
InnoDB 中 count(*) 语句是在执行的时候,全表扫描统计总数量,所以当数据越来越大时,语句就越来越耗时了,为什么 InnoDB 引擎不像 MyISAM 引擎一样,将总行数存储到磁盘上?这跟 InnoDB 的事务特性有关,由于多版本并发控制(MVCC)的原因,InnoDB 表“应该返回多少行”也是不确定的。
三、数据类型主要包括以下五大类:
整数类型:BIT、BOOL、TINY INT、SMALL INT、MEDIUM INT、 INT、 BIG INT
浮点数类型:FLOAT、DOUBLE、DECIMAL
字符串类型:CHAR、VARCHAR、TINY TEXT、TEXT、MEDIUM TEXT、LONGTEXT、TINY BLOB、BLOB、MEDIUM BLOB、LONG BLOB
日期类型:Date、DateTime、TimeStamp、Time、Year
其他数据类型:BINARY、VARBINARY、ENUM、SET、Geometry、Point、MultiPoint、LineString、MultiLineString、Polygon、GeometryCollection等


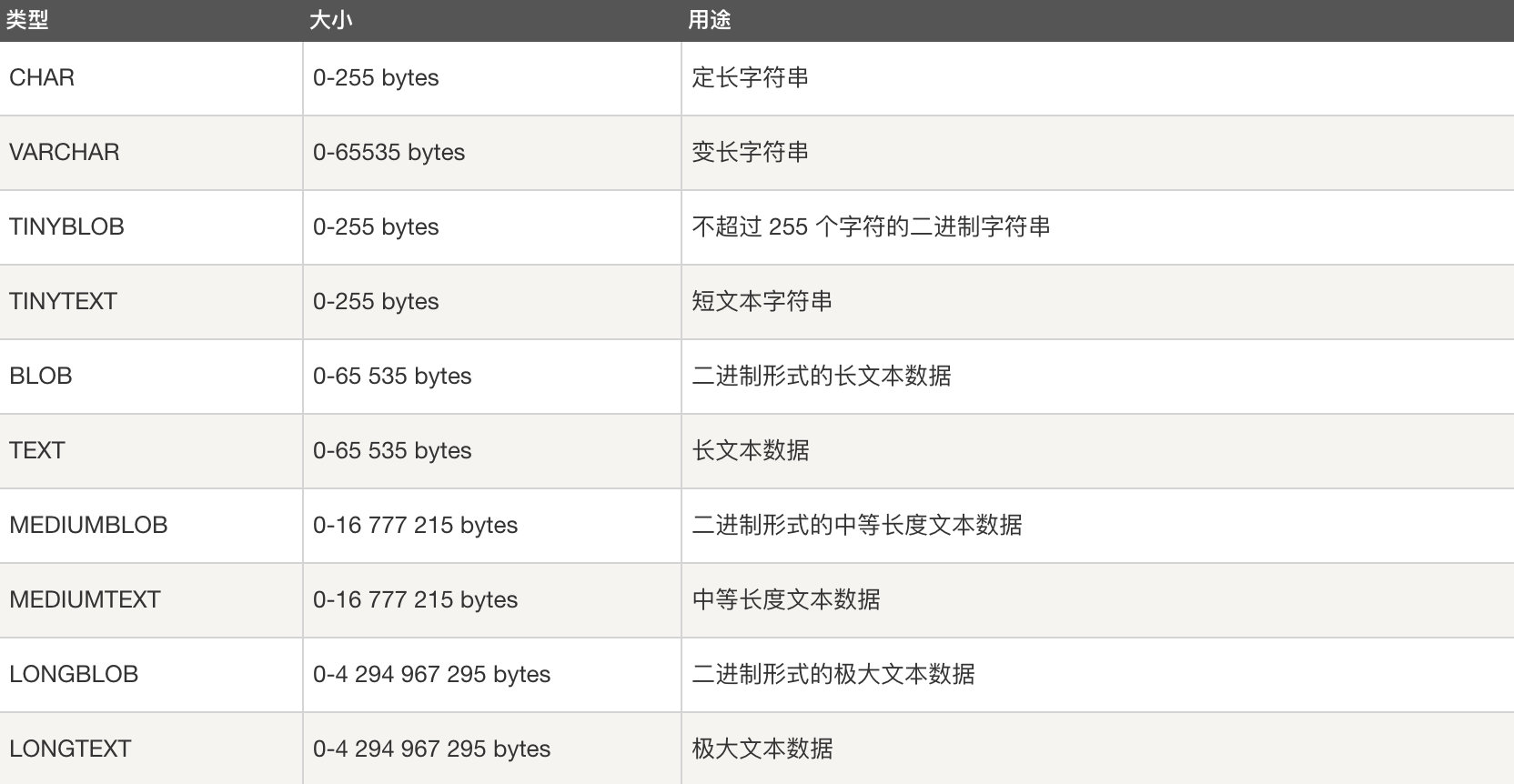
CHAR 和 VARCHAR 的区别?
