
在高并发的场景中,消息积压问题,可以说如影随形,真的没办法从根本上解决。表面上看,已经解决了,但后面不知道什么时候,就会冒出一次,比如这次:
有天下午,产品过来说:有几个商户投诉过来了,他们说菜品有延迟,快查一下原因。
这次问题出现得有点奇怪。
为什么这么说?
首先这个时间点就有点奇怪,平常出问题,不都是中午或者晚上用餐高峰期吗?怎么这次问题出现在下午?
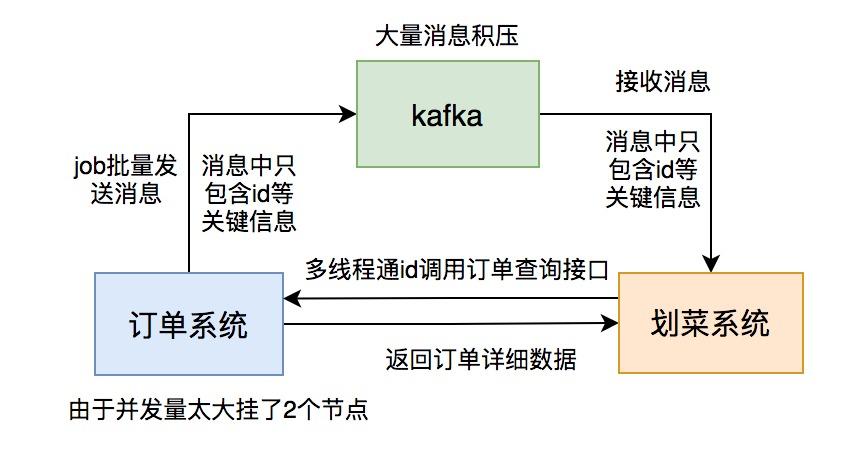
根据以往积累的经验,我直接看了kafka的topic的数据,果然上面消息有积压,但这次每个partition都积压了十几万的消息没有消费,比以往加压的消息数量增加了几百倍。这次消息积压得极不寻常。
我赶紧查服务监控看看消费者挂了没,还好没挂。又查服务日志没有发现异常。这时我有点迷茫,碰运气问了问订单组下午发生了什么事情没?他们说下午有个促销活动,跑了一个JOB批量更新过有些商户的订单信息。
这时,我一下子如梦初醒,是他们在JOB中批量发消息导致的问题。怎么没有通知我们呢?实在太坑了。
虽说知道问题的原因了,倒是眼前积压的这十几万的消息该如何处理呢?
此时,如果直接调大partition数量是不行的,历史消息已经存储到4个固定的partition,只有新增的消息才会到新的partition。我们重点需要处理的是已有的partition。
直接加服务节点也不行,因为kafka允许同组的多个partition被一个consumer消费,但不允许一个partition被同组的多个consumer消费,可能会造成资源浪费。
看来只有用多线程处理了。
为了紧急解决问题,我改成了用线程池处理消息,核心线程和最大线程数都配置成了50。
调整之后,果然,消息积压数量不断减少。
但此时有个更严重的问题出现:我收到了报警邮件,有两个订单系统的节点down机了。
不久,订单组的同事过来找我说,我们系统调用他们订单查询接口的并发量突增,超过了预计的好几倍,导致有2个服务节点挂了。他们把查询功能单独整成了一个服务,部署了6个节点,挂了2个节点,再不处理,另外4个节点也会挂。订单服务可以说是公司最核心的服务,它挂了公司损失会很大,情况万分紧急。
为了解决这个问题,只能先把线程数调小。
幸好,线程数是可以通过zookeeper动态调整的,我把核心线程数调成了8个,核心线程数改成了10个。
后面,运维把订单服务挂的2个节点重启后恢复正常了,以防万一,再多加了2个节点。为了确保订单服务不会出现问题,就保持目前的消费速度,后厨显示系统的消息积压问题,1小时候后也恢复正常了。
后来,我们开了一次复盘会,得出的结论是:
订单系统的批量操作一定提前通知下游系统团队。
下游系统团队多线程调用订单查询接口一定要做压测。
这次给订单查询服务敲响了警钟,它作为公司的核心服务,应4. 对高并发场景做的不够好,需要做优化。
对消息积压情况加监控。
顺便说一下,对于要求严格保证消息顺序的场景,可以将线程池改成多个队列,每个队列用单线程处理。
4. 表过大为了防止后面再次出现消息积压问题,消费者后面就一直用多线程处理消息。
但有天中午我们还是收到很多报警邮件,提醒我们kafka的topic消息有积压。我们正在查原因,此时产品跑过来说:又有商户投诉说菜品有延迟,赶紧看看。这次她看起来有些不耐烦,确实优化了很多次,还是出现了同样的问题。
在外行看来:为什么同一个问题一直解决不了?
其实技术心里的苦他们是不知道的。
表面上问题的症状是一样的,都是出现了菜品延迟,他们知道的是因为消息积压导致的。但是他们不知道深层次的原因,导致消息积压的原因其实有很多种。这也许是使用消息中间件的通病吧。
我沉默不语,只能硬着头皮定位原因了。
后来我查日志发现消费者消费一条消息的耗时长达2秒。以前是500毫秒,现在怎么会变成2秒呢?
奇怪了,消费者的代码也没有做大的调整,为什么会出现这种情况呢?
查了一下线上菜品表,单表数据量竟然到了几千万,其他的划菜表也是一样,现在单表保存的数据太多了。
我们组梳理了一下业务,其实菜品在客户端只展示最近3天的即可。
这就好办了,我们服务端存着多余的数据,不如把表中多余的数据归档。于是,DBA帮我们把数据做了归档,只保留最近7天的数据。
如此调整后,消息积压问题被解决了,又恢复了往日的平静。
主键冲突别高兴得太早了,还有其他的问题,比如:报警邮件经常报出数据库异常: Duplicate entry '6' for key 'PRIMARY',说主键冲突。