
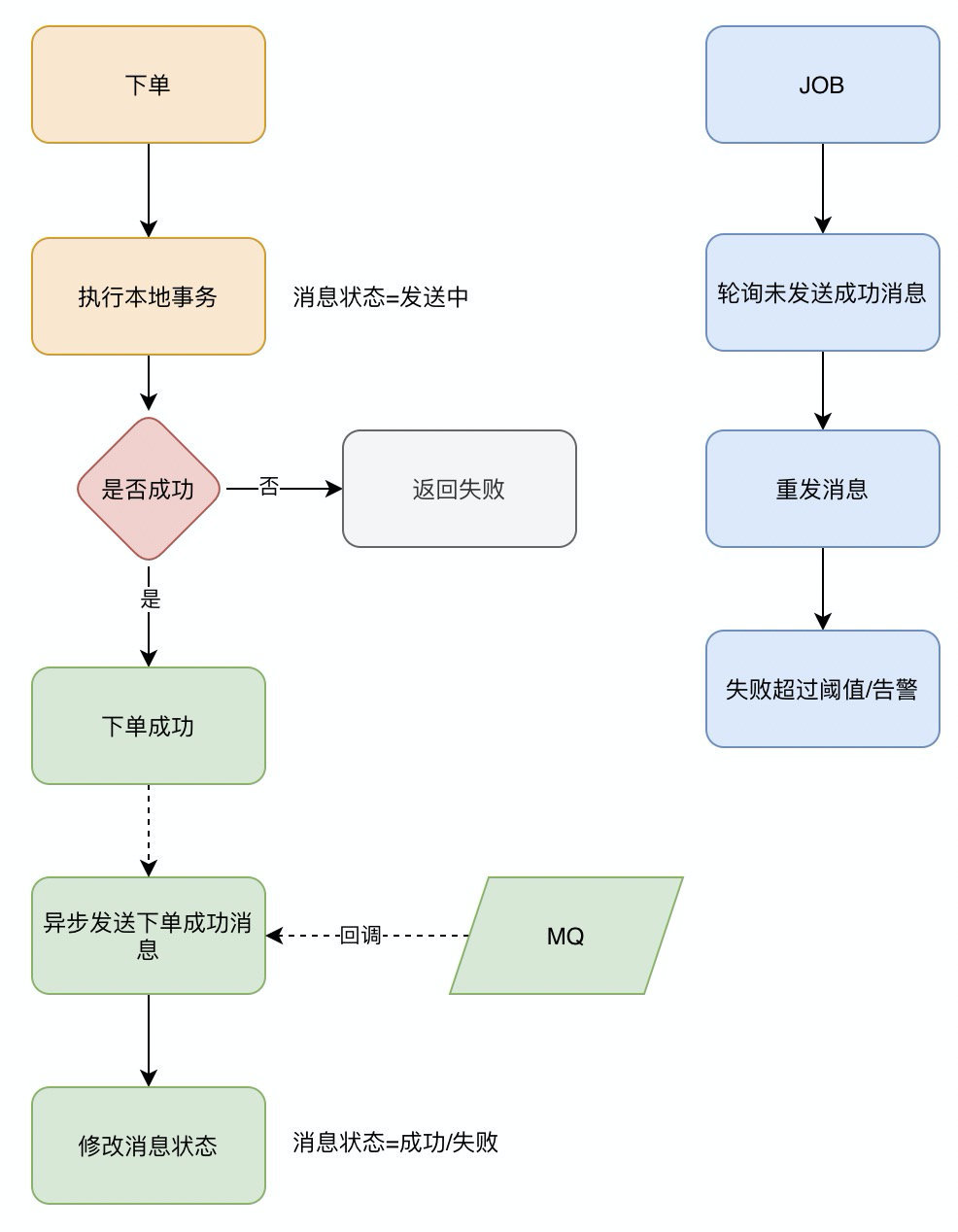
在监控平台配置或者JOB程序处理超过一定次数一直发送不成功的消息,告警,人工介入。
MQ丢失
如果生产者保证消息发送到MQ,而MQ收到消息后还在内存中,这时候宕机了又没来得及同步给从节点,就有可能导致消息丢失。
比如RocketMQ:
RocketMQ分为同步刷盘和异步刷盘两种方式,默认的是异步刷盘,就有可能导致消息还未刷到硬盘上就丢失了,可以通过设置为同步刷盘的方式来保证消息可靠性,这样即使MQ挂了,恢复的时候也可以从磁盘中去恢复消息。
比如Kafka也可以通过配置做到:
acks=all 只有参与复制的所有节点全部收到消息,才返回生产者成功。这样的话除非所有的节点都挂了,消息才会丢失。replication.factor=N,设置大于1的数,这会要求每个partion至少有2个副本
min.insync.replicas=N,设置大于1的数,这会要求leader至少感知到一个follower还保持着连接
retries=N,设置一个非常大的值,让生产者发送失败一直重试
虽然我们可以通过配置的方式来达到MQ本身高可用的目的,但是都对性能有损耗,怎样配置需要根据业务做出权衡。
消费者丢失
消费者丢失消息的场景:消费者刚收到消息,此时服务器宕机,MQ认为消费者已经消费,不会重复发送消息,消息丢失。
