
”支付“消息前面只有”下单“消息,这种情况比较简单。但如果某种类型的消息,前面有N多种消息,需要判断多少次呀,这种判断跟订单系统的耦合性太强了,相当于要把他们系统的逻辑搬一部分到我们系统。
影响消费者的消费速度
这时有种更简单的方案浮出水面:消费者在处理消息时,先判断该订单号在重试表有没有数据,如果有则直接把当前消息保存到重试表。如果没有,则进行业务处理,如果出现异常,把该消息保存到重试表。
后来我们用elastic-job建立了失败重试机制,如果重试了7次后还是失败,则将该消息的状态标记为失败,发邮件通知开发人员。
终于由于网络不稳定,导致用户在划菜客户端有些订单和菜品一直看不到的问题被解决了。现在商户顶多偶尔延迟看到菜品,比一直看不菜品好太多。
消息积压随着销售团队的市场推广,我们系统的商户越来越多。随之而来的是消息的数量越来越大,导致消费者处理不过来,经常出现消息积压的情况。对商户的影响非常直观,划菜客户端上的订单和菜品可能半个小时后才能看到。一两分钟还能忍,半个消息的延迟,对有些暴脾气的商户哪里忍得了,马上投诉过来了。我们那段时间经常接到商户投诉说订单和菜品有延迟。
虽说,加服务器节点就能解决问题,但是按照公司为了省钱的惯例,要先做系统优化,所以我们开始了消息积压问题解决之旅。
最近无意间获得一份BAT大厂大佬写的刷题笔记,一下子打通了我的任督二脉,越来越觉得算法没有想象中那么难了。
BAT大佬写的刷题笔记,让我offer拿到手软
1. 消息体过大虽说kafka号称支持百万级的TPS,但从producer发送消息到broker需要一次网络IO,broker写数据到磁盘需要一次磁盘IO(写操作),consumer从broker获取消息先经过一次磁盘IO(读操作),再经过一次网络IO。
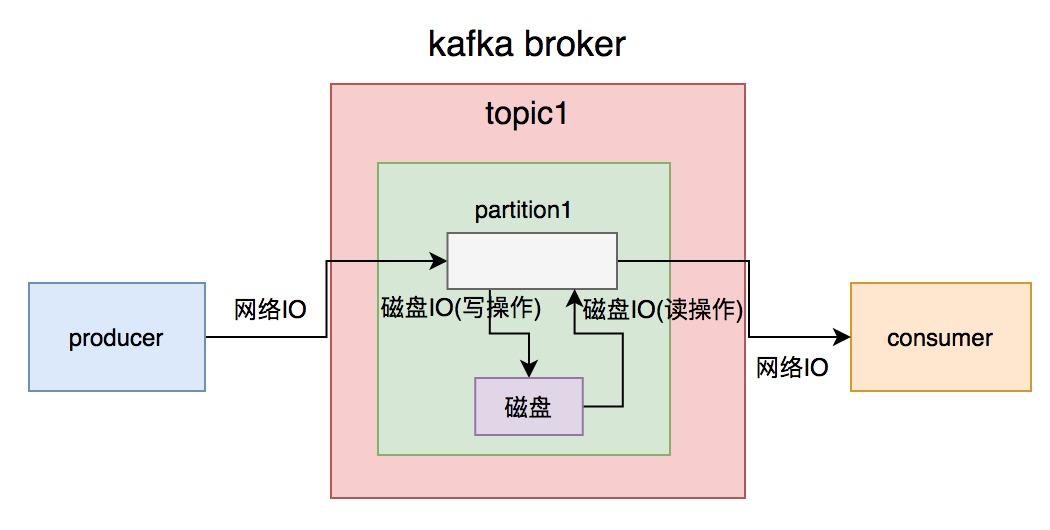
一次简单的消息从生产到消费过程,需要经过2次网络IO和2次磁盘IO。如果消息体过大,势必会增加IO的耗时,进而影响kafka生产和消费的速度。消费者速度太慢的结果,就会出现消息积压情况。
除了上面的问题之外,消息体过大,还会浪费服务器的磁盘空间,稍不注意,可能会出现磁盘空间不足的情况。
此时,我们已经到了需要优化消息体过大问题的时候。
如何优化呢?
