在当前设计当中有两个局限性:首先为了简单起见,使用了固定的TTL,这是为了保证返回结果的相对新鲜。第二,为了命中率和新鲜度,我们还在不断地去提高。总之,目前的解决方案还不能完美地解决这两方面的问题。
返回结果我们分析了一下,在一级缓存当中,它的命中率是小于20%的,在某些场景下甚至比20%还要低,就是为了保证更高的准确度和新鲜度。高优先度,一级缓存的TTL肯定是低于5分钟的,有一些场景下可能只有几十秒;然后我们还支持动态的刷新机制,整体的延迟是小于3毫秒的。在整个的运行过程中,可用性一直比较好。
(4)二级缓存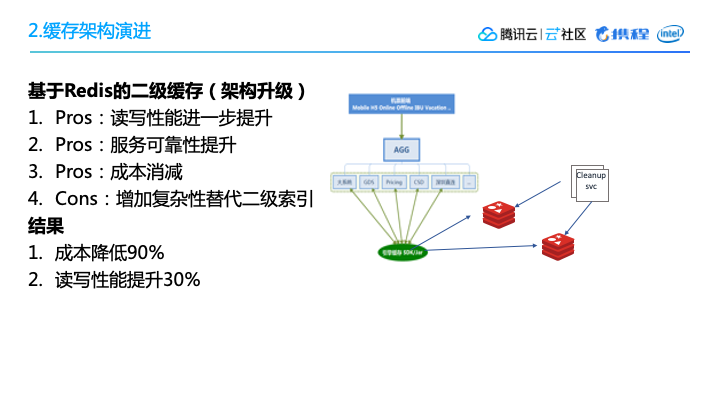
二级缓存一开始是采用了MongoDB,主要考虑到几个因素:首先,它的读写性能比较好,另外有一个比较重要因素是,它支持二级缓存。大家知道Redis其实就是一个KV这样的一个存储了。而在设计二级缓存的时候,为了支持多一点的功能,比如说为了能够很方便地做数据清理,就需要用到二级索引的功能。我们会计算出来一个相对较优的TTL,保证特定的数据有的可以缓存时间长一点,有的可以快速更新迭代。
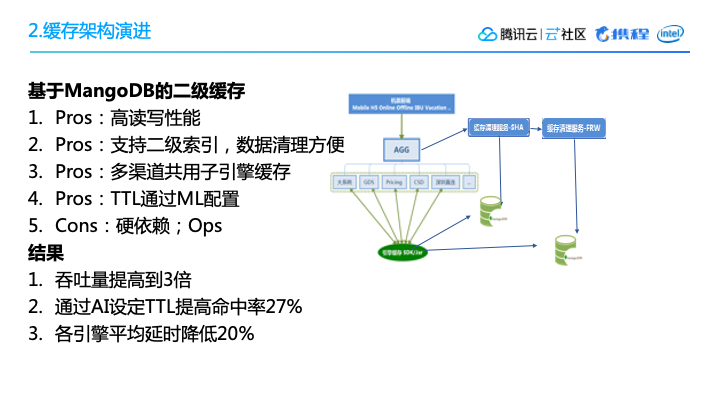
二级缓存基于MongoDB,也有一些局限性。首先,架构是越简单越好,多引入一种存储方式会增加维护的代价。其次,由于MongoDB整个的license的模式,会使得费用非常高的。
但是,二级缓存使得查询的整体吞吐量提高了三倍,通过机器学习设定的TTL,使得命中率提升了27%,各个引擎的平均延时降低了20%——这些对我们来说,是非常可喜的变化。在一个比较成熟的流量非常大的系统中,能有一个10%以上的提升,就是一个比较显著的技术特点。
针对MongoDB,我们也做了一个提升,最后把它切成Redis,通过我们的设计方案,虽然增加了一部分复杂性,但是替代了二级索引,这样一个改进的结果,成本降低了90%,读写性能提升了30%。
三、负载均衡的演进系统的首要目标是要满足高可用,其次是高流量支撑。我们可以通过多层的均衡路由实现把这些流量均匀分配到多个数据中心的多个集群中。
1. 目标
