
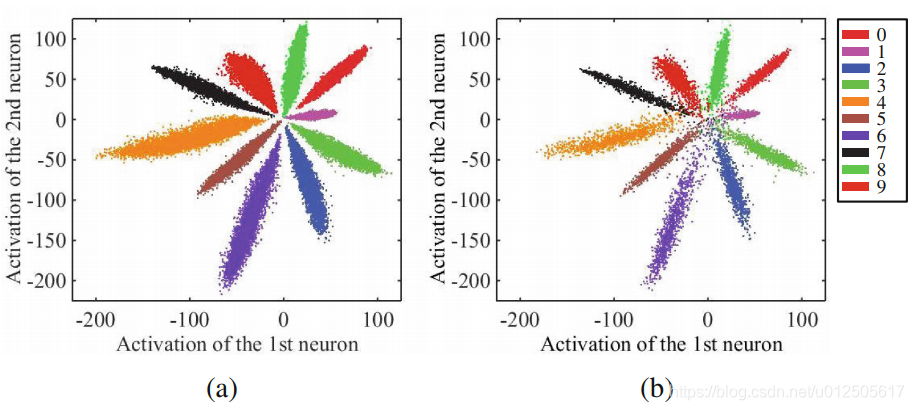
可以发现,Softmax loss做分类可以很好完成任务,但是如果进行相似度比对就会有比较大的问题
(参加[深度概念]·Softmax优缺点解析)
L2距离:L2距离越小,向量相似度越高。可能同类的特征向量距离(黄色)比不同类的特征向量距离(绿色)更大
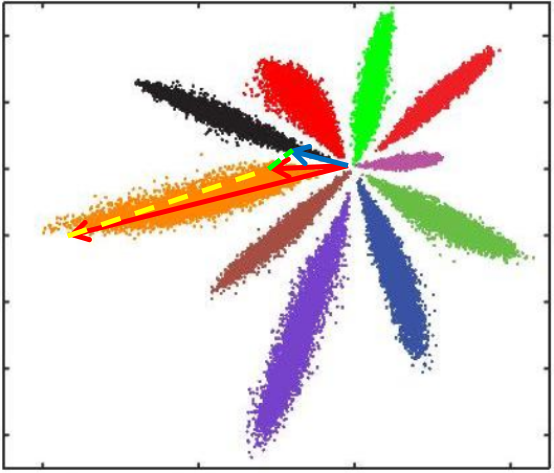
cos距离:夹角越小,cos距离越大,向量相似度越高。可能同类的特征向量夹角(黄色)比不同类的特征向量夹角(绿色)更大
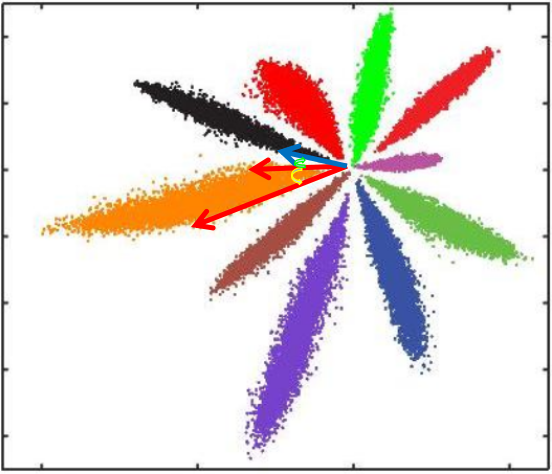
总结来说:
Softmax训练的深度特征,会把整个超空间或者超球,按照分类个数进行划分,保证类别是可分的,这一点对多分类任务如MNIST和ImageNet非常合适,因为测试类别必定在训练类别中。
但Softmax并不要求类内紧凑和类间分离,这一点非常不适合人脸识别任务,因为训练集的1W人数,相对测试集整个世界70亿人类来说,非常微不足道,而我们不可能拿到所有人的训练样本,更过分的是,一般我们还要求训练集和测试集不重叠。
所以需要改造Softmax,除了保证可分性外,还要做到特征向量类内尽可能紧凑,类间尽可能分离。
这种方式只考虑了能否正确分类,却没有考虑类间距离。所以提出了center loss 损失函数。(paper)
2. Center loss