
最近刚入职新公司,发现数据库设计有点小问题,数据库字段很多没有NOT NULL,对于强迫症晚期患者来说,简直难以忍受,因此有了这篇文章。
基于目前大部分的开发现状来说,我们都会把字段全部设置成NOT NULL并且给默认值的形式。
通常,对于默认值一般这样设置:
整形,我们一般使用0作为默认值。
字符串,默认空字符串
时间,可以默认1970-01-01 08:00:01,或者默认0000-00-00 00:00:00,但是连接参数要添加zeroDateTimeBehavior=convertToNull,建议的话还是不要用这种默认的时间格式比较好
但是,考虑下原因,为什么要设置成NOT NULL?
来自高性能Mysql中有这样一段话:
尽量避免NULL
很多表都包含可为NULL(空值)的列,即使应用程序并不需要保存NULL也是如此,这是因为可为NULL是列的默认属性。通常情况下最好指定列为NOT NULL,除非真的需要存储NULL值。
如果查询中包含可为NULL的列,对MySql来说更难优化,因为可为NULL的列使得索引、索引统计和值比较都更复杂。可为NULL的列会使用更多的存储空间,在MySql里也需要特殊处理。当可为NULL的列被索引时,每个索引记录需要一个额外的字节,在MyISAM里甚至还可能导致固定大小的索引(例如只有一个整数列的索引)变成可变大小的索引。
通常把可为NULL的列改为NOT NULL带来的性能提升比较小,所以(调优时)没有必要首先在现有schema中查找并修改掉这种情况,除非确定这会导致问题。但是,如果计划在列上建索引,就应该尽量避免设计成可为NULL的列。
当然也有例外,例如值得一提的是,InnoDB使用单独的位(bit)存储NULL值,所以对于稀疏数据有很好的空间效率。但这一点不适用于MyISAM。
书中的描述说了几个主要问题,我这里暂且抛开MyISAM的问题不谈,这里我针对InnoDB作为考量条件。
如果不设置NOT NULL的话,NULL是列的默认值,如果不是本身需要的话,尽量就不要使用NULL
