

分布式 ID 需要满足的条件:
全局唯一:这是最基本的要求,必须保证 ID 是全局唯一的。
高性能:低延时,不能因为一个小小的 ID 生成,影响整个业务响应速度。
高可用:无限接近于100%的可用性。
好接入:遵循拿来主义原则,在系统设计和实现上要尽可能简单。
趋势递增:这个要看具体业务场景,最好要趋势递增,一般不严格要求。
让我来先捋一捋常见的分布式 ID 的解决方案有哪些?
1、数据库自增 ID这是最常见的方式,利用数据库的 auto_increment 自增 ID,当我们需要一个ID的时候,向表中插入一条记录返回主键 ID。简单,代码也方便,但是数据库本身就存在瓶颈,DB 单点无法扛住高并发场景。
针对数据库单点性能问题,可以做高可用优化,设计成主从模式集群,而且要多主,设置起始数和增长步长。
-- MySQL_1 配置: set @@auto_increment_offset = 1; -- 起始值 set @@auto_increment_increment = 2; -- 步长 -- 自增ID分别为:1、3、5、7、9 ...... -- MySQL_2 配置: set @@auto_increment_offset = 2; -- 起始值 set @@auto_increment_increment = 2; -- 步长 -- 自增ID分别为:2、4、6、8、10 ....但是随着业务不断增长,当性能再次达到瓶颈的时候,想要再扩容就太麻烦了,新增实例可能还要停机操作,不利于后续扩容。
2、UUIDUUID 是 Universally Unique Identifier 的缩写,它是在一定的范围内(从特定的名字空间到全球)唯一的机器生成的标识符,UUID 是16字节128位长的数字,通常以36字节的字符串表示,比如:4D2803E0-8F29-17G3-9B1C-250FE82C4309。
生成ID性能非常好,基本不会有性能问题,代码也简单但是长度过长,不可读,也无法保证趋势递增。
3、雪花算法雪花算法(Snowflake)是 twitter 公司内部分布式项目采用的 ID 生成算法,开源后广受国内大厂的好评,在该算法影响下各大公司相继开发出各具特色的分布式生成器。
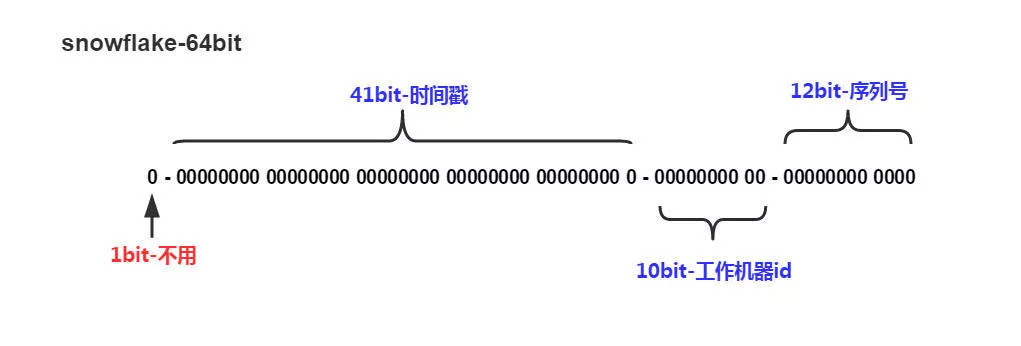
组成结构:正数位(占1 bit)+ 时间戳(占41 bit)+ 机器 ID(占10 bit)+ 自增值(占12 bit),总共64 bit 组成的一个 long 类型。
第一个 bit 位(1 bit):Java 中 long 的最高位是符号位代表正负,正数是0,负数是1,一般生成 ID 都为正数,所以默认为0
时间戳部分(41 bit):毫秒级的时间,不建议存当前时间戳,而是用(当前时间戳 - 固定开始时间戳)的差值,可以使产生的ID从更小的值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年
工作机器id(10bit):也被叫做 workId,这个可以灵活配置,机房或者机器号组合都可以,通常被分为 机器 ID(占5 bit)+ 数据中心(占5 bit)
序列号部分(12bit):自增值支持同一毫秒内同一个节点可以生成4096个 ID
雪花算法不依赖于数据库,灵活方便,且性能优于数据库,ID 按照时间在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况。

雪花算法好像挺不错的样子,靓仔决定采用这个方案试下。
于是一套操作猛如虎,写个 demo 给领导看下。

只能继续思考方案了
4、百度(Uid-Generator)uid-generator 是基于 Snowflake 算法实现的,与原始的 snowflake 算法不同在于,它支持自定义时间戳、工作机器 ID 和 序列号 等各部分的位数,而且 uid-generator 中采用用户自定义 workId 的生成策略,在应用启动时由数据库分配。
具体不多介绍了,官方地址:https://github.com/baidu/uid-generator
也就是说它依赖于数据库,并且由于是基于 Snowflake 算法,所以也不可读。
5、美团(Leaf)美团的 Leaf 非常全面,即支持号段模式,也支持 snowflake 模式。
也不多介绍了,官方地址:https://github.com/Meituan-Dianping/Leaf
号段模式是基于数据库的,而 snowflake 模式是依赖于 Zookeeper 的
6、滴滴(TinyID)TinyID 是基于数据库号段算法实现,还提供了 http 和 sdk 两种方式接入。
文档很全,官方地址:https://github.com/didi/tinyid
7、Redis 模式