
每个任务执行时间都是不一样的(当然是在 CPU 眼里),执行快的线程的工作队列的任务就可能是空的,为了最大化利用 CPU 资源,就允许空闲线程拿取其它任务队列中的内容,这个过程就叫做 work-stealing (工作窃取)
当前线程要执行一个任务,其他线程还有可能过来窃取任务,这就会产生竞争,为了减少竞争,WorkQueue 就设计成了一个双端队列:
支持 LIFO(last-in-first-out) 的push(放)和pop(拿)操作——操作 top 端
支持 FIFO (first-in-first-out) 的 poll (拿)操作——操作 base 端
线程(worker)操作自己的 WorkQueue 默认是 LIFO 操作(可选FIFO),当线程(worker)尝试窃取其他 WorkQueue 里的任务时,这个时候执行的是FIFO操作,即从 base 端窃取,用图丰富一下就是这样滴:
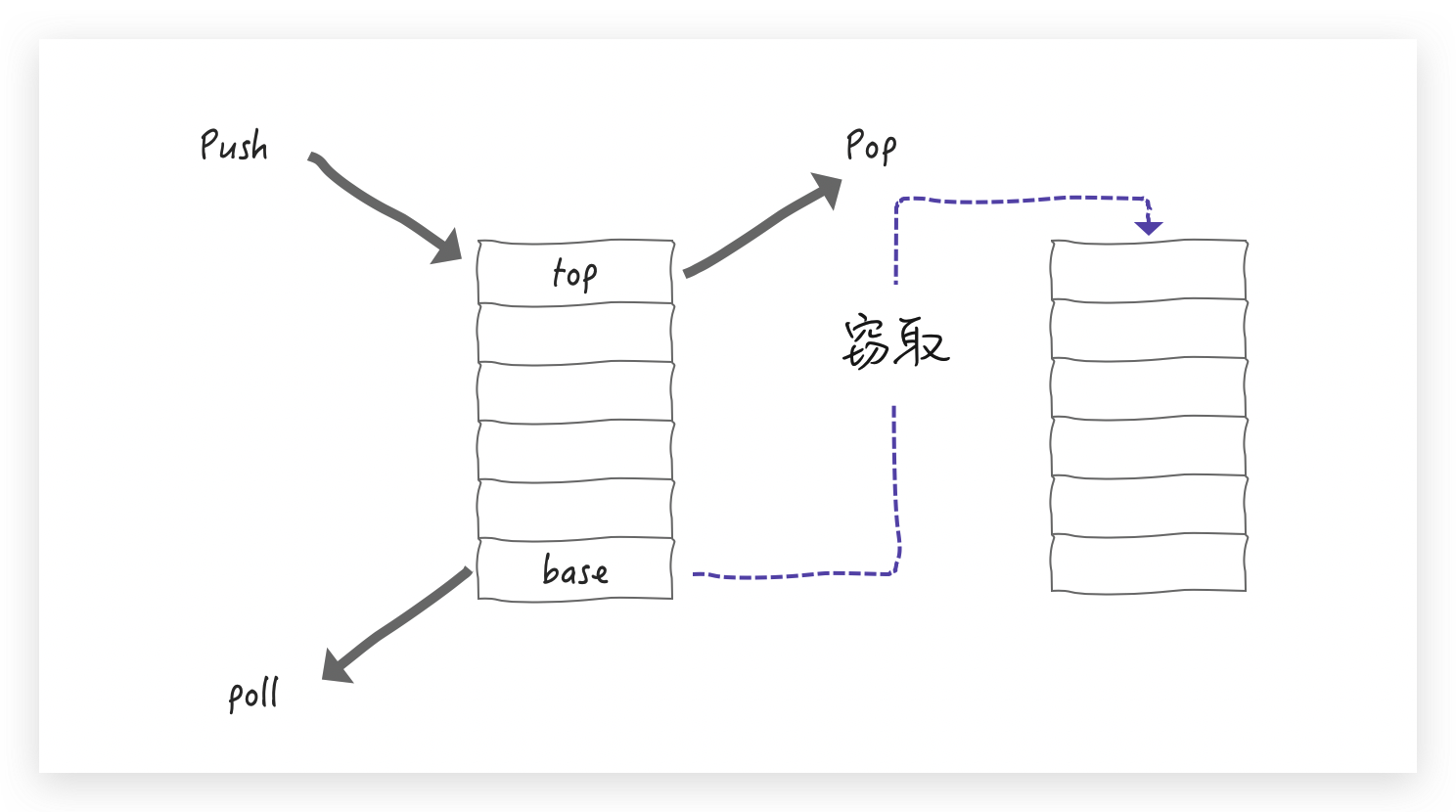
这样的好处非常明显了:
LIFO 操作只有对应的 worker 才能执行,push和pop不需要考虑并发
拆分时,越大的任务越在WorkQueue的base端,尽早分解,能够尽快进入计算
从 WorkQueue 的成员变量的修饰符中也能看出一二了(base 有 volatile 修饰,而 top 却没有):
volatile int base; // index of next slot for poll int top; // index of next slot for push到这里,相信你已经了解 ForkJoinPool 的基本实现原理了,但也会伴随着很多疑问(这都是怎么实现的?),比如:
有竞争就需要锁,ForkJoinPool 是如何控制状态的呢?
ForkJoinPool 的线程数是怎么控制的呢?
上面说的路由规则的具体逻辑是什么呢?
......
保留住这些问题,一点点看源码来了解一下吧:

ForkJoinPool 的源码涉及到大量的位运算,这里会把核心部分说清楚,想要理解的更深入,还需要大家自己一点点追踪查看
结合上面的铺垫,你应该知道 ForkJoinPool 里有三个重要的角色:
ForkJoinWorkerThread(继承 Thread):就是我们上面说的线程(Worker)
WorkQueue:双向的任务队列
ForkJoinTask:Worker 执行的对象
源码分析的整个流程也是围绕这几个类的方法来说明,但在了解这三个角色之前,我们需要先了解 ForkJoinPool 都为这三个角色铺垫了哪些内容

故事就得从 ForkJoinPool 的构造方法说起
ForkJoinPool 构造方法 public ForkJoinPool() { this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()), defaultForkJoinWorkerThreadFactory, null, false); } public ForkJoinPool(int parallelism) { this(parallelism, defaultForkJoinWorkerThreadFactory, null, false); } public ForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory, UncaughtExceptionHandler handler, boolean asyncMode) { this(checkParallelism(parallelism), checkFactory(factory), handler, asyncMode ? FIFO_QUEUE : LIFO_QUEUE, "ForkJoinPool-" + nextPoolId() + "-worker-"); checkPermission(); }除了以上三个构造方法之外,在 JDK1.8 中还增加了另外一种初始化 ForkJoinPool 对象的方式(QQ:这是什么设计模式?):
static final ForkJoinPool common; /** * @return the common pool instance * @since 1.8 */ public static ForkJoinPool commonPool() { // assert common != null : "static init error"; return common; }