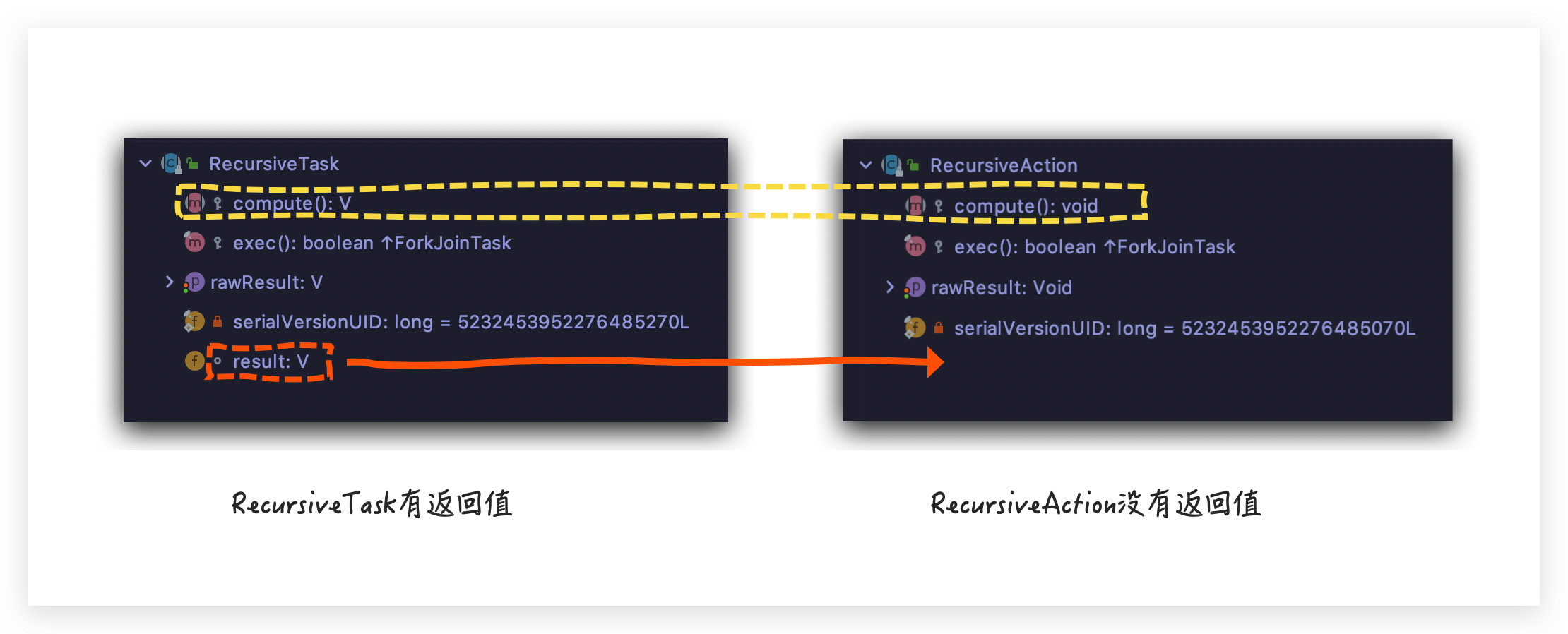
两个类里面都定义了一个抽象方法 compute() ,需要子类重写实现具体逻辑
那子类要遵循什么逻辑重写这个方法呢?
遵循分治思想,重写的逻辑很简单,就是回答三个问题:
什么时候进一步拆分任务?
什么时候满足最小可执行任务,即不再进行拆分?
