
可见,MoE化主要变化在需要Expert子网络前后增加MoE相关的逻辑。本文主要介绍平台上的实现。动态路由条件计算,主要包括四个步骤:路由计算、数据分派、独立计算,结果合并。
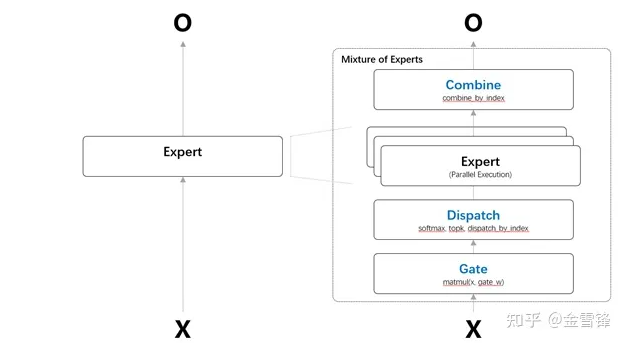
1. 路由计算-Gate:根据输入(可以为整个网络的输入,或者前面网络单元/层的输出),在路由单元完成计算,在以batch内sample-wise的路由中,计算出每个样本要分派的后续网络路由(Mixture-of-Experts/MoE中的专家)。
2. 数据分派-Dispatch:从输入的整体的Tensor中,按照路由计算的样本-专家关系,收集合并出每个专家需要处理的Tensor。如果在固定expert-batch的设计中,要平衡每批训练中,分派到每个专家的样本数和专家每轮训练最大容量,由于样本输入的随机性,很难保证较为均匀的分派,对于低于最大容量的批次,对固定batch-size的要做pad,对于高于最大容量的样本,可以采用延后重采样等方式。为了维护正确的输入输出关系(Input/X – Label/Y)和训练是反向传播的求导关系,实现中需要维护原始batch到每专家的sub-batch的index关系,在后来求导和结合合并时使用。
3. 独立计算-Expert:并发(逻辑上可以先后)调用各个专家处理对应的sub-batch。这也是智能平台要支持的并发API之一。
4. 结果合并-Combine:合并每专家的结果tensor到整个batch的tensor,并按照数据分派索引,交换到原始输入的顺序。
在主流的深度学习智能平台中,可以采用两类主要的实现策略:
张量置零:对需要分派到不同的后续网络单元(专家网络子网等),对需要分派的专家拷贝若干份tensor,对于不应输入当前专家处理的数据维度置零。该方式在保证置零计算逻辑正确的情况下,实现简单,全张量操作,对平台无特殊要求,适用于算法研究,仅体现条件计算前序数据被动态路由到不同的后续网络单元,分析算法的效果。如果通过置零方式,该方法每个专家处理的tensor在batch维度大小是全batch,不能节省计算量和内存使用量。
张量整理:对需要分派到不同的后续网络单元(专家网络子网等),对需要分派的专家拷贝若干份tensor,对于不应输入当前专家处理的数据维度不保留。并维护好sample级的index在变换前后的对应关系。在分布式友好的实现中,如果专家子网为单位被划分到不同的计算节点,那么专家网络的实现最好从子网级的平台对象继承后实现,比如:MindSpore中的mindspore.nn.Cell。详细实现细节参见后续技术实现章节。
核心代码核心代码:路由计算、数据分派、独立计算,结果合并
参考代码采用MindSpore示意实现。(注:import mindspore as ms)
Mixture of Experts的核心逻辑,对输入I,经过routing_network(最简单*W即可),然后topk(若变种算法需要gate权重则需要softmax,否则可不),然后用tensor的操作(可按照batch)选择出每个subnetwork/expert的张量。
为方便调试,采用了规模极小的非随机的确定数值构造输入和路由权重,路由网络采用简单的X*W。
1、路由计算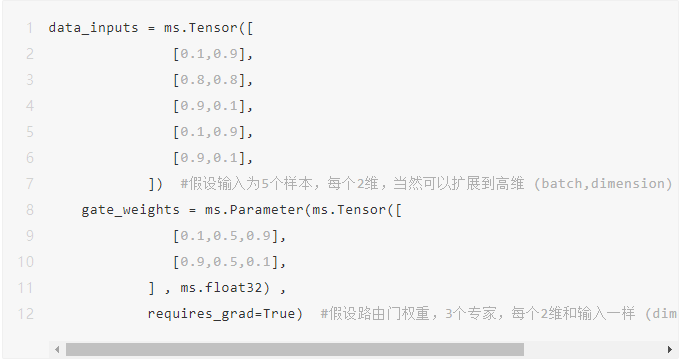
当上述输入5行(仅3类,希望分派给3个专家)样本,和Gate权重做矩阵乘后,可以明确算出每个样本要分派的专家。可以用matmul,也可以类似gates_weighted = einsum('bd,de->be', [data_inputs, gate_weights])第一轮矩阵乘的结果为:

输入和权重乘法,在python中可以采用@,也可以采用matmul,也可以采用爱因斯坦求和简记忆法函数einsum。当是简单的矩阵乘的时候,采用einsum在计算图编译的时候实际会拆分成多个算法,性能并不好;但当输入和权重超过2维,需要以batch维固定做路由计算的时候,使用einsum可以编程实现很简单。
2、分派