
AI应用开发的全流程是对数据源不断地进行处理,并得到最终期望结果的过程。这个过程的每个步骤,都会基于一定的处理逻辑对输入数据进行处理,并得到输出数据,同时也可能会产生一个或多个模型,以及一些可能的元信息文件(如配置项文件等)。
在处理的过程中,可能会接受外部输入(例如用户的输入、配置、其他外部环境的输入等)。每个处理步骤的处理逻辑可以是平台内置的处理逻辑,也可以是开发者自定义的处理逻辑(例如开发者利用平台的开发调试环境开发的一套代码)。当数据源经过一系列处理之后,我们会得到最终的结果数据(例如图像识别精度等报表数据)。在这一系列的处理步骤中,可能会出现反复,例如当我们对某个处理步骤输出的数据不满意时,可以重新修正输入数据或者处理逻辑,重新进行处理,也可以跳到其他处理步骤进行进一步处理。
当前,大部分人工智能是围绕数据为中心进行开发,其中涉及到的算法往往以概率统计为基础,这些算法往往对其输入数据有非常强的先验假设(例如独立同分布等),我们需要将原始数据转换为满足这些假设的数据才能用来训练模型。
学术界对于一些常见的我们通常专注于算法的创新设计和开发,而较少地去做数据的采集、清洗、处理等工作。工业界情况恰好相反,我们需要在数据方面做非常多的工作,例如当我们需要采用机器学习分类算法解决一个具体业务问题时,数据来源可能是多方面的,可能是在本地存储的某些文件,也可能是业务系统的数据库,也可能是一些纸质文档。
因此,我们需要统一的数据源接入层完成数据采集。在这些数据采集过程中,可能还会涉及到模型的训练和推理。例如,可以调用一个现有的OCR模型用来识别纸质文档上的关键数据,用于电子化归档并做进一步处理。除了数据采集之外,我们还需要进行一系列的数据预处理(例如脱敏、去燥、校验、条件筛选等等)。由于目前人工智能算法大部分都是基于监督学习的方法,所以数据标注十分必要。另外,实际的数据经常会面临很多问题,比如数据质量较差、数据冗余性较多、数据规律发现难等。因此数据需要额外的调优工作。数据经过一系列采集、处理、标注、调优之后还需要进行半自动、自动化审核验证。例如在经过标注之后,我们需要能够及时评估标注质量。最后,为了方便管理数据,我们需要数据管理来实现数据的存储对接、数据权限控制、数据版本控制、数据元信息管理、数据集切分等。
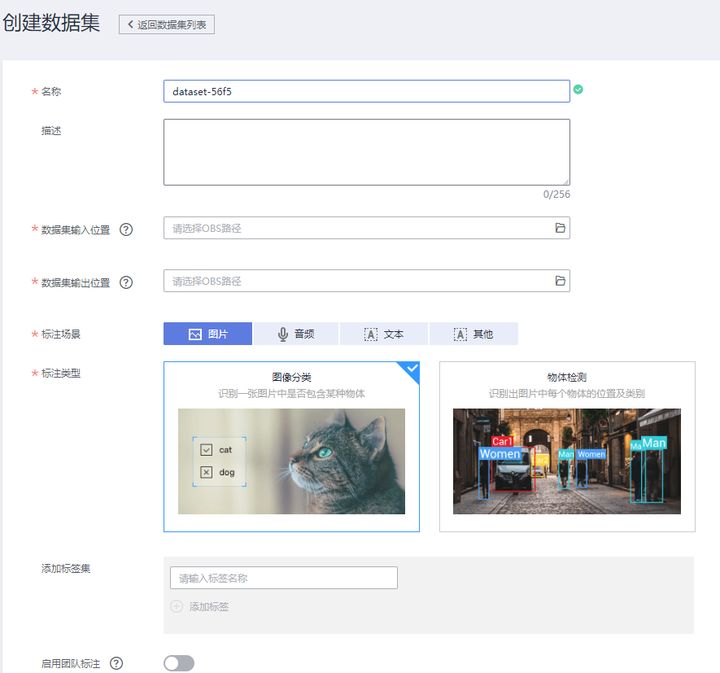
数据获取:数据源接入模块能够保证ModelArts方便地读取各类数据,例如存储在数据库、本地文件系统、对象存储系统等上的离线数据,也可以是来自于实时流系统的数据流、消息等。另外,为了应对数据获取难的问题,ModelArts服务提供了数据检索和数据扩增的能力。
数据预处理:提供一系列的预处理算法和工具包,例如针对于非结构化数据的格式合法性校验、数据脱敏,以及针对于结构化(表格类)数据的特征清洗(异常样本去除、采样等,还有一些针对单个特征的缺失值补充、归一化、统计变换、离散化等)。
数据标注:针对于非结构化数据(例如图像、视频、文本、音频等)通常,提供一系列的智能化标注能力和团队标注能力。
数据调优:提供数据生成、数据迁移、数据选择、特征选择的能力,以及数据特征分析、标签分析、数据可视化的能力。
数据验证和平台:提供数据审核、标注审核的能力,使处理后的数据满足可信要求。
数据集管理:提供数据集存储管理(对接多类存储系统,如对象存储系统、本地文件系统等)、数据集版本管理、数据元信息管理、数据集切分和生成。
对于开发环境的理解