什么时候汇总子任务结果
用「伪代码」再翻译一下上面这段话,大概就是这样滴:
if(任务小到不用继续拆分){ 直接计算得到结果 }else{ 拆分子任务 调用子任务的fork()进行计算 调用子任务的join()合并计算结果 }(作为程序员,如果你写过递归运算,这个逻辑理解起来是非常简单的)
介绍到这里,就可以用 ForkJoin 干些事情了——经典 Fibonacci 计算就可以用分治思想(不信,你逐条按照上面分治算法适用情况自问自答一下?),直接借用官方 Docs (注意看 compute 方法),额外添加个 main 方法来看一下:
@Slf4j public class ForkJoinDemo { public static void main(String[] args) { int n = 20; // 为了追踪子线程名称,需要重写 ForkJoinWorkerThreadFactory 的方法 final ForkJoinPool.ForkJoinWorkerThreadFactory factory = pool -> { final ForkJoinWorkerThread worker = ForkJoinPool.defaultForkJoinWorkerThreadFactory.newThread(pool); worker.setName("my-thread" + worker.getPoolIndex()); return worker; }; //创建分治任务线程池,可以追踪到线程名称 ForkJoinPool forkJoinPool = new ForkJoinPool(4, factory, null, false); // 快速创建 ForkJoinPool 方法 // ForkJoinPool forkJoinPool = new ForkJoinPool(4); //创建分治任务 Fibonacci fibonacci = new Fibonacci(n); //调用 invoke 方法启动分治任务 Integer result = forkJoinPool.invoke(fibonacci); log.info("Fibonacci {} 的结果是 {}", n, result); } } @Slf4j class Fibonacci extends RecursiveTask<Integer> { final int n; Fibonacci(int n) { this.n = n; } @Override public Integer compute() { //和递归类似,定义可计算的最小单元 if (n <= 1) { return n; } // 想查看子线程名称输出的可以打开下面注释 //log.info(Thread.currentThread().getName()); Fibonacci