
下图所示的是压测结果,大家可以看到,在达到我们系统的极限值之前,有Pooling 和没Pooling两种情形下的负载均衡差异。比如在80%负载下,不采用Pooling的排队时间会比有Pooling的情况下高出10倍。
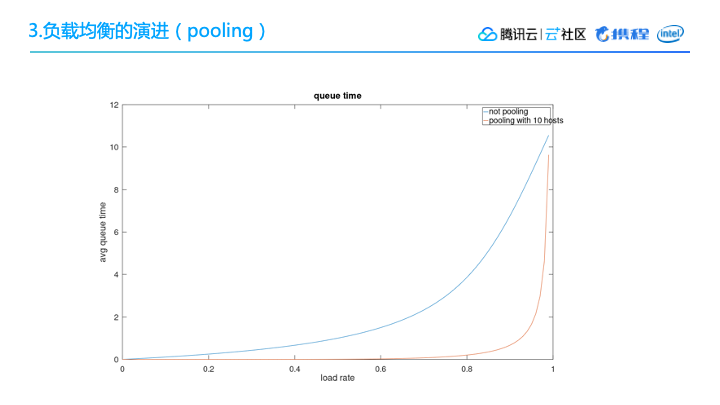
所以对于一些面临相同流量问题的互联网厂家,可以考虑把 Pooling 作为自己的一个动态调度,或者作为一个control plan的改进措施。
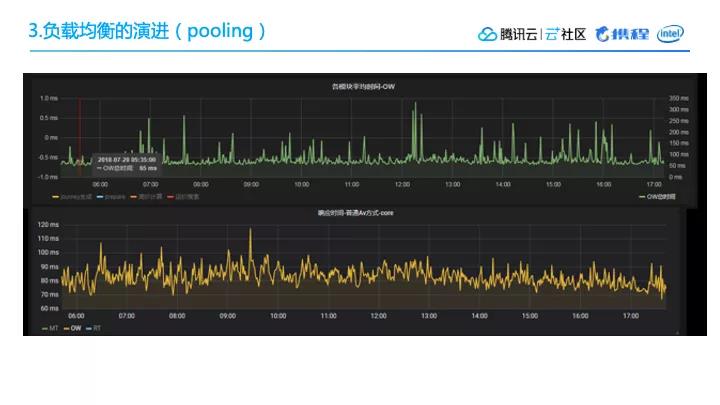
如下图所示,我们实现了 Pooling 之后平均响应时间基本没有大的变化,还是单层查询计算普遍需要六七十毫秒。但是实现了 Pooling 之后,有一个显著的变化是键值变少了,键值的范围也都明显控制在平均时间的两倍以内。这对于我们这样大体量的服务来说,比较平顺曲线正是我们所需要的。
这里我列出了使用效果比较好的几个AI应用场景。
1. 应用场景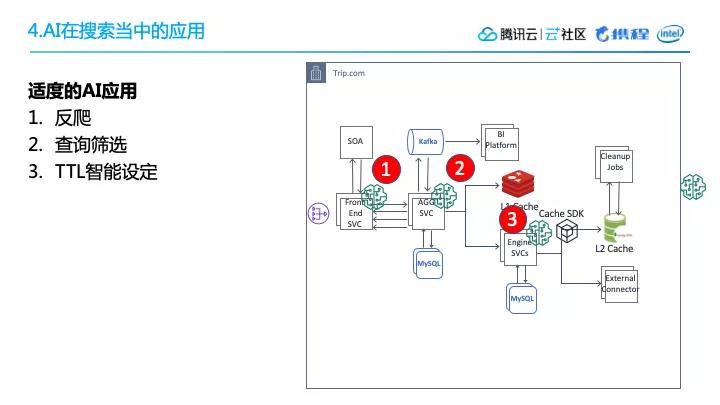
(1)反爬
在前端,我们设定了智能反爬,能帮助屏蔽掉9%的流量。
(2)查询筛选
在聚合服务中,我们并会把所有请求都压到子系统,而是会进行一定的模式运营,找出价值最高实际用户,然后把他们的请求发到引擎当中。对于一些实际价值没有那么高的,更多的是用缓存,或者屏蔽掉一些比较昂贵的引擎。
(3)TTL智能设定
之前已经提到,整个TTL的设定,使用了机器学习技术。以上就是我们AI应用在搜索场景中效果最好的三个。
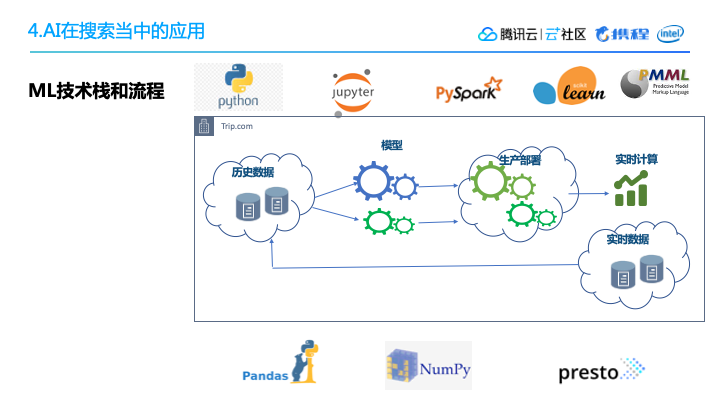
2. ML技术栈和流程ML的整个技术栈,还有我们的模型训练流程,如下图所示。
这里讲一下AI的一个具体场景,就是过滤请求。
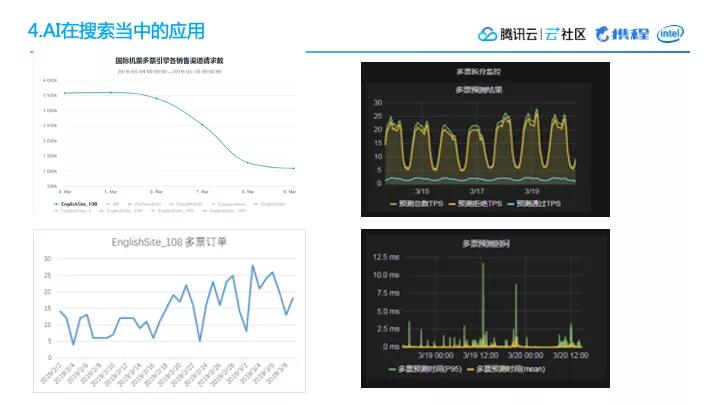