RocketMQ默认是需要消费者回复ack确认,而kafka需要手动开启配置关闭自动offset。
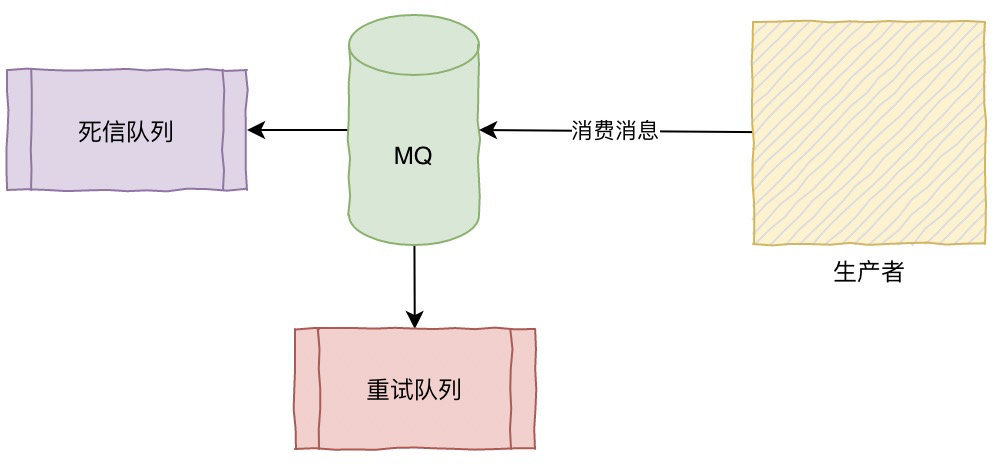
消费方不返回ack确认,重发的机制根据MQ类型的不同发送时间间隔、次数都不尽相同,如果重试超过次数之后会进入死信队列,需要手工来处理了。(Kafka没有这些)
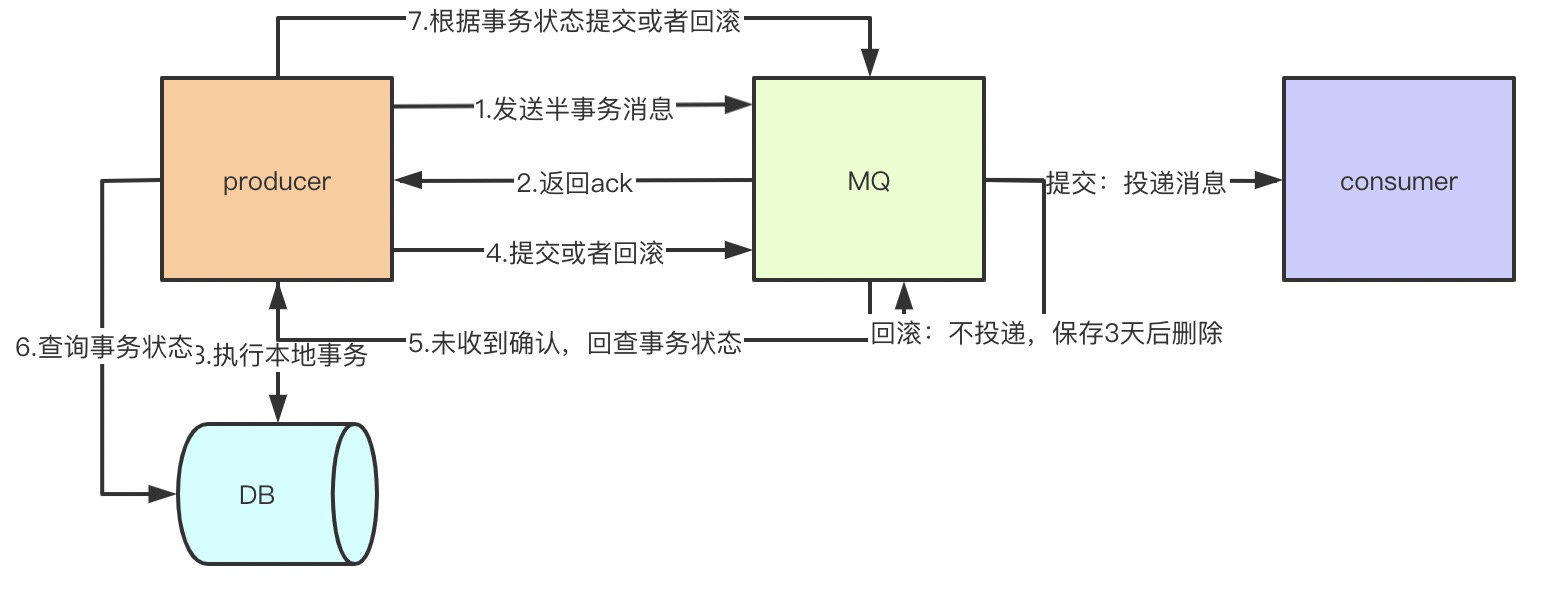
事务消息可以达到分布式事务的最终一致性,事务消息就是MQ提供的类似XA的分布式事务能力。
半事务消息就是MQ收到了生产者的消息,但是没有收到二次确认,不能投递的消息。
实现原理如下:
生产者先发送一条半事务消息到MQ
MQ收到消息后返回ack确认
生产者开始执行本地事务
如果事务执行成功发送commit到MQ,失败发送rollback
如果MQ长时间未收到生产者的二次确认commit或者rollback,MQ对生产者发起消息回查
生产者查询事务执行最终状态
根据查询事务状态再次提交二次确认
最终,如果MQ收到二次确认commit,就可以把消息投递给消费者,反之如果是rollback,消息会保存下来并且在3天后被删除。
对于整个系统而言,最终所有的流量的查询和写入都落在数据库上,数据库是支撑系统高并发能力的核心。怎么降低数据库的压力,提升数据库的性能是支撑高并发的基石。主要的方式就是通过读写分离和分库分表来解决这个问题。
