
在执行任务时始终会确认是否满足并行度要求,如果没有就会继续创建新的Worker,与此同时,也会继续 fork 任务,直到最小单元。Worker1 会从 top 端 pop 出来 task(4) 来继续 compute 和 fork,并重新 push 到 WorkQueue 中
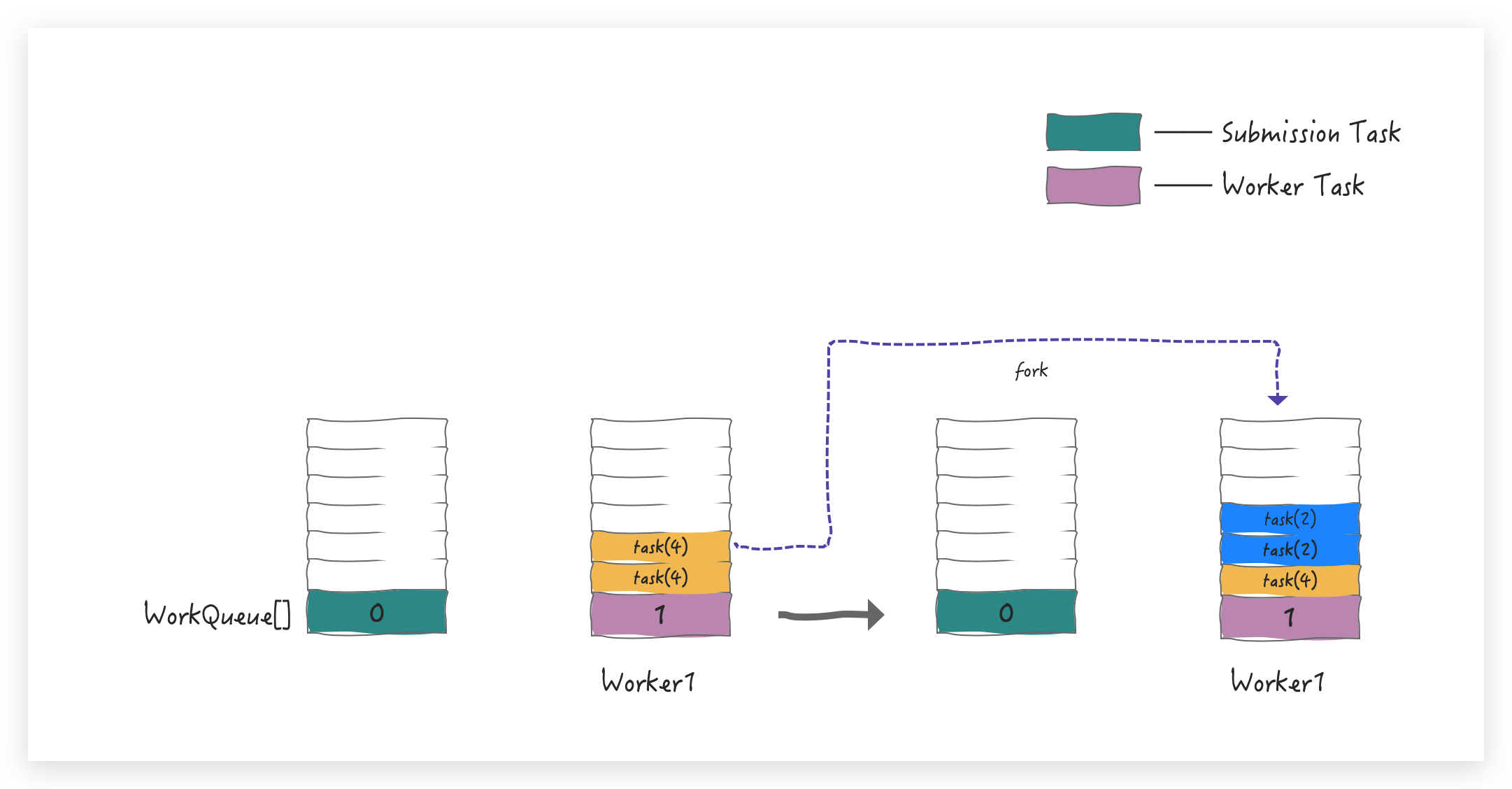
task(2) 还不是最小单元,所以会继续 pop 出 task(2),并最终 fork 出两个 task(1) push 到 WorkQueue中
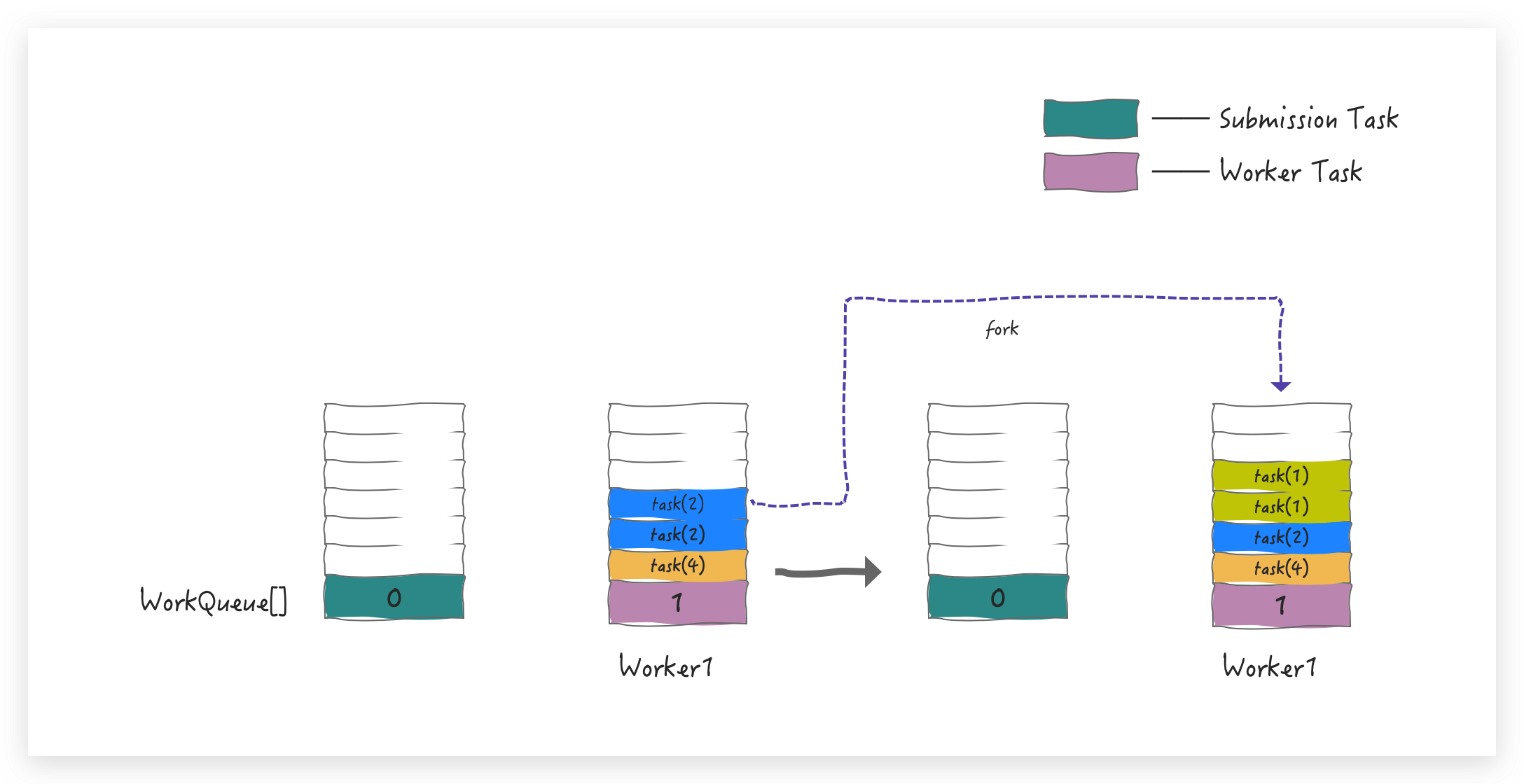
task(1) 已经是最小粒度了,可以直接 pop 出来执行,获取最终结果;在 Worker1 进行这些 pop 操作的同时,为了满足并行度要求也会创建的其他Worker,比如 Worker 2,这时 Worker2 会从 Worker 1 所在队列的 base 端窃取任务
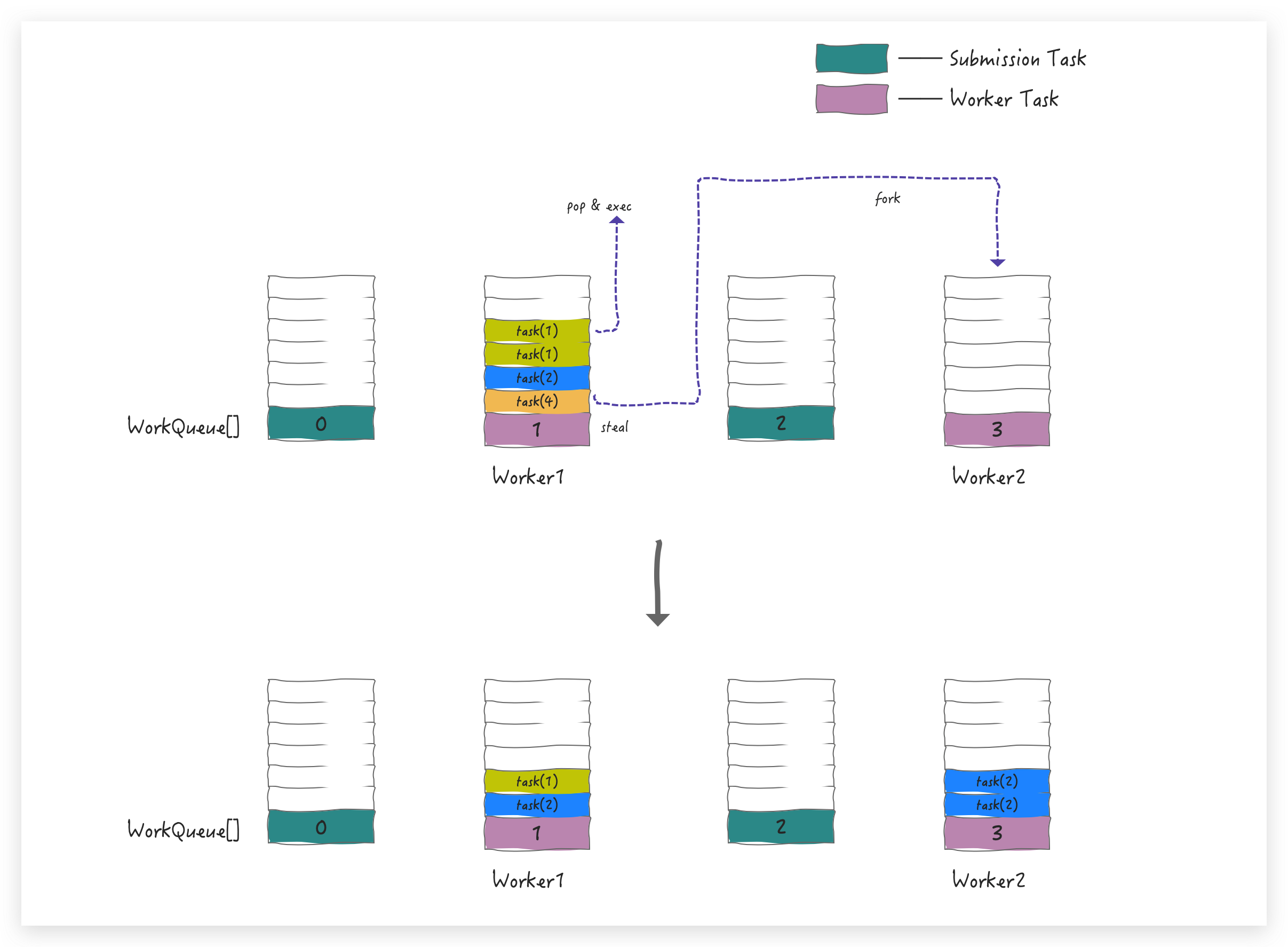