我们有一个非常开销非常大的子引擎,叫多票。它会把多个不同航空公司的出票拼接起来,返回给最终用户。但是,它的拼接计算非常昂贵,所以只对一部分产品开放。我们通过机器学习找到了哪些查询可以通过多票引擎得到最好的结果,然后只对这一部分查询用户开放,结果显示非常好。
大家可以看PPT右上角的图片,我们整个引擎能够过滤掉超过80%的请求,在流量高峰的时候,它能把曲线变得平滑起来,非常显著。整个对于查询结果、订单数,都没有太大的影响,而且节省了80%的产品资源。同时,可以看到这种线上模型,它的运算时间也是非常短的,普遍低于1毫秒。
五、总结
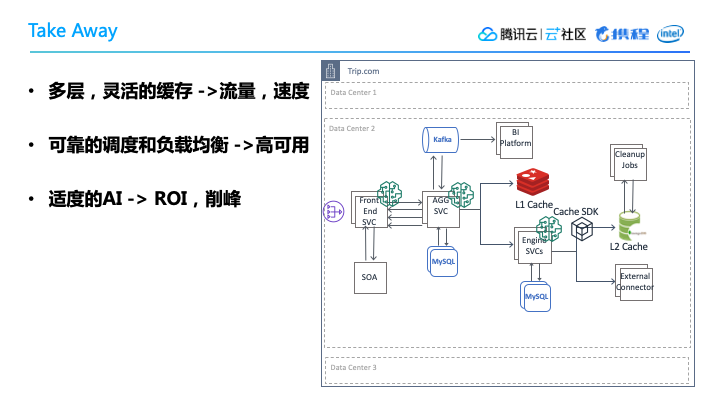
最后对这次的分享做总结,希望能够给大家带来一点点启发。我们使用了多层灵活的缓存,从而能很好的应对高流量的冲击,提高反应速度。
另外我们使用了比较可靠的调度和负载均衡,这样就使我们的服务保持高可用状态,并且解决了长尾的查询延迟问题。
最后我们在携程内部尝试了很多技术革新,将适度的AI技术推向生产,从目前来看,机器学习发挥了很好的效果。带来了ROI的提升,节省了效率,另外在流量高峰中,它能够起到很好的削峰作用。
以上就是我们为应对高流量洪峰所采取了一系列有针对性的架构改善。
Q:在哪些场景下使用缓存?
A:所有的场景都要考虑使用缓存。在高流量的情况下,每一级缓存都能带来很好的保护系统,提高性能的效果,但是一定要考虑到缓存失效时的应对措施。
Q:缓存的迭代过程是怎样的?
A:如前文所述,我们先有L1,然后又加了L2,主要是因为我们的流量越来越大,引擎的外部依赖逐渐撑不住了,所以我们不得不把中间结果也高效的缓存起来,这就是我们L1到L2的演进过程。在二级缓存我们用Redis替代了MongoDB,是出于高可用性的考虑,当然费用的节省也是当时考虑的一个因素,但是更主要的我们发现了自运维的MongoDB比Redis,它的整体可用性要差很多,所以最后决定做了切换。
Q:分布式缓存的设计方式?