char是固定长度,varchar长度可变:
char(n) 和 varchar(n) 中括号中 n 代表字符的个数,并不代表字节个数,比如 CHAR(30) 就可以存储 30 个字符。
存储时,前者不管实际存储数据的长度,直接按 char 规定的长度分配存储空间;而后者会根据实际存储的数据分配最终的存储空间
相同点:
char(n),varchar(n)中的n都代表字符的个数
超过char,varchar最大长度n的限制后,字符串会被截断。
不同点:
char不论实际存储的字符数都会占用n个字符的空间,而varchar只会占用实际字符应该占用的字节空间加1(实际长度length,0<=length<255)或加2(length>255)。因为varchar保存数据时除了要保存字符串之外还会加一个字节来记录长度(如果列声明长度大于255则使用两个字节来保存长度)。
能存储的最大空间限制不一样:char的存储上限为255字节。
char在存储时会截断尾部的空格,而varchar不会。
char是适合存储很短的、一般固定长度的字符串。例如,char非常适合存储密码的MD5值,因为这是一个定长的值。对于非常短的列,char比varchar在存储空间上也更有效率。
列的字符串类型可以是什么?
字符串类型是:SET、BLOB、ENUM、CHAR、CHAR、TEXT、VARCHAR
BLOB和TEXT有什么区别?
BLOB是一个二进制对象,可以容纳可变数量的数据。有四种类型的BLOB:TINYBLOB、BLOB、MEDIUMBLO和 LONGBLOB
TEXT是一个不区分大小写的BLOB。四种TEXT类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。
BLOB 保存二进制数据,TEXT 保存字符数据。
四、索引说说你对 MySQL 索引的理解?
数据库索引的原理,为什么要用 B+树,为什么不用二叉树?
聚集索引与非聚集索引的区别?
InnoDB引擎中的索引策略,了解过吗?
创建索引的方式有哪些?
聚簇索引/非聚簇索引,mysql索引底层实现,为什么不用B-tree,为什么不用hash,叶子结点存放的是数据还是指向数据的内存地址,使用索引需要注意的几个地方?
MYSQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构,所以说索引的本质是:数据结构
索引的目的在于提高查询效率,可以类比字典、 火车站的车次表、图书的目录等 。
可以简单的理解为“排好序的快速查找数据结构”,数据本身之外,数据库还维护者一个满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。下图是一种可能的索引方式示例。
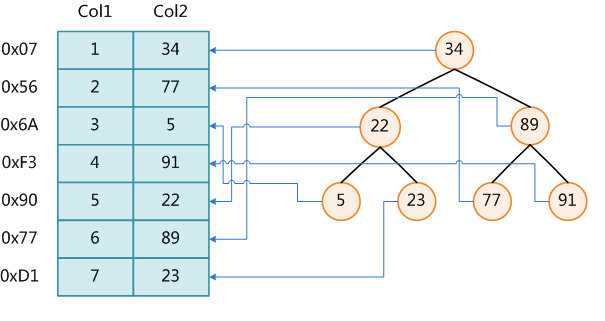
左边的数据表,一共有两列七条记录,最左边的是数据记录的物理地址
为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值,和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在一定的复杂度内获取到对应的数据,从而快速检索出符合条件的记录。
索引本身也很大,不可能全部存储在内存中,一般以索引文件的形式存储在磁盘上
平常说的索引,没有特别指明的话,就是B+树(多路搜索树,不一定是二叉树)结构组织的索引。其中聚集索引,次要索引,覆盖索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称索引。此外还有哈希索引等。
基本语法:
创建:
创建索引:CREATE [UNIQUE] INDEX indexName ON mytable(username(length));
如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。
修改表结构(添加索引):ALTER table tableName ADD [UNIQUE] INDEX indexName(columnName)
删除:DROP INDEX [indexName] ON mytable;
查看:SHOW INDEX FROM table_name\G --可以通过添加 \G 来格式化输出信息。
使用ALERT命令
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list): 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
ALTER TABLE tbl_name ADD UNIQUE index_name (column_list 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
ALTER TABLE tbl_name ADD INDEX index_name (column_list) 添加普通索引,索引值可出现多次。
ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list)该语句指定了索引为 FULLTEXT ,用于全文索引。
优势
提高数据检索效率,降低数据库IO成本
降低数据排序的成本,降低CPU的消耗
劣势索引也是一张表,保存了主键和索引字段,并指向实体表的记录,所以也需要占用内存