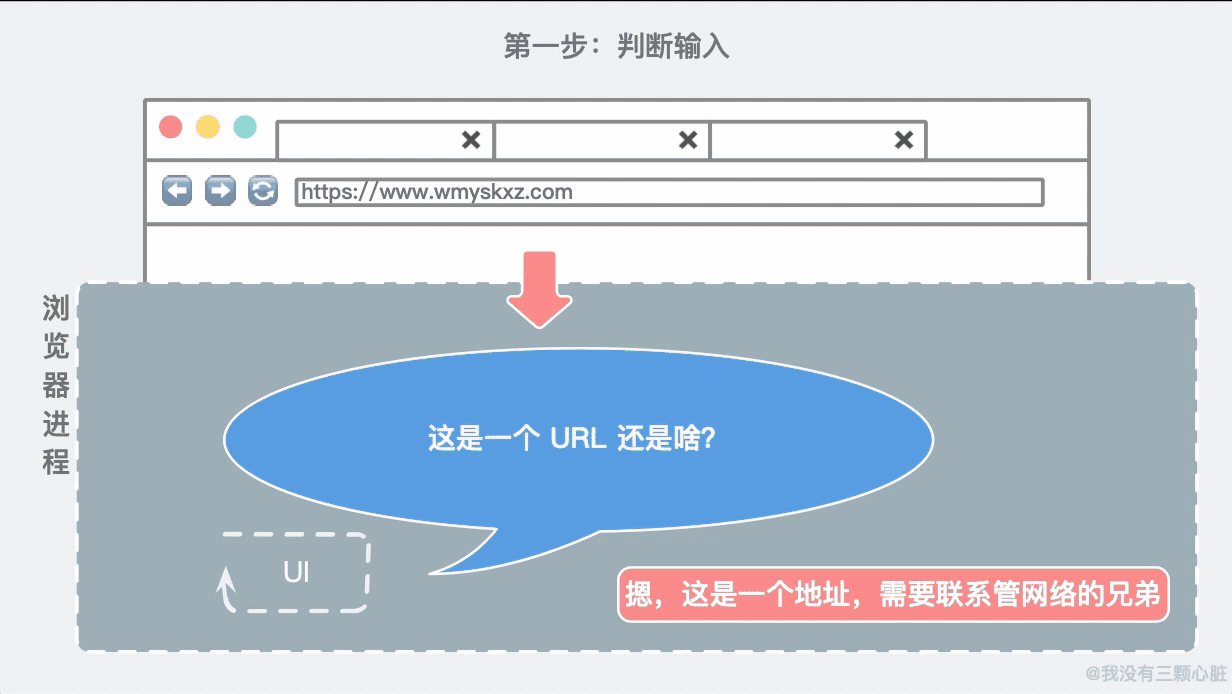
随着用户输入完毕按下 Enter 键,UI 线程知道要启用网络去调取网站的信息。网络线程会负责联系目标主机并获取到信息:
网络线程获取信息的过程,发生了很多事,比如 DNS 域名解析、TLS 建立连接等,如果不熟悉可以看看之前的系列文章。
第三步:读取响应总之网络线程为我们取到了来自网站的响应,大概长这样:

响应分为 header 和 payload 两个部分。header 类似于一本书的版权、作者介绍等相关信息,而 payload 才是真实的数据内容。