f1 = new Fibonacci(n - 1); // 拆分成子任务 f1.fork(); Fibonacci f2 = new Fibonacci(n - 2); // f1.join 等待子任务执行结果 return f2.compute() + f1.join(); } }执行结果如下:

进展到这里,相信基本的使用就已经搞定了,上面代码中使用了 ForkJoinPool,那问题来了:
池化既然是一类思想,Java 已经有了 ThreadPoolExecutor ,为什么又要搞出个 ForkJoinPool 呢?
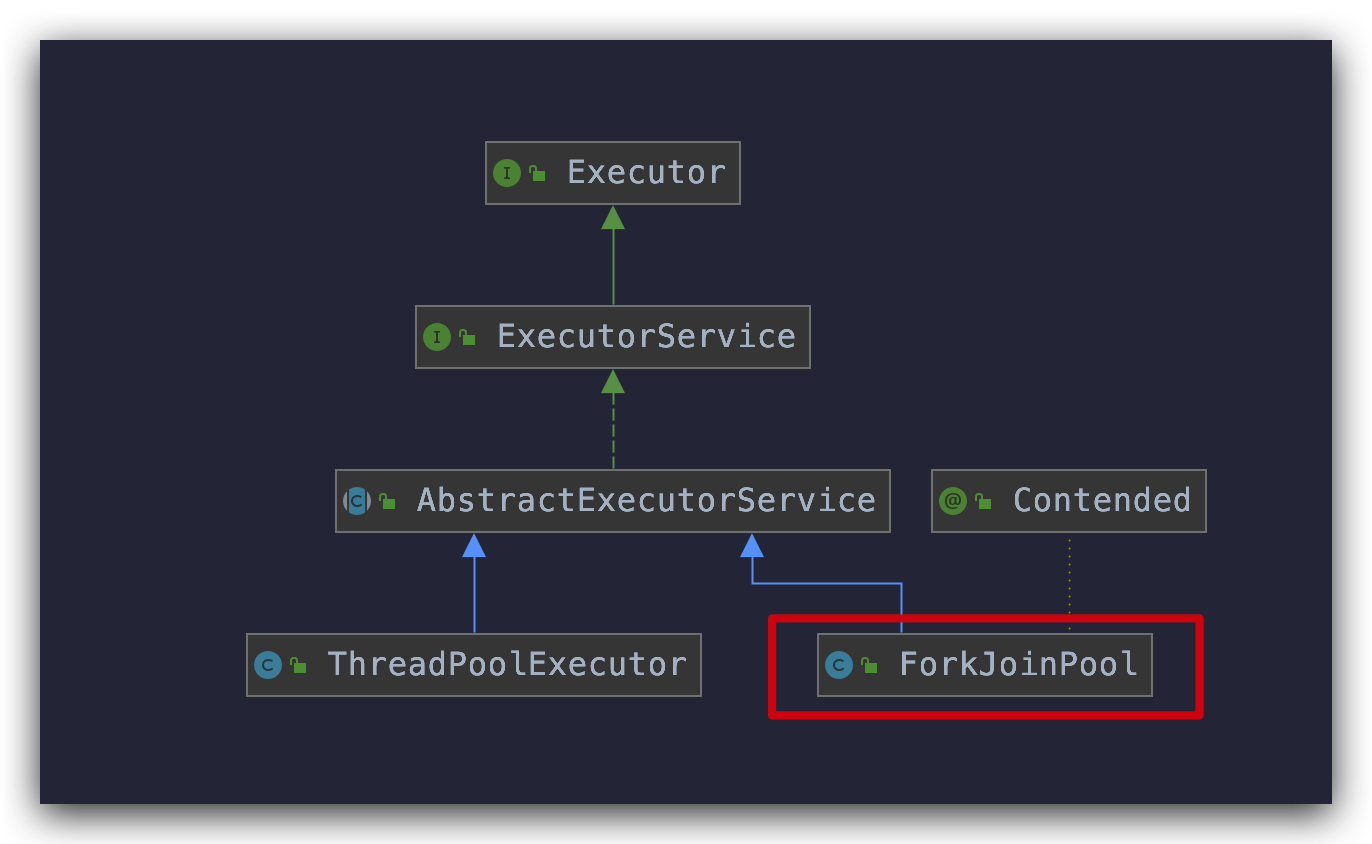
借助下面这张图,先来回忆一下 ThreadPoolExecutor 的实现原理(详情请看为什么要使用线程池):
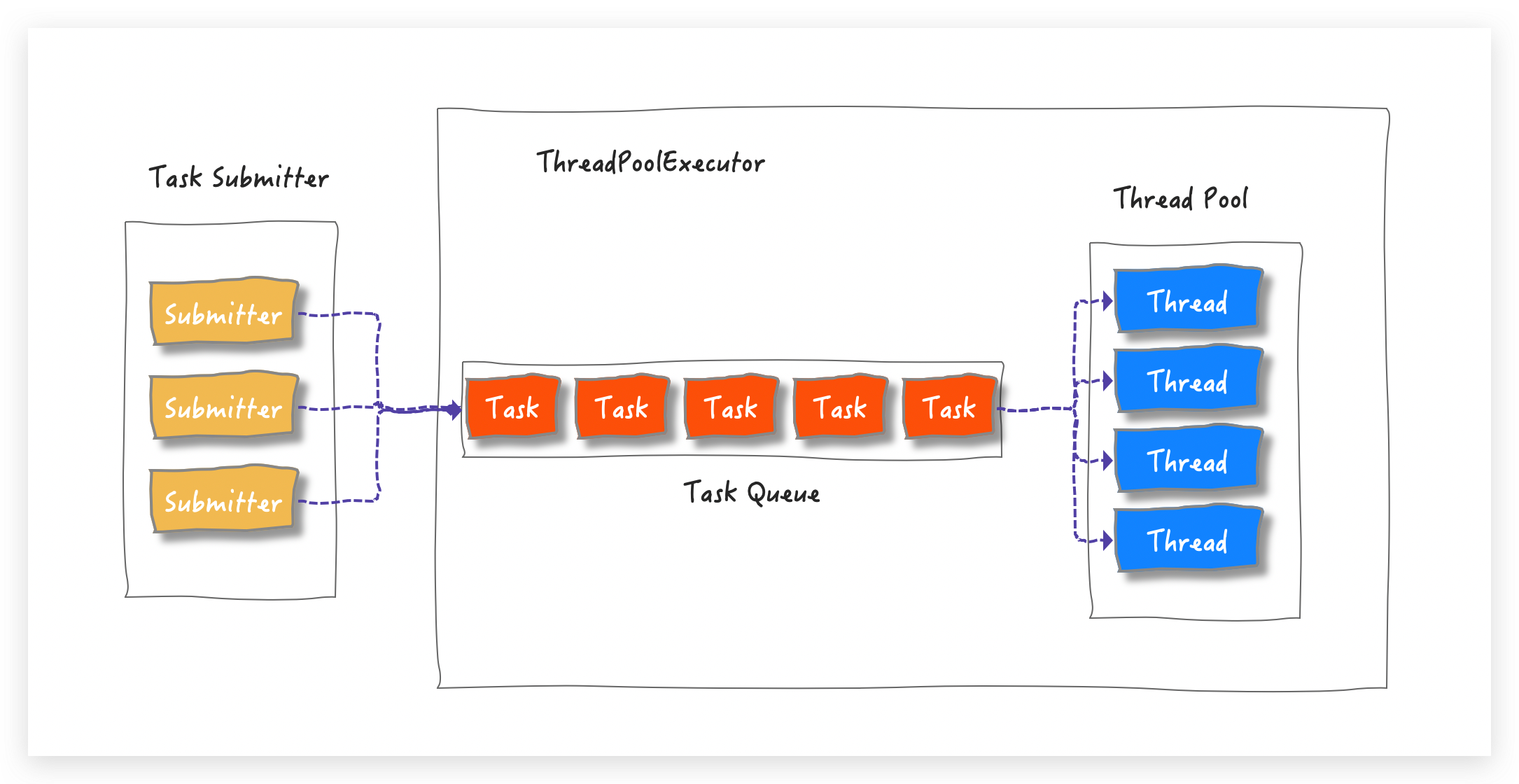
一眼就能看出来这是典型的生产者/消费者模式,消费者线程都从一个共享的 Task Queue 中消费提交的任务。ThreadPoolExecutor 简单的并行操作主要是为了执行时间不确定的任务(I/O 或定时任务等)
JDK 重复造轮子是不可能的,分治思想其实也可以理解成一种父子任务依赖的关系,当依赖层级非常深,用 ThreadPoolExecutor 来处理这种关系很显然是不太现实的,所以 ForkJoinPool 作为功能补充就出现了
