
当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
MyISAM主键索引与辅助索引的结构MyISAM引擎的索引文件和数据文件是分离的。MyISAM引擎索引结构的叶子节点的数据域,存放的并不是实际的数据记录,而是数据记录的地址。索引文件与数据文件分离,这样的索引称为"非聚簇索引"。MyISAM的主索引与辅助索引区别并不大,只是主键索引不能有重复的关键字。
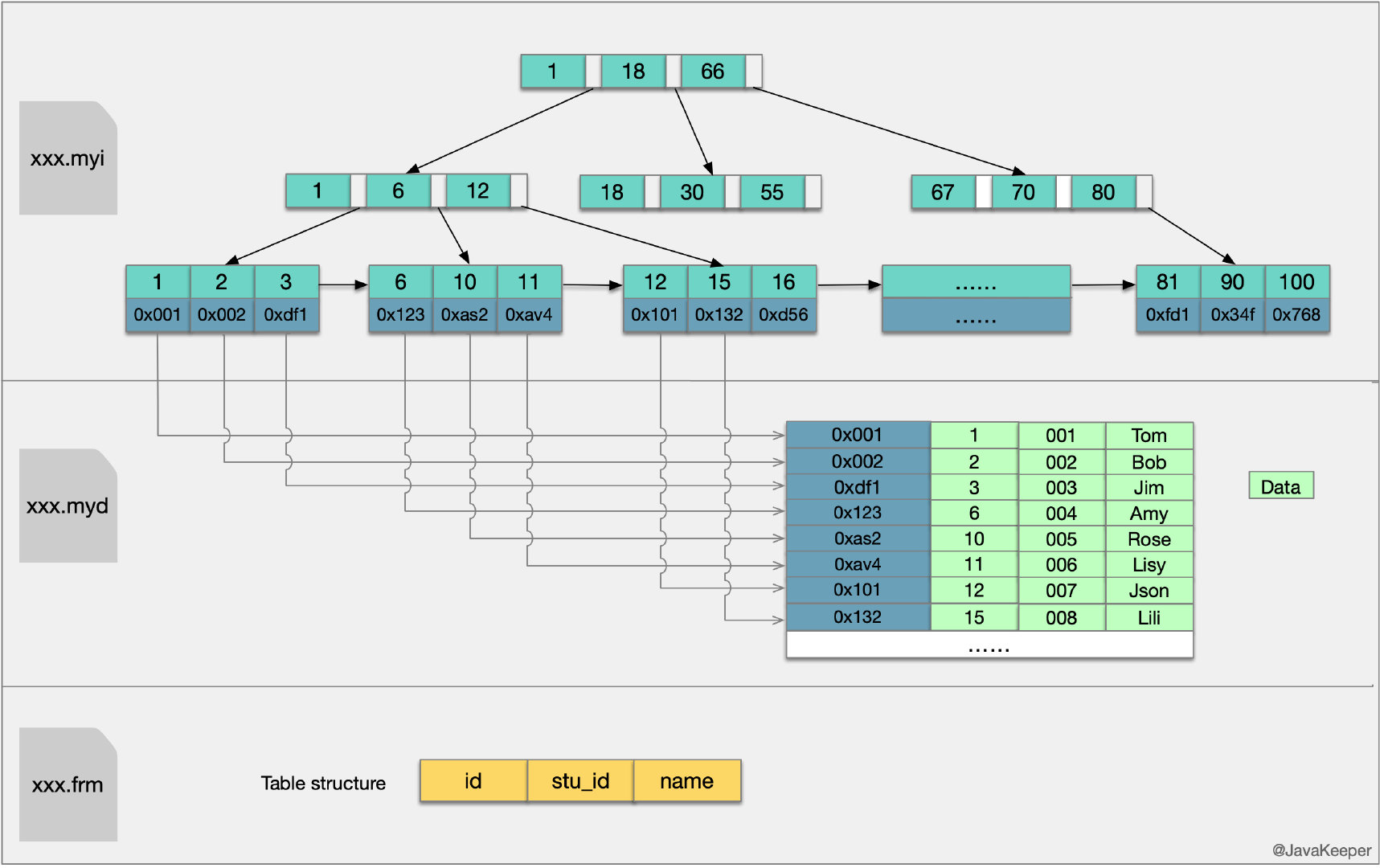
在MyISAM中,索引(含叶子节点)存放在单独的.myi文件中,叶子节点存放的是数据的物理地址偏移量(通过偏移量访问就是随机访问,速度很快)。
主索引是指主键索引,键值不可能重复;辅助索引则是普通索引,键值可能重复。
通过索引查找数据的流程:先从索引文件中查找到索引节点,从中拿到数据的文件指针,再到数据文件中通过文件指针定位了具体的数据。辅助索引类似。
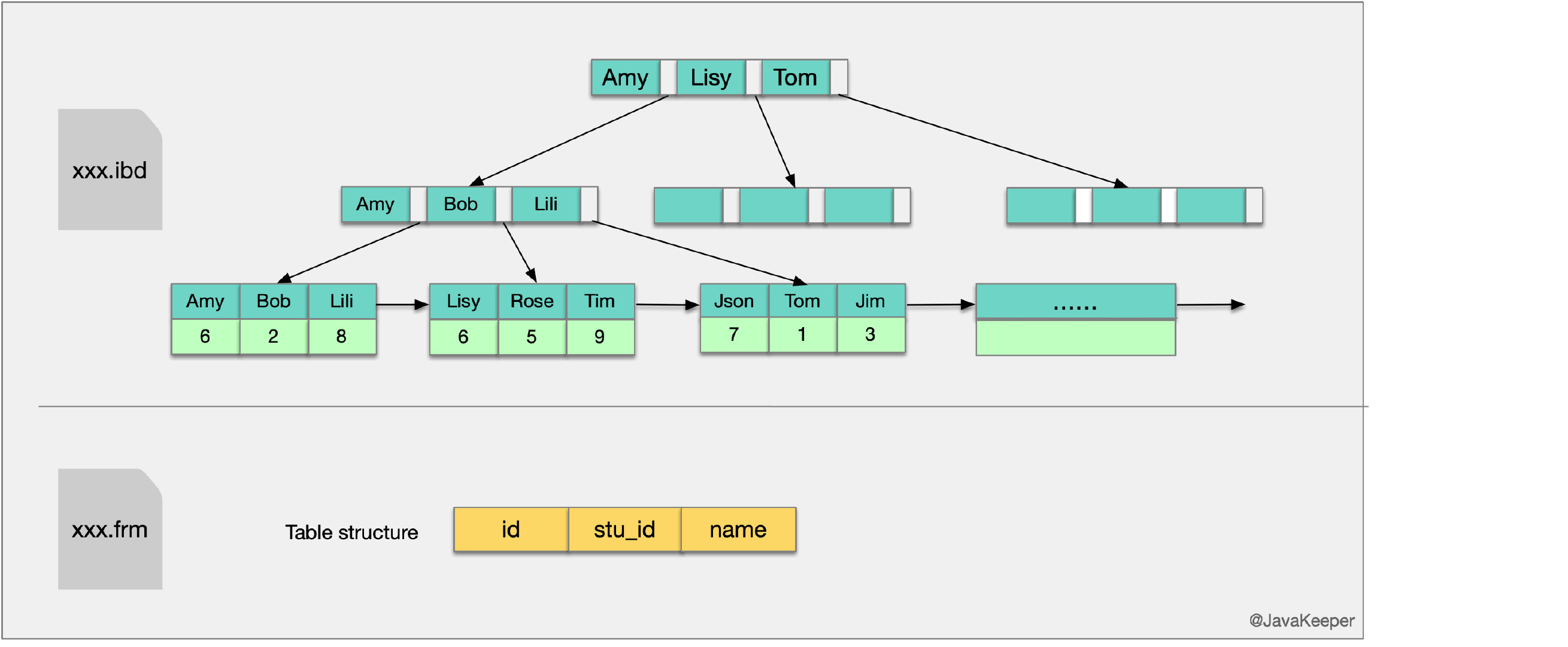
InnoDB主键索引与辅助索引的结构InnoDB引擎索引结构的叶子节点的数据域,存放的就是实际的数据记录(对于主索引,此处会存放表中所有的数据记录;对于辅助索引此处会引用主键,检索的时候通过主键到主键索引中找到对应数据行),或者说,InnoDB的数据文件本身就是主键索引文件,这样的索引被称为"“聚簇索引”,一个表只能有一个聚簇索引。
主键索引:我们知道InnoDB索引是聚集索引,它的索引和数据是存入同一个.idb文件中的,因此它的索引结构是在同一个树节点中同时存放索引和数据,如下图中最底层的叶子节点有三行数据,对应于数据表中的id、stu_id、name数据项。

