

针对这个问题,加一层布隆过滤器。布隆过滤器的原理是在你存入数据的时候,会通过散列函数将它映射为一个位数组中的K个点,同时把他们置为1。
这样当用户再次来查询A,而A在布隆过滤器值为0,直接返回,就不会产生击穿请求打到DB了。
显然,使用布隆过滤器之后会有一个问题就是误判,因为它本身是一个数组,可能会有多个值落到同一个位置,那么理论上来说只要我们的数组长度够长,误判的概率就会越低,这种问题就根据实际情况来就好了。

当某一时刻发生大规模的缓存失效的情况,比如你的缓存服务宕机了,会有大量的请求进来直接打到DB上,这样可能导致整个系统的崩溃,称为雪崩。雪崩和击穿、热key的问题不太一样的是,他是指大规模的缓存都过期失效了。
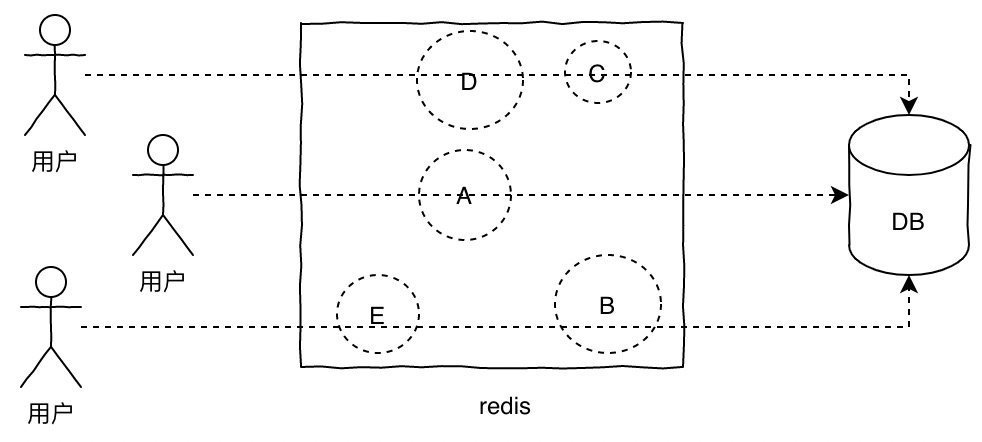
针对雪崩几个解决方案:
针对不同key设置不同的过期时间,避免同时过期
限流,如果redis宕机,可以限流,避免同时刻大量请求打崩DB
二级缓存,同热key的方案。
稳定性
熔断
比如营销服务挂了或者接口大量超时的异常情况,不能影响下单的主链路,涉及到积分的扣减一些操作可以在事后做补救。
限流
对突发如大促秒杀类的高并发,如果一些接口不做限流处理,可能直接就把服务打挂了,针对每个接口的压测性能的评估做出合适的限流尤为重要。
降级
熔断之后实际上可以说就是降级的一种,以熔断的举例来说营销接口熔断之后降级方案就是短时间内不再调用营销的服务,等到营销恢复之后再调用。
预案
一般来说,就算是有统一配置中心,在业务的高峰期也是不允许做出任何的变更的,但是通过配置合理的预案可以在紧急的时候做一些修改。
核对
针对各种分布式系统产生的分布式事务一致性或者受到攻击导致的数据异常,非常需要核对平台来做最后的兜底的数据验证。比如下游支付系统和订单系统的金额做核对是否正确,如果收到中间人攻击落库的数据是否保证正确性。
总结其实可以看到,怎么设计高并发系统这个问题本身他是不难的,无非是基于你知道的知识点,从物理硬件层面到软件的架构、代码层面的优化,使用什么中间件来不断提高系统的抗压能力。但是这个问题本身会带来更多的问题,微服务本身的拆分带来了分布式事务的问题,http、RPC框架的使用带来了通信效率、路由、容错的问题,MQ的引入带来了消息丢失、积压、事务消息、顺序消息的问题,缓存的引入又会带来一致性、雪崩、击穿的问题,数据库的读写分离、分库分表又会带来主从同步延迟、分布式ID、事务一致性的问题,而为了解决这些问题我们又要不断的加入各种措施熔断、限流、降级、离线核对、预案处理等等来防止和追溯这些问题。
这篇文章结合了之前的文章的一些内容,实际上最开始的时候就是想写这一篇,发现篇幅实在太大了而且内容不好概括,所以就拆分了几篇开始写,这一篇算是对前面内容的一个归纳和总结吧,不是我为了水。
还有就是我的读者朋友们的群开通了,你也希望加入的话那就加我的个人微信,备注”入群“吧。

还有还有最后一件事情,帮朋友发一个阿里云的招聘信息,急招各路大牛,base北京。有兴趣的朋友也可以添加我的个人微信,备注”招聘“即可。
职位要求:
计算机相关专业本科及以上学历;
精通两种以上主流数据库和缓存技术,有丰富的数据库设计、优化、维护经验。或熟悉ELK、hadoop、spark、flink等大数据技术中的一种或多种。
精通JAVA、GO、Python等至少一门语言,5年以上的系统开发经验,熟悉微服务架构、基于容器和云原生技术,有丰富的实践和落地经验。
大型分布式系统架构设计经验,如:容灾高可用、业务容灾多活、两地三中心架构等,有项目落地经验者优先。
熟悉阿里云产品,通过阿里云ACP、PMP、TOGAF相关认证者优先考虑。
能够准确的理解客户需求,有从事过大型企业云化架构规划、设计和咨询的交付经验。
具备良好的客户沟通能力,工作积极主动,认真负责。