
通过当前段落的index,对\(D\) 进行Lookup得到的段落向量,对于当前段落的所有上下文是共享的,但是其他段落的上下文并不会影响它的值,也就是说它不会跨段落(not across paragraphs) ;
当时词向量矩阵\(W\)对于所有段落、所有上下文都是共享的。
Paragraph Vector without word ordering: Distributed bag of words (PV-DBOW) 是论文提出的第二个学习段落向量的模型,如下图:
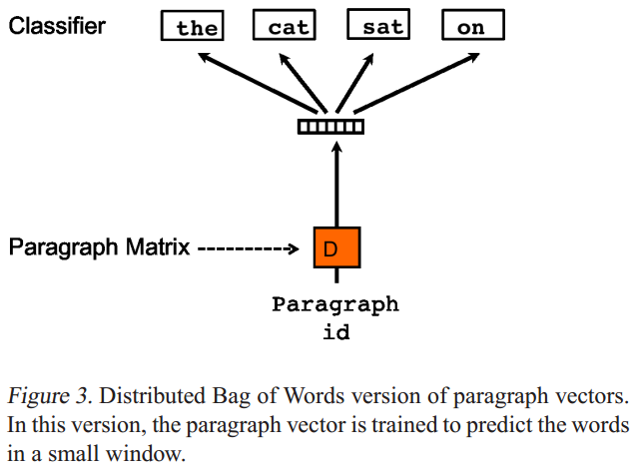
PV-DBOW模型的输入忽略了的上下文单词,但是关注模型从输出的段落中预测从段落中随机抽取的单词;
PV-DBOW模型和训练词向量的Skip-gram模型非常相似。
PV-DM与PV-DBOW的优点它们不仅能获取句子向量,也能获取文档级别向量。论文的工作很有影响力,具体实现已经集成在gensim包中。
3.2 利用篇章级文本的句子连贯性2014年发表的论文提出了一种基于分布式句子表示的模型,用来判断文本连贯性(Coherence)。模型的输入是多个句子(a window of sentences),输出是这些句子是连续的概率。模型的主要步骤如下:
对每个句子进行编码:论文实现了循环神经网络编码和递归神经网络编码两种方式,将每个句子表示成一个\(k \times 1\)的语义向量\(h_{s_i}, i = 1,...,L\),其中\(L\)为句子个数(窗口大小);
将一个窗口内的所有句子的语义向量进行级联,得到大小为\((L \times k) \times 1\)的语义向量\(h_C = [h_{s_1},h_{s_2},...,h_{s_L}]\)后,进行非线性变换,即\(q_C=tanh(W_{sen} \times h_C + b_{sen})\),得到大小为\(H \times 1\)的隐藏层语义表示向量\(q_C\),其中\(W_{sen}\)为大小为\(H \times (L \times k)\)的矩阵,\(b_{sen}\)为大小为\(H \times 1\)的偏移向量;
最后将\(q_C\)输入到全连接层进行二分类,即\(p(y_C=1) = sigmoid(U^Tq_C + b)\),其中\(y_C=1\)表示该窗口中的句子是连贯的,等于0则表示不连贯。
给定一篇包含\(N_d\)个句子的文档\(d={s_1,s_2, ...,s_{N_d}}\),假设\(L=3\),可以生成如下的样本:
\[ < s _ { \text{start} } , s _ { 1 } , s _ { 2 } > , < s _ { 1 } , s _ { 2 } , s _ { 3 } > , \ldots \\ < s _ { N _ { d } - 2 } , s _ { N _ { d } - 1 } , s _ { N _ { d } } > , < s _ { N _ { d } - 1 } , s _ { N _ { d } } , s _ { e n d } > \]
文档\(d\)的连贯性得分\(S_d\)可以定义为所以样本连贯性概率的乘积(得分越大表示越连贯),即
\[
S _ { d } = \prod _ { C \in d } p \left( y _ { C } = 1 \right)
\]
虽然论文的任务是判断文本连贯性,给了后续的研究者研究句子分布式表示的启示:类似于word2vec中使用相邻词预测的方式来获得word embedding,可以通过句子连贯性这个任务自动构建数据集,无需标注即可得到sentence embedding。
3.3 基于Encoder-decoder的Skip-Thought Vectors2015年发表的论文提出了Skip-Thought模型用于得到句子向量表示Skip-Thought Vectors。基本思想是word2vec中的skip-gram模型从词级别到句子级别的推广:对当前句子进行编码后对其周围的句子进行预测。具体地,skip-thought模型如下图,给定一个连续的句子三元组,对中间的句子进行编码,通过编码的句子向量预测前一个句子和后一个句子。Skip-Thought向量的实验结果表明,可以从相邻句子的内容推断出丰富的句子语义。代码开源在https://github.com/tensorflow/models/tree/master/research/skip_thoughts

模型的基本架构与encoder-decoder模型类似,论文中使用的encoder和decoder都为GRU,使用单向GRU称为uni-skip,双向GRU称为bi-skip,将uni-skip和bi-skip生成的sentence embedding进行concat称为combine-skip。论文通过大量实验对比了上述三种变体的效果,总体上来说是uni-skip < bi-skip < combine-skip。
是该篇论文的重要trick。skip-thought模型的词表规模往往是远小于现实中的词表(如用海量数据训练的word2vec)。为了让模型能够对任意句子进行编码,受论文Exploiting similarities among languages for machine translation的启发,本文训练一个线性映射模型,将word2vec的词向量映射为skip-thought模型encoder词表空间的词向量。假设训练后的skip-thought模型的词向量矩阵为X,大小为[num_words,dim1],即词表大小为num_words,词向量维度为dim1,这num_words个词在word2vec中对应的词向量矩阵为Y,大小为[num_words, dim2],即word2vec的词向量维度为dim2。我们的目的是word2vec中的词向量通过线性变换后得到词向量与skip-thought模型encoder空间的词向量无限接近,因此最小化线性回归\(loss= || X - Y * W ||^2\)。得到这个线性模型后,假设待编码的句子中的某个词不属于skip-thought词表,则首先在word2vec词表中进行look up得到word2vec对应的词向量,再通过线性模型映射为skip-thought模型encoder空间的词向量。
3.4 基于AutoEncoder的序列去噪自编码器(SDAE)