在Innodb中,索引分叶子节点和非叶子节点,非叶子节点就像新华字典的目录,单独存放在索引段中,叶子节点则是顺序排列的,在数据段中。Innodb的数据文件可以按照表来切分(只需要开启innodb_file_per_table),切分后存放在xxx.ibd中,默认不切分,存放在xxx.ibdata中。
辅助(非主键)索引:这次我们以示例中学生表中的name列建立辅助索引,它的索引结构跟主键索引的结构有很大差别,在最底层的叶子结点有两行数据,第一行的字符串是辅助索引,按照ASCII码进行排序,第二行的整数是主键的值。
这就意味着,对name列进行条件搜索,需要两个步骤:
① 在辅助索引上检索name,到达其叶子节点获取对应的主键;
② 使用主键在主索引上再进行对应的检索操作
这也就是所谓的“回表查询”
InnoDB 索引结构需要注意的点
数据文件本身就是索引文件
表数据文件本身就是按 B+Tree 组织的一个索引结构文件
聚集索引中叶节点包含了完整的数据记录
InnoDB 表必须要有主键,并且推荐使用整型自增主键
正如我们上面介绍 InnoDB 存储结构,索引与数据是共同存储的,不管是主键索引还是辅助索引,在查找时都是通过先查找到索引节点才能拿到相对应的数据,如果我们在设计表结构时没有显式指定索引列的话,MySQL 会从表中选择数据不重复的列建立索引,如果没有符合的列,则 MySQL 自动为 InnoDB 表生成一个隐含字段作为主键,并且这个字段长度为6个字节,类型为整型。
那为什么推荐使用整型自增主键而不是选择UUID?
UUID是字符串,比整型消耗更多的存储空间;
在B+树中进行查找时需要跟经过的节点值比较大小,整型数据的比较运算比字符串更快速;