
携程机票查询系统,日均20亿流量,且要求高吞吐,低延迟的架构设计。于是,提升缓存的效率以及实时计算模块长尾延迟,成为制约机票查询系统性能的关键。本文是携程集团机票业务技术总监宋涛在「云加社区沙龙online」的分享整理,着重介绍了携程机票查询系统在缓存和实时计算两个领域的架构提升。
携程是OTA行业内首屈一指的互联网企业,而在携程内部,机票搜索又是使用最频繁的服务(没有之一)。所以,我们所面对的一些技术问题,可能会对很多中型企业有一些借鉴作用,希望今天的分享能给大家带来一些收获。
点击视频,查看完整直播回放
一、 机票搜索服务概述 1. 携程机票搜索的业务特点首先简单介绍一下机票的搜索业务:大家可能都用过携程,当你去输入目的地,然后点击搜索的时候,我们的后台就开始了紧张的工作。我们基本上会在一两秒的时间,将最优的结果反馈给用户。这个业务存在以下业务特点。

(1)高流量、低延时、高成功率
首先,我们不得不面对非常高的流量,同时,我们对搜索结果要求也很高——成功率要高,不能说查询失败,或者强说成功,我们希望能够反馈给用户最优质最新鲜的数据。
(2)多引擎聚合,SLA不一
携程机票搜索的数据来源于哪儿呢?有很大一部分结果来源于我们自己的机票运价引擎。除此之外,为了补充产品丰富性,我们还引入了国际上的一些GDS、SLA,比如我们说的联航。我们将外部的引擎,和我们自己的引擎结果聚合之后发送给大家。
(3)计算密集&IO密集
大家可能会意识到,我说到我们自己的引擎就是基于一些运价的数据、仓位的数据,还有其他一些航班的信息,我们会计算、比对、聚合,这是一个非常技术密计算密集型的这么一个服务。同时呢,外部的GDS提供的查询接口或者查询引擎,对我们来说又是一个IO密集型的子系统。我们的搜索服务要将这两种不同的引擎结果很好地聚合起来。
(4)不同业务场景的搜索结果不同要求
携程作为一个非常大的OTA,还会支持不同的应用场景。例如,同样是北京飞往上海,由于设定的搜索条件或搜索渠道不一样,返回的结果会有一些不同。比如,有的客户是学生,可能就搜到学生的特价票,而其他的用户则看不到这个信息。
总体来说,每天的查询量是20亿次,这是一个平均的查询量。其中经过鉴定,9%的查询量来自于爬虫,这其中有一些恶意爬虫,也有一些是出于获取信息目的的爬虫,可能来自于其他的互联网厂商。对于不同的爬虫,我们会有不同的应对策略。
在有效查询当中,大概有28%是来自国际客户,然后有63%属于中文客户。携程的国际客户,特别是机票业务,所占有的比重越来越多。
2. 携程基础设施(Infrastructure)建设情况好,接下来就简单介绍一下,就是为了应对这样的业务特点,我们有哪些武器呢?
(1)三个独立的数据中心
携程目前有三个独立的数据中心。他们是可以互相做灾备的,就在两天前,我们有一个比较盛大的庆祝会,经过差不多一年的系统提升和演练。我们实现了其中一个数据中心完全宕机的情况下,携程的业务不会受到影响。这个我们给他起了一个很fashion的名字叫流浪地球。我也代表我们机票业务领到了一个团体贡献奖。
(2)技术栈
讲一下我们的DataCenter大概的技术栈。可能跟很多的互联网厂商一样,我们是用了SpringCloud+K8s+云服务(海外),这里感谢Netflix无私的开源项目,其实支撑了很多互联网的基础设施部门,不然,大家可能还要摸索很长时间才能达到同样的效果。
(3)基于开源的DevOps
我们基于开源做了整套的DevOps工具和框架。
(4)多种存储方案
在携程内部有比较完善可用度比较高的存储方案,包括MySQL,Redis,MangoDB……
(5)网络可靠性
携程非常注重网络的可靠性,做了很多DR的开发,做了很多SRE实践,广泛推动了熔断,限流等等,以保证我们的用户得到最高质量的服务。
3. 携程搜索服务的架构这里我简单画了一下携程机票搜索服务的架构,如下图所示。
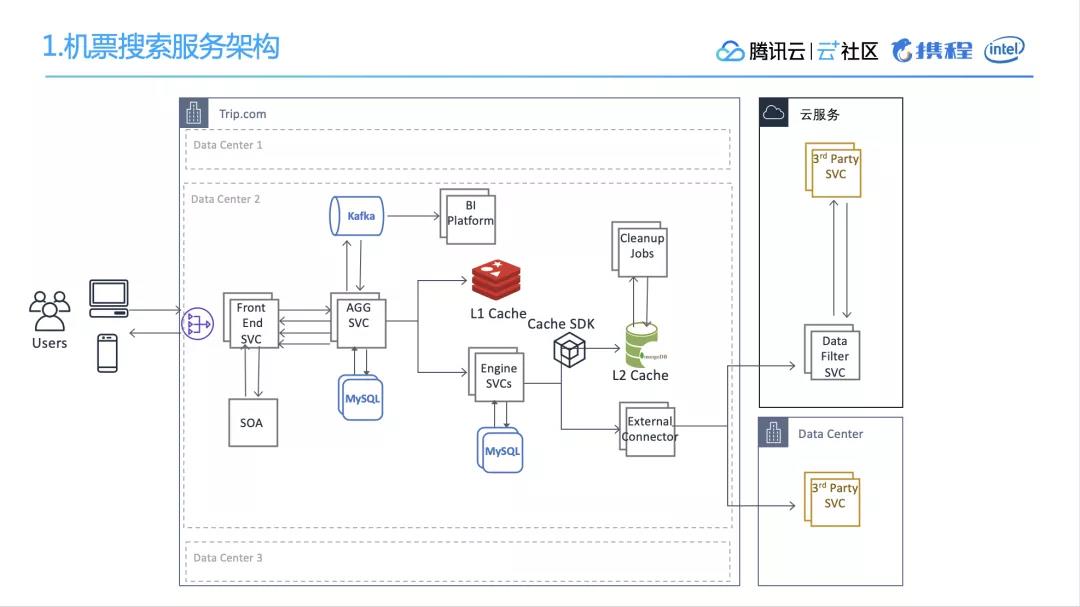
我们的数据中心有三个,中间部分可以看到,我们首先引入了GateWay分流前端的服务,前端的服务通过服务治理,可以和后端聚合服务进行交互。聚合服务再调用很多的引擎服务,在这儿大家看出可以看到非常熟悉的Redis的图标,这就是我们广泛使用的分布式缓存。