浏览器需要根据响应头里的 Content-Type 来区分对应内容的类型,例如 text/html 时浏览器会对内容进行 HTML 解析,image/png 则调用图片渲染器。
然而完全信任网站响应的 Content-Type 是不行的,因为一旦 Content-Type 未指定或者是一个错误的值的时候,就会发生未知的错误。
所以当收到响应主体(payload)时,网络线程会在必要时检查数据的前几个字节,以确保数据内容与 header 里标识的数据类型(Content-Type)一致。如果不一致,那么就需要进行 MIME 类型嗅探来猜测该数据的类型。
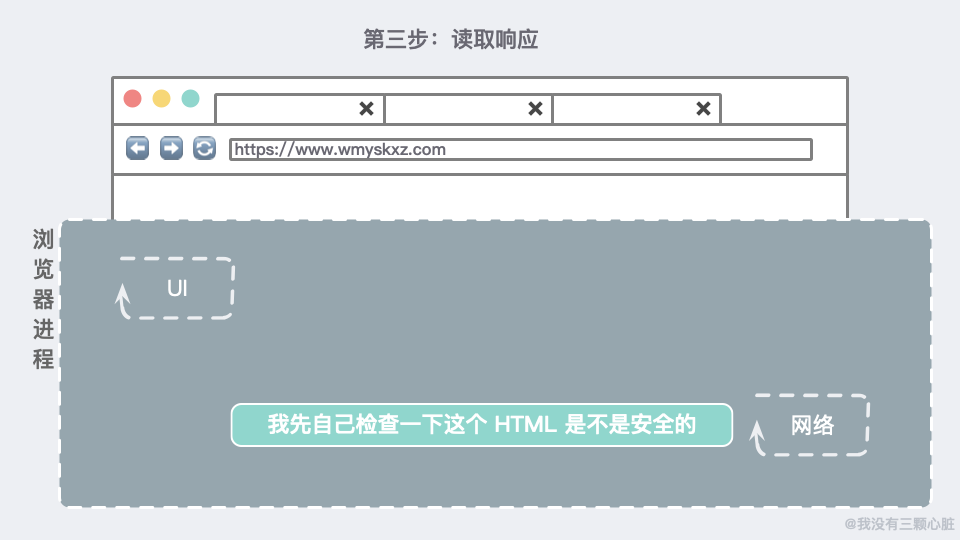
