
条件计算的分派,主要逻辑是根据路由网络的输出,为每个样本计算出top-k的专家。其实现可以通过topk函数实现。由于top选择score可作为后续网络单元的输入信息(含路由的信息),所以一般要对路由输出做softmax做归一化。
按需计算1:all-N专家之间的归一化权重 (please refer to #2) ,gates_weighted一样,按照dim=-1做了归一化而已其输出为:
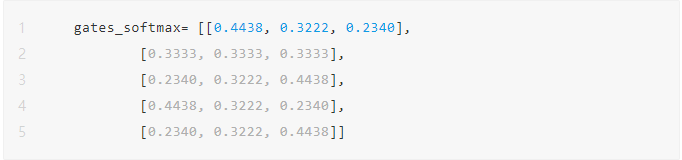
为batch中每个sample选择Top-K个专家 这里为batch中每个的专家权重,可以从softmax-ed来top-k,也可以直接从gates_weighted来top-k;由于这里可能不做softmax或者延后,所以可gates_weighted,这里为batch中每个的专家序号
其输出为:

接着:
按需计算2: top-n专家之间的归一化权重
如何根据分派索引,从原始的输入中,为每个专家提取出属于该专家处理的tensor,在当前的主流智能平台,都没有专门的算子,可以通过其他算子的组合来实现类似的效果。在MindSpore中,可以通过底层的C++实现算子,也可以通过Python中继承Cell并实现bprob, 然后将原始 gate tensor中按照index组织到目标输出中。这里我们实现一个Dispatch类

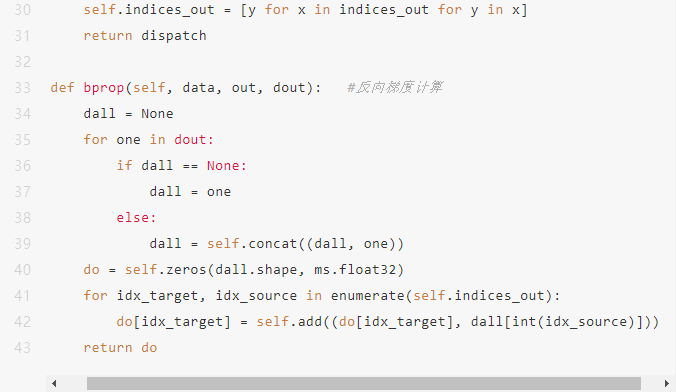
直接并行调用后续的专家网络。并行部分可以通过平台来支持。可以通过特殊的函数或者annotation等标识,也可以由平台编译时优化为并行执行。(在非动态路由条件计算的网络模型中,一般不存在类似的优化。)
4、合并合并的逻辑相对简单,先通过cat按照batch维度做拼接,然后构造正确的zeros tensor用index_add按照索引将各个专家网络的结果在保持input序合并到一起,做为该MoE模块的输出。

上述完成了整个MoE的完整计算过程。
代码框架我们按照上述基本动态路由条件计算的张量操作为主的逻辑,扩展到一个完整的训练代码框架中:
class Dispatch(ms.nn.Cell): 实现路由中的分派逻辑
class Combine(ms.nn.Cell): 实现路由中的组装逻辑
class Route(ms.nn.Cell): 完成整个动态路由逻辑,可以实现为相对通用的类
class Expert(ms.nn.Cell): 平台用户自定义的专家网络
class Network(ms.nn.Cell): 平台用户自定义的大网络
class MSELoss(ms.nn.Cell):实现MSE损失,实现辅助损失的逻辑
class OutputLossGraph(ms.nn.Cell):输出infer和loss,PyNative模式单步
class Dataset: 数据集类,仅满足输入shape和X-Y合理对应关系,仅仅示例def train( …): 训练入口
条件计算实现技术点 1、动态路由不可学习路由