第三,需要降低事故影响范围,即使是在稳定的系统里也不能避免事故,但是当事故发生时,我们要使事故的影响范围尽可能的小。
第四,我们需要提升硬件资源的利用率,另外还会有一些长尾问题,比如个别查询的时间会特别的长,需要我们找到调度算法上的问题,然后一步步解决。
2. 负载均衡架构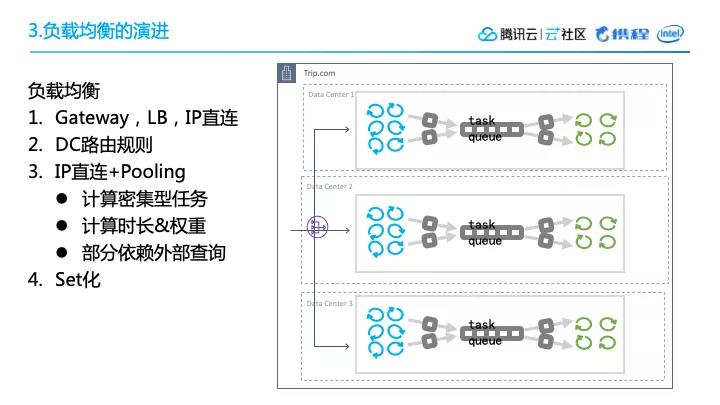
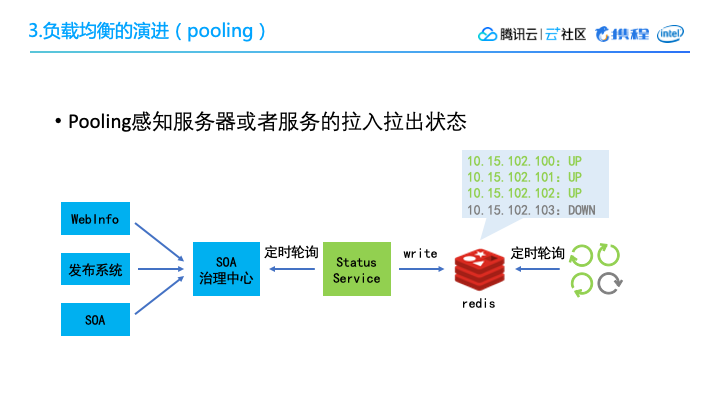
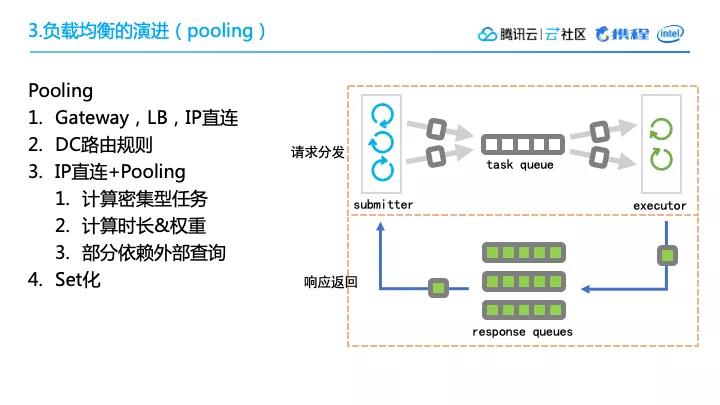
上图所示的是携程路由和负载均衡的架构,非常典型,有GateWay、load、balance、IP直连,在IP的基础上,我们实现了一项新的Pooling技术。
我们也实现了Set化,在同一个数据中心里,所有的服务都只和该数据中心的节点打交道,尽量减少跨地区的网络互动。
3. Pooling为什么要做 Pooling 呢?因为前文提到了我们有一些计算非常密集的引擎,存在一些耗时长,耗费CPU资源比较多的子任务,同时这些子任务中可能夹杂着一些实时请求,所以这些任务可能会留在线程里边,阻塞整个流程。
Pooling 要做的事情就是:我们把这些子任务放在queue里边,将节点作为worker,总是动态的去取,每次只取一个,计算完了要么把结果返回,要么把中间结果再放回queue。这样的话如果有任何实时的外部调用,我们就可以把它分成多次,放进queue进行task的整个提交执行和应用结果的返回。
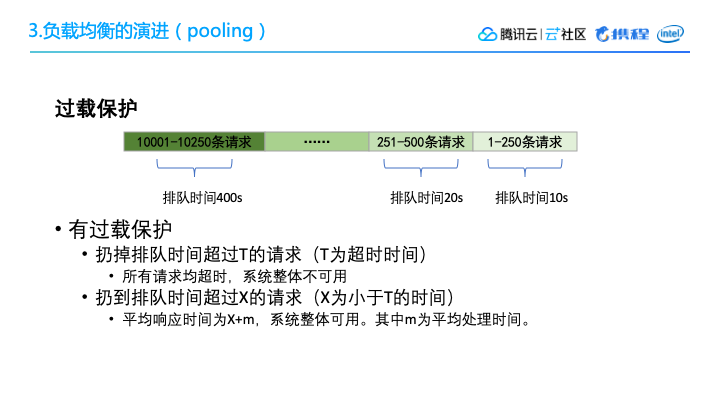
在 Pooling 的设计当中,我们需要设计一个过载保护,当流量实在太高的情况下,可以采用一个简单的过载保护,把等待时间超过某一个阈值的请求全都扔掉。当然这个阈值肯定是小于谈话时间的,这样就能保证我们整个的 Pooling 服务是高可用的。
虽然我们可能会过滤掉一些请求,但是大家可以想象一下,如果没有过载保护,很容易就会发生滚雪球效应,queue里面的任务越来越多,当系统取到一个任务的时候,实际上它的原请求可能早就已经timeout了。