对于整个系统而言,流量应该是一个漏斗的形式。比如我们的日活用户DAU有20万,实际可能每天来到提单页的用户只有3万QPS,最终转化到下单支付成功的QPS只有1万。那么对于系统来说读是大于写的,这时候可以通过读写分离的方式来降低数据库的压力。

读写分离也就相当于数据库集群的方式降低了单节点的压力。而面对数据的急剧增长,原来的单库单表的存储方式已经无法支撑整个业务的发展,这时候就需要对数据库进行分库分表了。针对微服务而言垂直的分库本身已经是做过的,剩下大部分都是分表的方案了。
水平分表首先根据业务场景来决定使用什么字段作为分表字段(sharding_key),比如我们现在日订单1000万,我们大部分的场景来源于C端,我们可以用user_id作为sharding_key,数据查询支持到最近3个月的订单,超过3个月的做归档处理,那么3个月的数据量就是9亿,可以分1024张表,那么每张表的数据大概就在100万左右。
比如用户id为100,那我们都经过hash(100),然后对1024取模,就可以落到对应的表上了。
分表后的ID唯一性因为我们主键默认都是自增的,那么分表之后的主键在不同表就肯定会有冲突了。有几个办法考虑:
设定步长,比如1-1024张表我们分别设定1-1024的基础步长,这样主键落到不同的表就不会冲突了。
分布式ID,自己实现一套分布式ID生成算法或者使用开源的比如雪花算法这种