ForkJoinPool任务拆分后有依赖关系,还得减少线程之间的竞争,那就让线程执行属于自己的 task 就可以了呗,所以较 ThreadPoolExecutor 的单个 TaskQueue 的形式,ForkJoinPool 是多个 TaskQueue的形式,简单用图来表示,就是这样滴:
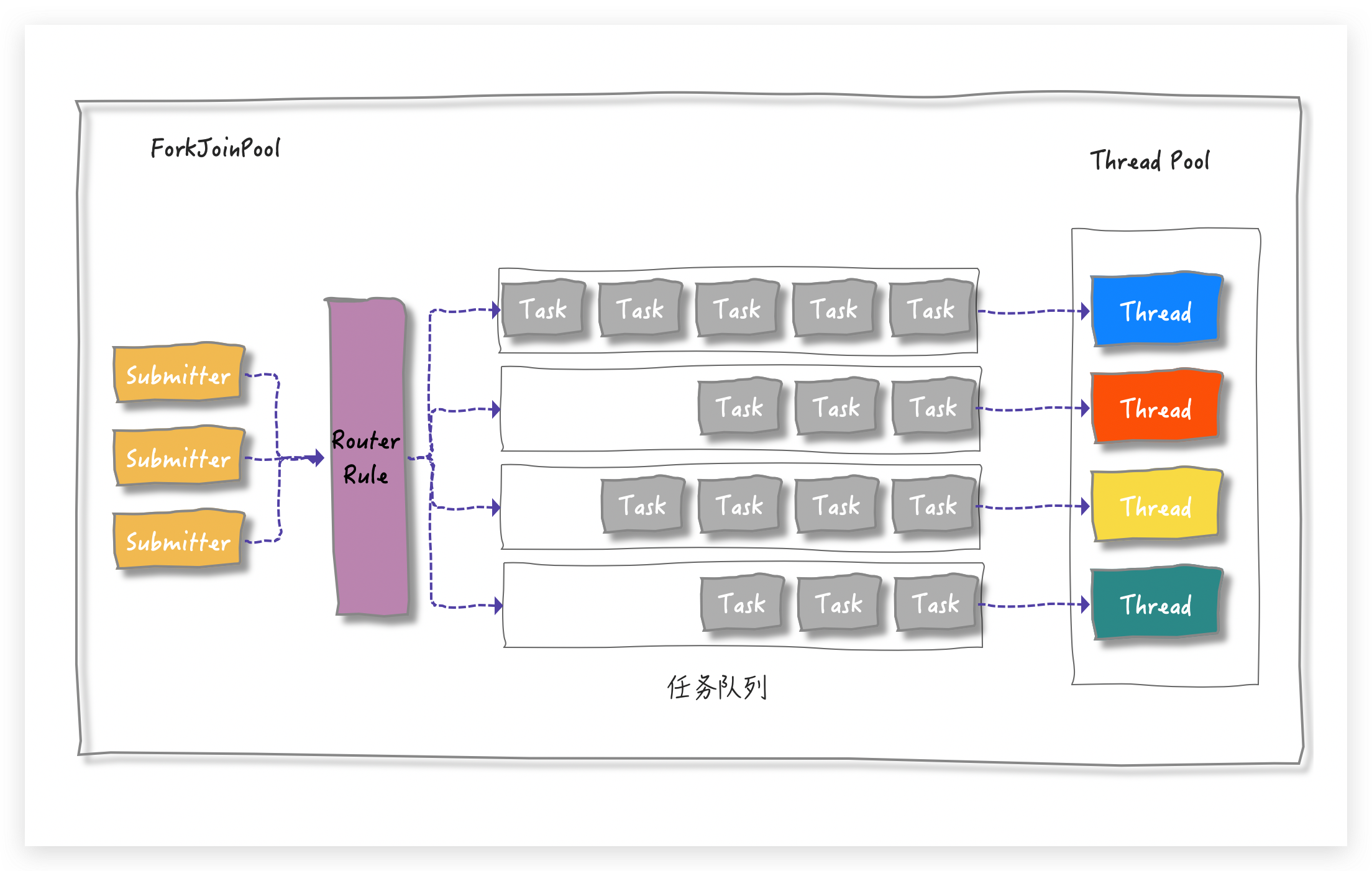
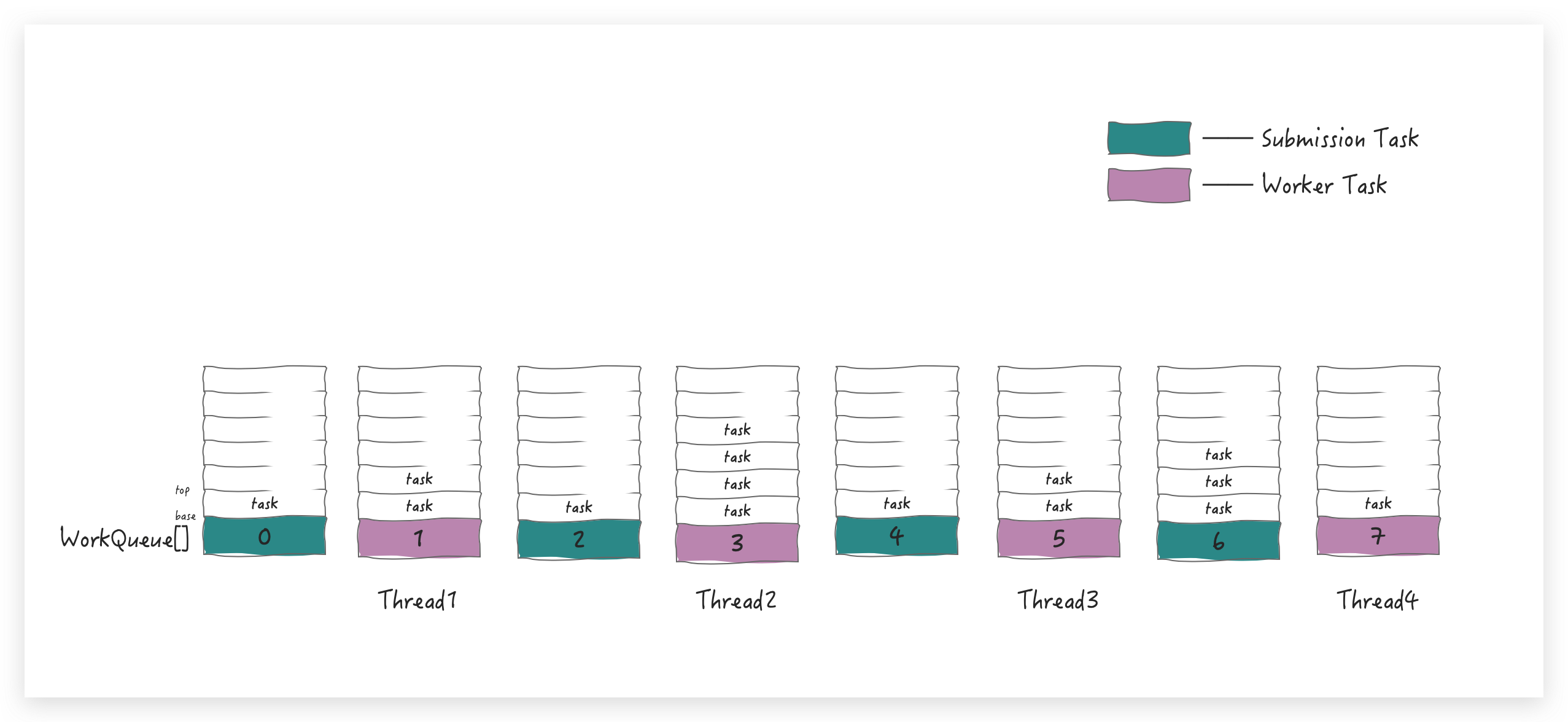
有多个任务队列,所以在 ForkJoinPool 中就有一个数组形式的成员变量 WorkQueue[]。那问题又来了
任务队列有多个,提交的任务放到哪个队列中呢?(上图中的 Router Rule 部分)
这就需要一套路由规则,从上面的代码 Demo 中可以理解,提交的任务主要有两种:
有外部直接提交的(submission task)
也有任务自己 fork 出来的(worker task)
为了进一步区分这两种 task,Doug Lea 就设计一个简单的路由规则:
将 submission task 放到 WorkQueue 数组的「偶数」下标中
将 worker task 放在 WorkQueue 的「奇数」下标中,并且只有奇数下标才有线程( worker )与之相对
应局部丰富一下上图就是这样滴: