
缓存的具体细节下文会讲到。我们聚合服务的结果,可以通过Kafka推送到我们的AI数据平台,会做一些大数据的分析、流量回放,还有其他的一些数据相关的操作。在图中trip.com框的右边,我们还专门在云上部署了数据的过滤服务,使得传回的数据减少了90%,这是我们的data Center的介绍。
二、缓存架构的演进 1. 缓存的挑战和策略 (1)为什么大量使用缓存应对流量高峰?在流量高下为什么要使用缓存?其实有过实战经验的同学都知道,缓存是提高效率、提升速度,首先需要考虑的一种技术手段。

对于我们来说,为什么要大量使用缓存?
首先,我们虽然使用了很多比较流行的开源技术,但是我们还是有一些瓶颈的。比如,虽然我们的数据库是分片的、高可用的的MySQL,但是它跟一些比较流行的云存储、云数据库相比,它的带宽、存储量、可用性还是有一定差距,所以我们通常情况下需要使用缓存来保护我们的数据库,不然频繁的读取会使得数据库很快超载。
另外,我们有比较多的外部依赖,它们提供给我们的带宽,QPS也是很有限的。携程的整整业务量是快速增长的,而外部的业务伙伴给我们的带宽,要么已经达到了他们的技术瓶颈,要么开始收非常高的费用。在这种情况下,使用缓存就可以保护外部的一些合作伙伴,不至于把他们系统给击穿,另外也可以帮我们节省一些费用。
(2)本地缓存 VS 分布式缓存在整个携程架构的演进的过程当中,一开始本地缓存比较多的,后来部分用到分布式缓存,然后占比越来越高。
本地缓存主要有两个问题:一个启动的时候,它会有一个冷启动的过程,这对快速部署是非常不利的。另外一个问题是,与分布式缓存相比,本地缓存的命中率实在是太低了。对于我们海量的数据而言,单机所能提供的命中率非常低,低到5%甚至更低。
在这种情况下,我们现在已经几乎全面切向了分布式缓存。现在我们的分布式缓存解决方案是Redis分布式缓存,总体而言,现在携程可用性和容错性都是比较高的。
我们在设计当中,本着对战failure的这么一个理念,我们也不得不考虑失败的场景。万一集群挂掉了,或者它的一部分分片挂掉了,这时候需要通过限流客户端、熔断等方式,防止它的雪崩效应,这是在我们设计当中需要注意到的。
(3)TTL设置还有一点需要强调的,TTL生命周期设置的时候需要花一点心思,这也是跟业务密切相关的。
买机票经常有这种场景:刚刚看到一个低价机票,点进去就没有了。这种情况出现的原因可能是什么呢?大家知道,航空公司的低价舱位票,一次可能就只放出来几张,如果是热门航线,可能同时有几百人在查询。所以,几百人都可能会看到这几张票,它就会出现在缓存里边。如果已经有10个人去订了票,其他人看到缓存再点进去,运价就已经失效了。
这种情况就要求有一个权衡,不能片面追求高命中率,还要兼顾数据新鲜度。所以,为了保证新鲜度、数据准确性,我们还会有大量的定时工作去做更新和清理。
2. 缓存架构演进接下来讲一下缓存架构的演进。
(1)多级缓存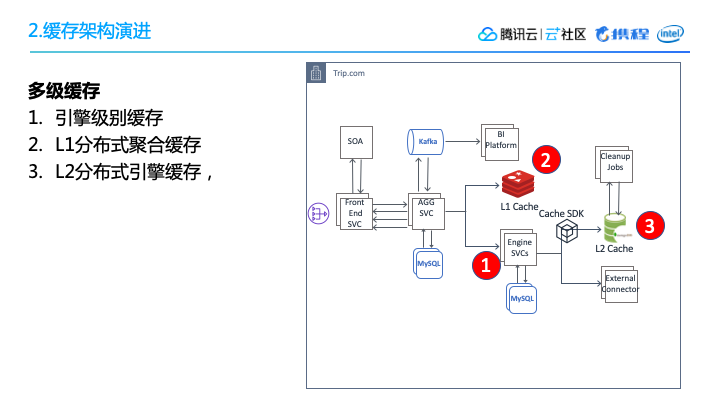
这里我举了三处缓存:
子引擎级别的缓存。
L1分布式聚合缓存,L1聚合缓存基本上就是我们用户看到的最终查询结果。
L2二级缓存,二级缓存是分布式的子引擎的结果。
如果聚合服务需要多个返回结果的话,那么很大程度上都是先读一级缓存,一级缓存没有命中的话,再从二级缓存里面去读中间结果,这样可以快速聚合出一个大家所需要的结果返回。
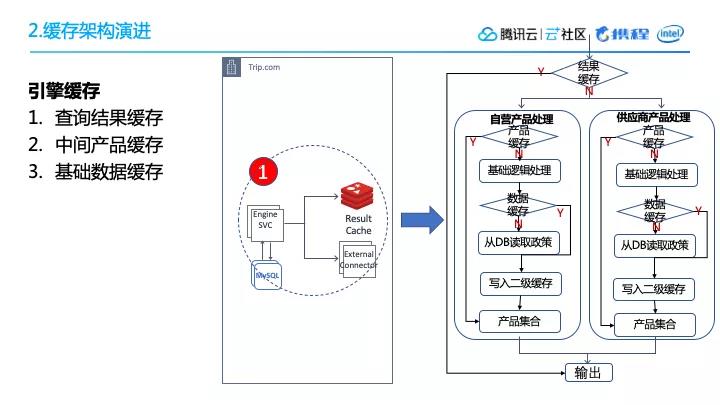
(2)引擎缓存我们使用了一个多级的缓存模式。如下右图所示,最顶部的是我们指引前的结果缓存,储存在Redis中,在引擎内部,往往根据产品、供应商,会有多个渠道的中间结果,所以对我们的子引擎来说会有一个中间缓存。这些中间结果的计算,需要数据,这个数据就来自上文提到的最基础的一级缓存。
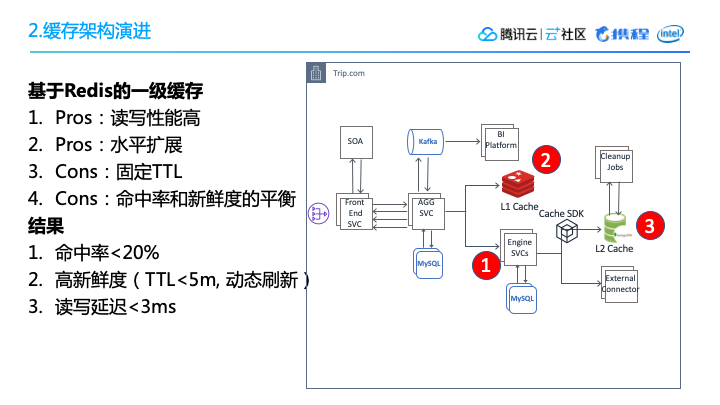
一级缓存使用了Redis,主要考虑到它读写性能好,快速,水平扩展性能,能够提高存储量以及带宽。