
摘要: 4月25日,华为云发布盘古系列超大规模预训练模型,包括30亿参数的全球最大视觉(CV)预训练模型,以及与循环智能、鹏城实验室联合开发的千亿参数、40TB训练数据的全球最大中文语言(NLP)预训练模型。后续,华为云还将陆续发布多模态、科学计算等超大预训练模型。
4月25日,华为云发布盘古系列超大规模预训练模型,包括30亿参数的全球最大视觉(CV)预训练模型,以及与循环智能、鹏城实验室联合开发的千亿参数、40TB训练数据的全球最大中文语言(NLP)预训练模型。后续,华为云还将陆续发布多模态、科学计算等超大预训练模型。
华为云人工智能领域首席科学家、IEEE Fellow田奇表示:“预训练大模型是解决AI应用开发定制化和碎片化的重要方法。华为云盘古大模型可以实现一个AI大模型在众多场景通用、泛化和规模化复制,减少对数据标注的依赖,并使用ModelArts平台,让AI开发由作坊式转变为工业化开发的新模式。”

▲华为云人工智能领域首席科学家、IEEE Fellow田奇
全球最大中文语言预训练模型,刷新CLUE三项榜单世界纪录盘古NLP大模型是全球最大的千亿参数中文语言预训练模型,由华为云、循环智能和鹏城实验室联合开发,预训练阶段学习了40TB中文文本数据,并通过行业数据的样本调优提升模型在场景中的应用性能。
盘古NLP大模型在三个方面实现了突破性进展:
第一,具备领先的语言理解和模型生成能力:在权威的中文语言理解评测基准CLUE榜单中,盘古NLP大模型在总排行榜及分类、阅读理解单项均排名第一,刷新三项榜单世界历史纪录;总排行榜得分83.046,多项子任务得分业界领先, 向人类水平(85.61)迈进了一大步。
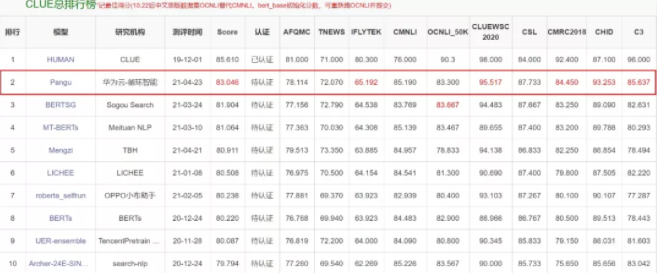
▲盘古NLP大模型位列CLUE榜单总排行榜第一
在NLPCC2018文本摘要任务中,盘古NLP大模型取得了Rouge平均分0.53的业界最佳成绩,超越第二名百分之六十。
第二,盘古NLP大模型在预训练阶段沉淀了大量的通用知识,既能做理解又能做生成。除了能像GPT-3等仅基于端到端生成的方式以外,大模型还可以通过少样本学习对意图进行识别,转化为知识库和数据库查询。通过功能的模块化组合支持行业知识库和数据库的嵌入,进而对接行业经验,使能全场景的快速适配与扩展。比如在华为云和循环智能合作构建的金融客服场景中,盘古NLP大模型能更好地赋能销售环节,帮助服务人员快速提升业务水平,重塑消费者体验。
第三,盘古NLP大模型采用大模型小样本调优的路线,实现了小样本学习任务上超越GPT系列。比如在客户需求分析场景中,使用盘古NLP大模型生产语义标签时,得到目标结果所需的样本量仅为GPT系列模型的十分之一,即AI生产效率可提升十倍。
30亿参数,全球最大视觉预训练模型盘古CV大模型是目前业界最大的视觉预训练模型,包含超过30亿参数。盘古CV大模型首次兼顾了图像判别与生成能力,从而能够同时满足底层图像处理与高层语义理解需求,同时能够方便融合行业知识微调,快速适配各种下游任务。盘古CV大模型性能表现优异,在ImageNet 1%、10%数据集上的小样本分类精度上均达到目前业界最高水平(SOTA)。
盘古CV大模型致力于解决AI工程难以泛化和复制的问题,开创AI开发工业化新模式,大大节约研发成本。此外,盘古CV大模型提供模型预训练、微调、部署和迭代的功能,形成了AI开发完整闭环,极大提升AI开发效率。目前,盘古CV大模型已经在医学影像、金融、工业质检等100余项实际任务中得到了验证,不仅大幅提升了业务测试精度,还能平均节约90%以上的研发成本。
盘古CV大模型助力无人机电力智能巡检