当响应是一个 HTML 文件时,此时也会进行安全检查(SafeBrowsing 检查)。如果域名和相应数据似乎匹配到了一个已知的恶意网站,那么网络线程会显示一个警告页面。
除此之外,还会发生 Cross Origin Read Blocking(CORB)检查,以确保敏感的跨域数据不被传给渲染进程。
第四步:查找渲染进程一旦所有的检查执行完毕并且网络线程确信浏览器会导航到请求的站点,网络线程会告诉 UI 线程所有的数据准备完毕。UI 线程会寻找渲染进程去开始渲染 web 页面。

由于网络请求会花费几百毫秒才获取回响应,因此可以应用一个优化措施。
当第 2 步 UI 线程正发送一个 URL 请求给网络线程时,它已经知道它们会导航到哪个站点。在网络请求的同时,UI 线程并行地尝试主动寻找或开启一个渲染进程。
这样,如果一切按预期进行,渲染进程在网络线程接受到数据时就已经处于待命状态。
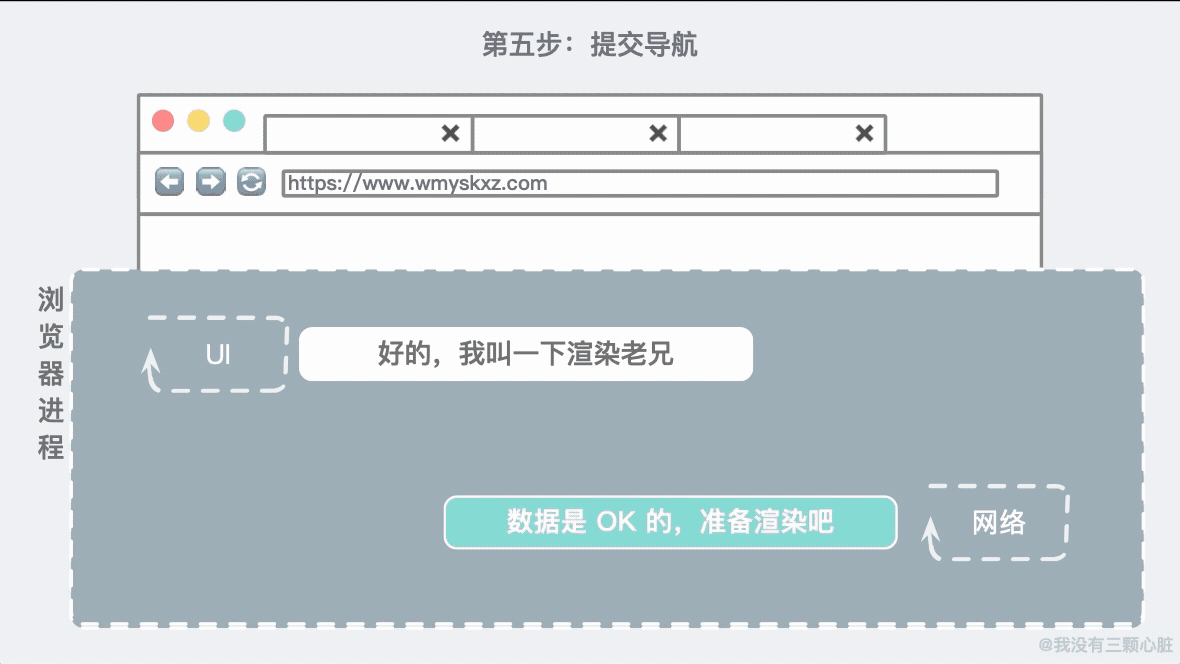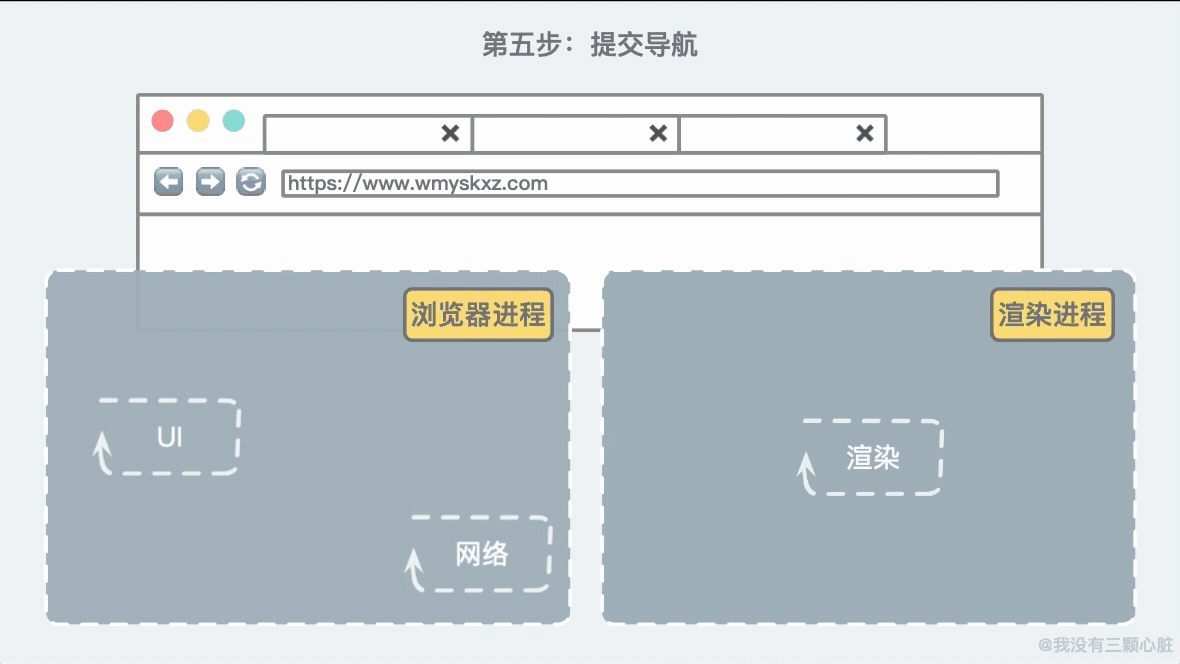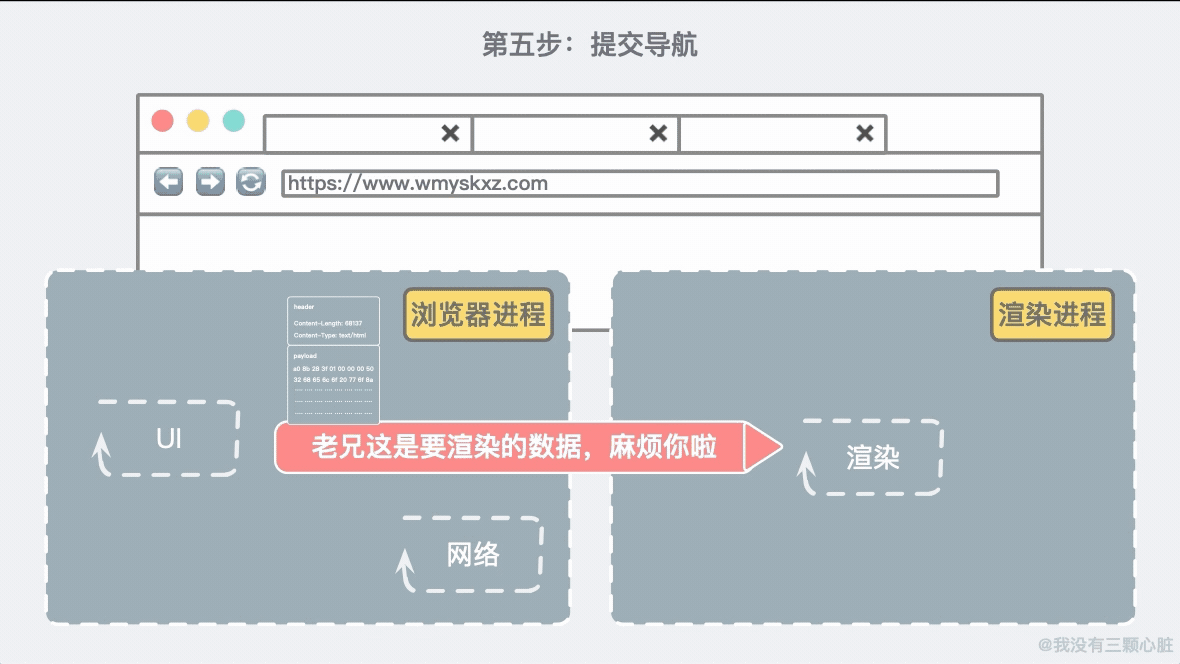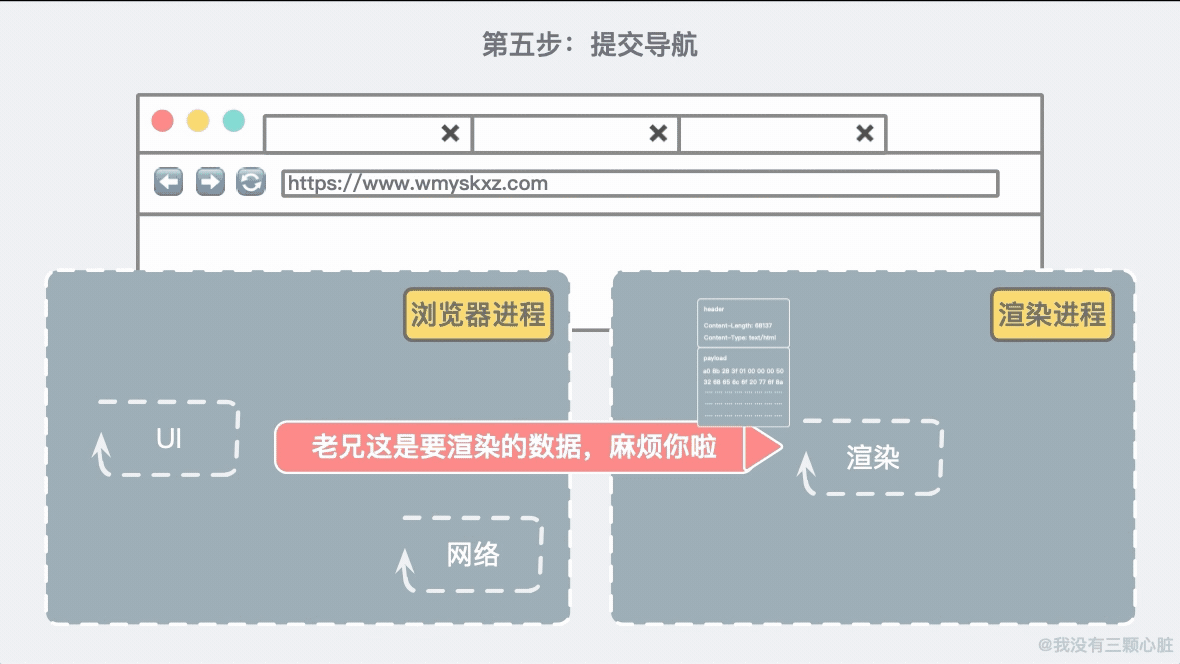
第五步:提交导航现在数据和渲染进程已经就绪,浏览器进程会发送一个 IPC(进程间通信)到渲染进程去提交导航。