Worker 2 依旧是按照这个规则进行 pop->fork,到最终可以 exec 任务,假设 Worker 1 的任务先执行完,要 join 结果,当 join task(4) 时,通过 hint 定位到是谁偷走了 task(4),这时顺藤摸瓜找到 Worker2,如果 Worker2 还有任务没执行完,Worker1 再窃取回来帮着执行,这样互帮互助,最终快速完成任务
灵魂追问
为什么说 ForkjoinPool 效率要更高?同时建议使用 commonPool?
JDK1.8 Stream 底层就充分用到了 ForkJoinPool,你知道还有哪里用到了 ForkJoinPool 了吗?
ForkJoinPool 最多会有多少个槽位?
下面代码有人说不能充分利用 ForkJoinPool,多个 task 的提交要用 invokeAll,你知道为什么吗?如果不用 invokeAll,要怎样使用 fork/join 呢?
protected Long compute() { if (任务足够小) { return cal(); } SumTask subtask1 = new SumTask(...); SumTask subtask2 = new SumTask(...); // 分别对子任务调用fork(): subtask1.fork(); subtask2.fork(); // 分别获取合并结果: Long subresult1 = subtask1.join(); Long subresult2 = subtask2.join(); return subresult1 + subresult2; } 总结这又是一篇长文,很多小伙伴私下都建议我将长文拆开,一方面读者好消化,另一方面我自己也在数量的体现上变得高产。几次想拆开,但好多文章拆开就失去了连续性(大家都有遗忘曲线)。过年没回老家,就有时间撸文章了。为了更好的理解源码,文章的基础铺垫内容很多,看到这,你应该很累了,想要将更零散的知识点串起来,那就多看代码注释回味一下,然后一起膜拜 Doug Lea 吧
参考Java 并发编程实战
https://www.liaoxuefeng.com/article/1146802219354112
https://www.cnblogs.com/aniao/p/aniao_fjp.html#
https://cloud.tencent.com/developer/article/1705833