
这个时候就出现了数据分片,数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中。数据分片的有效手段就是对关系型数据库进行分库和分表。
区别于分区的是,分区一般都是放在单机里的,用的比较多的是时间范围分区,方便归档。只不过分库分表需要代码实现,分区则是mysql内部实现。分库分表和分区并不冲突,可以结合使用。
说说分库与分表的设计
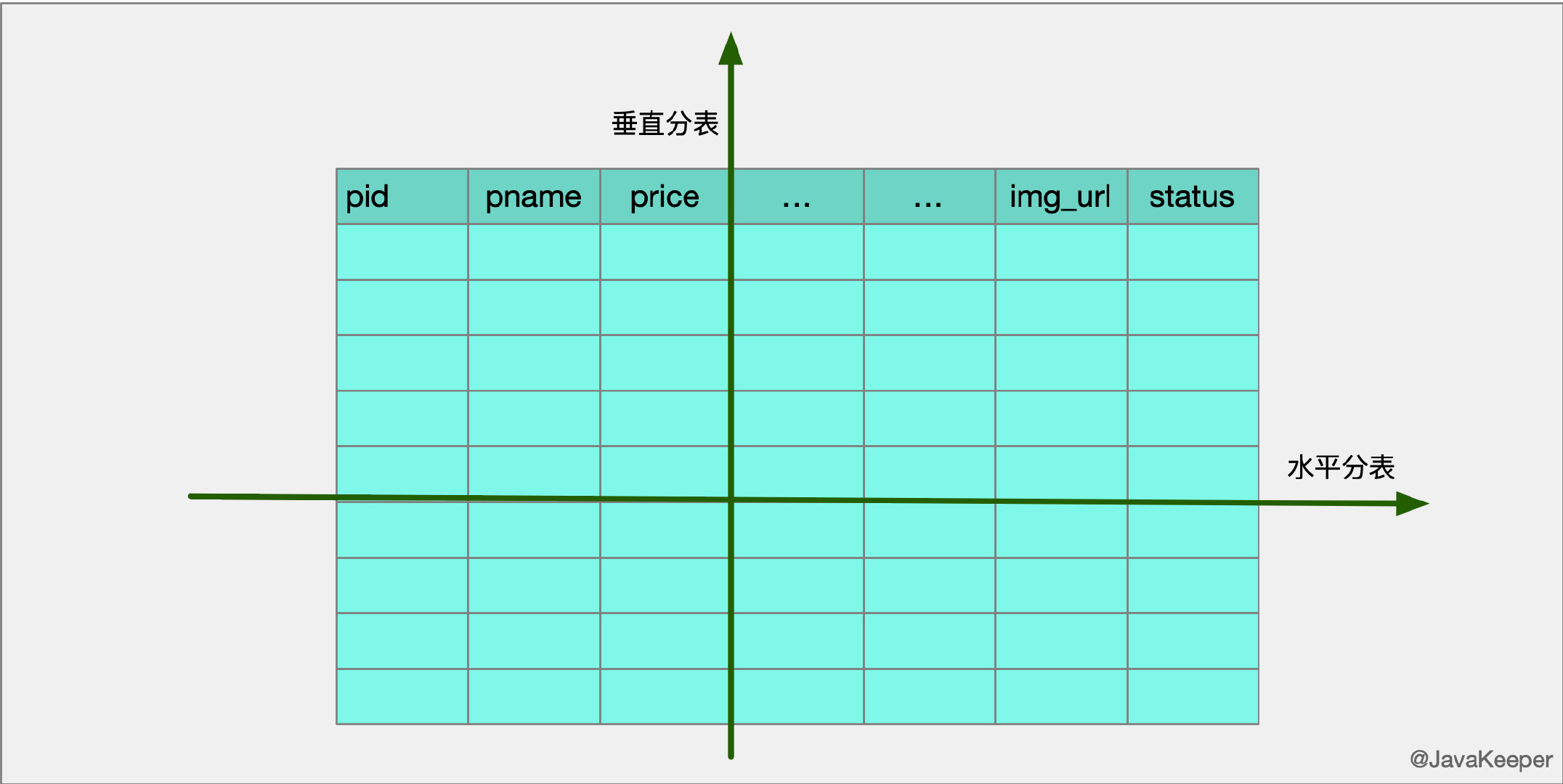
MySQL分表分表有两种分割方式,一种垂直拆分,另一种水平拆分。
垂直拆分
垂直分表,通常是按照业务功能的使用频次,把主要的、热门的字段放在一起做为主要表。然后把不常用的,按照各自的业务属性进行聚集,拆分到不同的次要表中;主要表和次要表的关系一般都是一对一的。
水平拆分(数据分片)
单表的容量不超过500W,否则建议水平拆分。是把一个表复制成同样表结构的不同表,然后把数据按照一定的规则划分,分别存储到这些表中,从而保证单表的容量不会太大,提升性能;当然这些结构一样的表,可以放在一个或多个数据库中。
水平分割的几种方法:
使用MD5哈希,做法是对UID进行md5加密,然后取前几位(我们这里取前两位),然后就可以将不同的UID哈希到不同的用户表(user_xx)中了。
还可根据时间放入不同的表,比如:article_201601,article_201602。
按热度拆分,高点击率的词条生成各自的一张表,低热度的词条都放在一张大表里,待低热度的词条达到一定的贴数后,再把低热度的表单独拆分成一张表。
根据ID的值放入对应的表,第一个表user_0000,第二个100万的用户数据放在第二 个表user_0001中,随用户增加,直接添加用户表就行了。
为什么要分库?
