
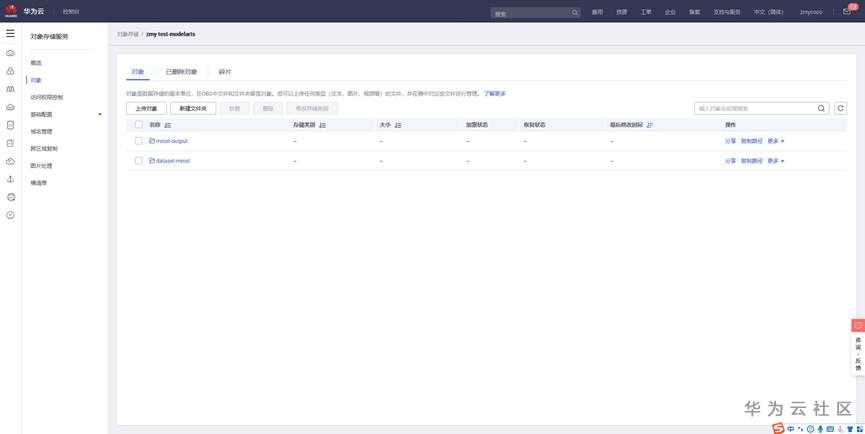
接着在pyCharm打开工程,点击“Run Training Job”:
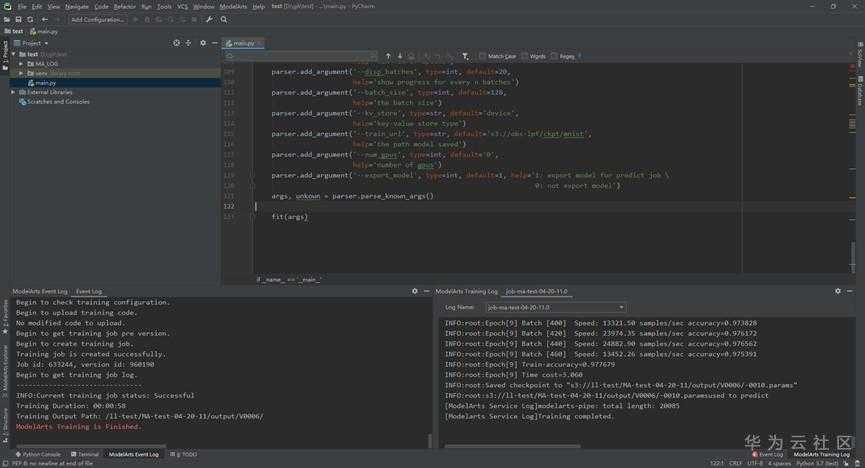
填写参数,可以参考ModelArts训练模型时填写的参数:
训练完成后,训练模型保存在OBS中 /工程名/output/V0006/。
自动学习
在典型的机器学习应用场景中,开发者还必须选择合适的数据预处理工具,特征提取和特征选择方法,从而使原始数据适合机器学习的输入。 在经过这些预处理步骤之后,开发者通常需要根据经验选择恰当的模型算法,以满足当前的场景需求。同时在做模型训练的时候,通常需要做大量的超参数优化,以获得比较优异的的机器学习模型的预测性能。
比如说深度学习在语音识别,图像识别等领域已经取得了令人瞩目的成就。AlexNet在2012年在ImageNet挑战中打败了所有其他传统模型之后,越来越多更加复杂的网络结构被提出来了,网络的层数越来越深,目前的网络已经从最初AlexNet的5个卷积层,增长到目前的上百层,其中涉及到的参数也超过了1亿个。而这些参数都是基于研究人员不断的试错以及调参经验所确定的。而这些通过人工调参得到的模型通常只能针对某一类问题(比如说图像分类)有突出的性能,在遇到新的需要AI建模的问题的时候,通常需要重新构建AI模型,所以在构建AI模型的时候,研究人员需要花费大量的时间和计算资源。
为了降低模型构建的成本,提升AI建模的效率,研究人员提出了自动机器学习(AutoML)的概念,针对特定的机器学习任务,AutoML能够端到端的完成数据处理,特征提取,模型选择以及模型评估。
谈一个ModelArts的自动学习案例-心脏病预测。我们已经了解了机器学习预测模型的实现原理,本文我们并不会自己动手从头实现,因为当前预测算法已经非常成熟,我们完全可以利用一些公有云大厂提供的自动学习技术,实现模型的快速训练及预测。本案例我们采用的是华为云的公有云AI平台ModelArts,数据来源Kaggle网站。
Kaggle是一家在线AI竞赛网站,开源提供了针对各个行业的脱敏数据,用于支持学生训练对应的AI模型。
首先需要下载开源数据集,原始数据(已开源的脱敏数据)下载地址如下:
https://www.kaggle.com/johnsmith88/heart-disease-dataset
打开csv文件,你可以看到如下图所示:

上图中的数据集截图中包括了14个字段,对这14个字段的含义做逐一解释:
Age:年龄;
Sex:性别;
chest pain type (4 values):胸部疼痛类型;
resting blood pressure:静息血压;
serum cholestoral in mg/dl:血浆胆固醇水平;
fasting blood sugar > 120 mg/dl:空腹血糖>120 mg/dl;
resting electrocardiographic results (values 0,1,2):静息心电图结果;
maximum heart rate achieved:最大心率;
exercise induced angina:与运动相关的心绞痛;
oldpeak = ST depression induced by exercise relative to rest:与静息时比较,运动导致的ST段下移;
the slope of the peak exercise ST segment:心电图ST segment的倾斜度;
number of major vessels (0-3) colored by flourosopy:透视检查看到的血管数;
thal: 1 = normal; 2 = fixed defect; 3 = reversable defect:检测方式;
target:0和1。