我们重新梳理了一下业务,没有必要知道订单的中间状态,只需知道一个最终状态就可以了。
如此甚好,我们就可以这样设计了:
订单系统发送的消息体只用包含:id和状态等关键信息。
后厨显示系统消费消息后,通过id调用订单系统的订单详情查询接口获取数据。
后厨显示系统判断数据库中是否有该订单的数据,如果没有则入库,有则更新。

果然这样调整之后,消息积压问题很长一段时间都没再出现。
2. 路由规则不合理还真别高兴的太早,有天中午又有商户投诉说订单和菜品有延迟。我们一查kafka的topic竟然又出现了消息积压。
但这次有点诡异,不是所有partition上的消息都有积压,而是只有一个。
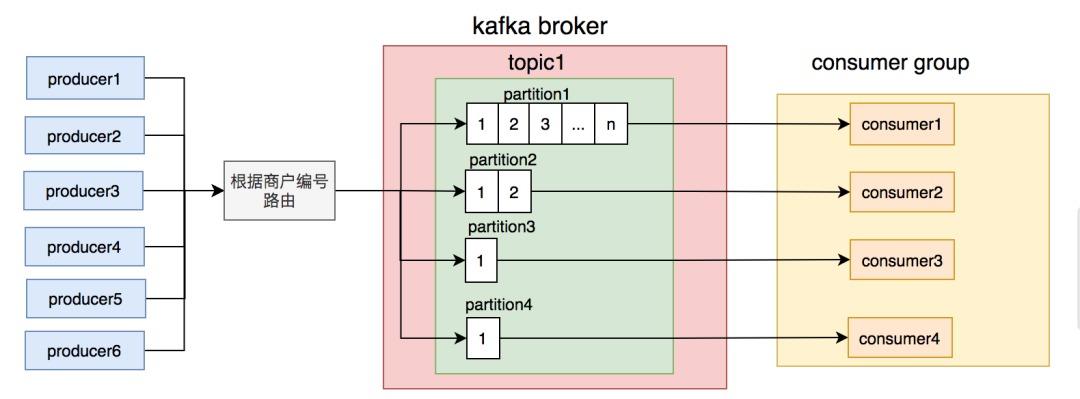
刚开始,我以为是消费那个partition消息的节点出了什么问题导致的。但是经过排查,没有发现任何异常。
这就奇怪了,到底哪里有问题呢?
后来,我查日志和数据库发现,有几个商户的订单量特别大,刚好这几个商户被分到同一个partition,使得该partition的消息量比其他partition要多很多。
这时我们才意识到,发消息时按商户编号路由partition的规则不合理,可能会导致有些partition消息太多,消费者处理不过来,而有些partition却因为消息太少,消费者出现空闲的情况。
为了避免出现这种分配不均匀的情况,我们需要对发消息的路由规则做一下调整。
我们思考了一下,用订单号做路由相对更均匀,不会出现单个订单发消息次数特别多的情况。除非是遇到某个人一直加菜的情况,但是加菜是需要花钱的,所以其实同一个订单的消息数量并不多。
调整后按订单号路由到不同的partition,同一个订单号的消息,每次到发到同一个partition。
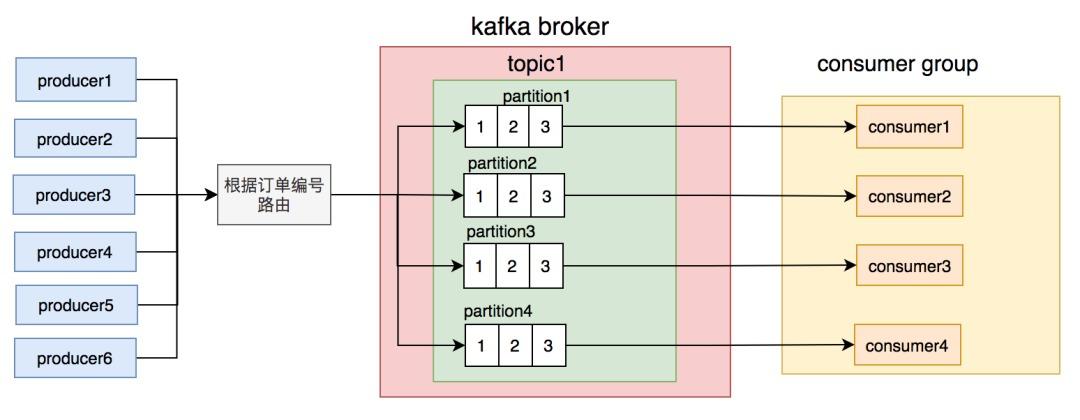
调整后,消息积压的问题又有很长一段时间都没有再出现。我们的商户数量在这段时间,增长的非常快,越来越多了。
3. 批量操作引起的连锁反应