数据库集群环境后都是多台 slave,基本满足了读取操作; 但是写入或者说大数据、频繁的写入操作对master性能影响就比较大,这个时候,单库并不能解决大规模并发写入的问题,所以就会考虑分库。
分库是什么?
一个库里表太多了,导致了海量数据,系统性能下降,把原本存储于一个库的表拆分存储到多个库上, 通常是将表按照功能模块、关系密切程度划分出来,部署到不同库上。
优点:
减少增量数据写入时的锁对查询的影响
由于单表数量下降,常见的查询操作由于减少了需要扫描的记录,使得单表单次查询所需的检索行数变少,减少了磁盘IO,时延变短
但是它无法解决单表数据量太大的问题
分库分表后的难题
分布式事务的问题,数据的完整性和一致性问题。
数据操作维度问题:用户、交易、订单各个不同的维度,用户查询维度、产品数据分析维度的不同对比分析角度。 跨库联合查询的问题,可能需要两次查询 跨节点的count、order by、group by以及聚合函数问题,可能需要分别在各个节点上得到结果后在应用程序端进行合并 额外的数据管理负担,如:访问数据表的导航定位 额外的数据运算压力,如:需要在多个节点执行,然后再合并计算程序编码开发难度提升,没有太好的框架解决,更多依赖业务看如何分,如何合,是个难题。
配主从,正经公司的话,也不会让 Javaer 去搞的,但还是要知道
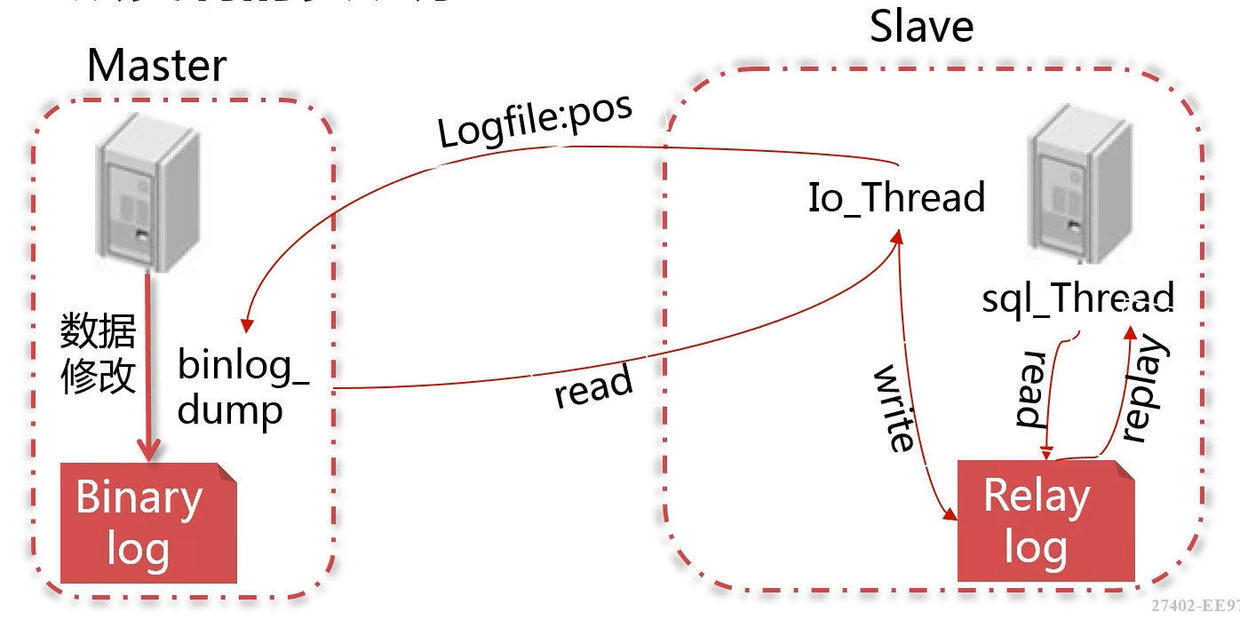
十、主从复制 复制的基本原理
slave 会从 master 读取 binlog 来进行数据同步
三个步骤
master将改变记录到二进制日志(binary log)。这些记录过程叫做二进制日志事件,binary log events;
salve 将 master 的 binary log events 拷贝到它的中继日志(relay log);
slave 重做中继日志中的事件,将改变应用到自己的数据库中。MySQL 复制是异步且是串行化的。
每个 slave只有一个 master
每个 salve只能有一个唯一的服务器 ID
每个master可以有多个salve
复制的最大问题延时
十一、其他问题 说一说三个范式第一范式(1NF):数据库表中的字段都是单一属性的,不可再分。这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。