使用NULL带来更多的问题,比如索引、索引统计、值计算更加复杂,如果使用索引,就要避免列设置成NULL
如果是索引列,会带来的存储空间的问题,需要额外的特殊处理,还会导致更多的存储空间占用
对于稀疏数据又更好的空间效率,稀疏数据指的是很多值为NULL,只有少数行的列有非NULL值的情况
默认值对于MySql而言,如果不主动设置为NOT NULL的话,那么插入数据的时候默认值就是NULL。
NULL和NOT NULL使用的空值代表的含义是不一样,NULL可以认为这一列的值是未知的,空值则可以认为我们知道这个值,只不过他是空的而已。
举个例子,一张表中的某一条name字段是NULL,我们可以认为不知道名字是什么,反之如果是空字符串则可以认为我们知道没有名字,他就是一个空值。
而对于大多数程序的情况而言,没有什么特殊需要非要字段要NULL的吧,NULL值反而会对程序造成比如空指针的问题。
对于现状大部分使用MyBatis的情况来说,我建议使用默认生成的insertSelective方法或者纯手动写插入方法,可以避免新增NOT NULL字段导致的默认值不生效或者插入报错的问题。
值计算聚合函数不准确
对于NULL值的列,使用聚合函数的时候会忽略NULL值。
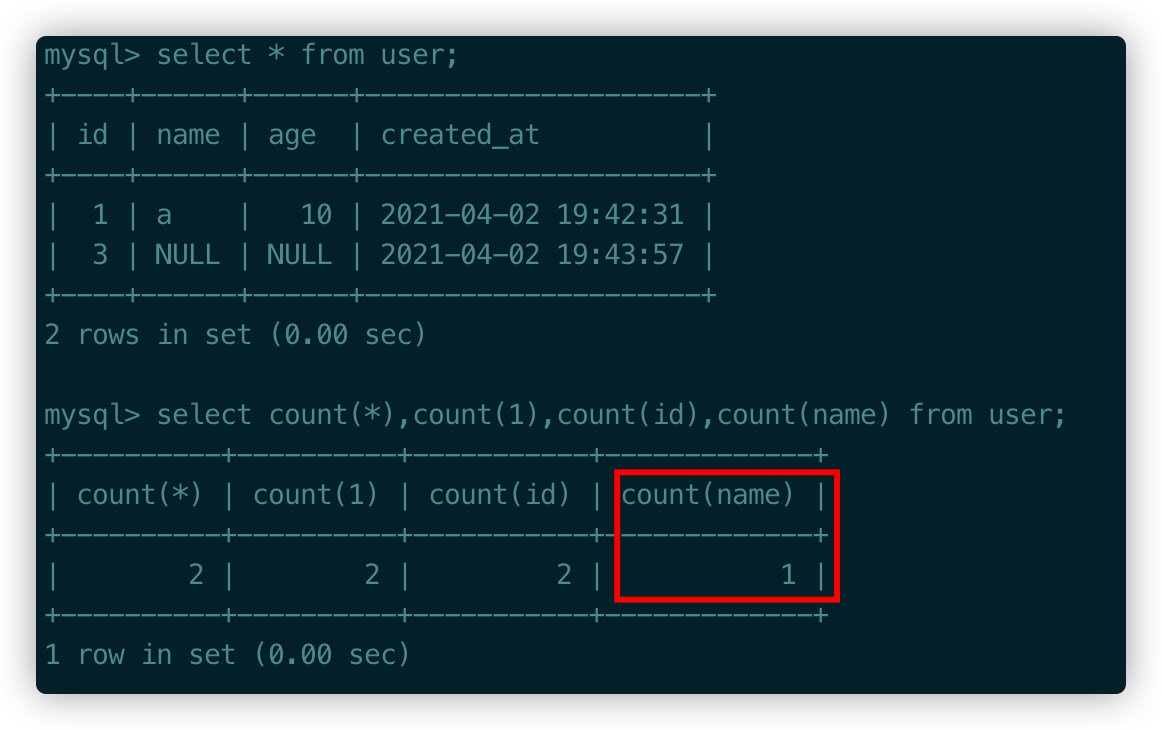
现在我们有一张表,name字段默认是NULL,此时对name进行count得出的结果是1,这个是错误的。
count(*)是对表中的行数进行统计,count(name)则是对表中非NULL的列进行统计。
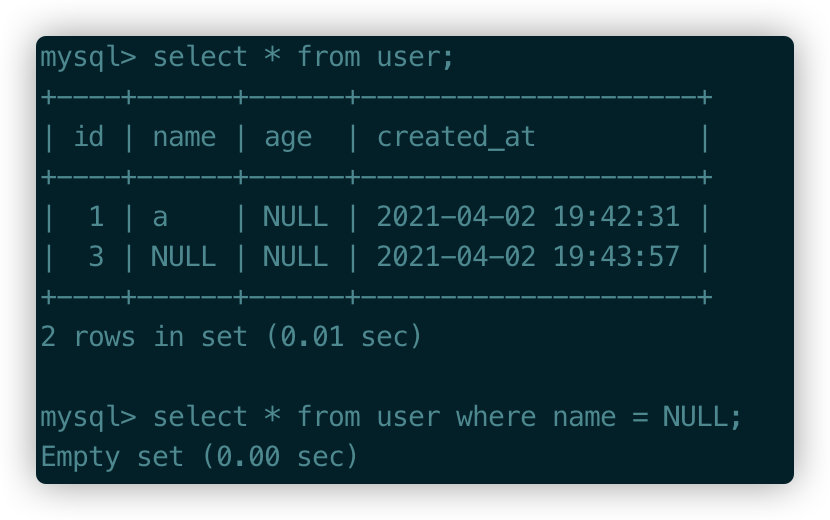
=失效
对于NULL值的列,是不能使用=表达式进行判断的,下面对name的查询是不成立的,必须使用is NULL。
与其他值运算
NULL和其他任何值进行运算都是NULL,包括表达式的值也是NULL。
user表第二条记录age是NULL,所以+1之后还是NULL,name是NULL,进行concat运算之后结果还是NULL。