这个《我想进大厂》系列的最后一篇,终结篇。可能有点标题党了,但是我想要表达的意思和目的是一致的。
这是一道很常见的面试题,但是大多数人并不知道怎么回答,这种问题其实可以有很多形式的提问方式,你一定见过而且感觉无从下手:
面对业务急剧增长你怎么处理?
业务量增长10倍、100倍怎么处理?
你们系统怎么支撑高并发的?
怎么设计一个高并发系统?
高并发系统都有什么特点?
... ...
诸如此类,问法很多,但是面试这种类型的问题,看着很难无处下手,但是我们可以有一个常规的思路去回答,就是围绕支撑高并发的业务场景怎么设计系统才合理?如果你能想到这一点,那接下来我们就可以围绕硬件和软件层面怎么支撑高并发这个话题去阐述了。本质上,这个问题就是综合考验你对各个细节是否知道怎么处理,是否有经验处理过而已。
面对超高的并发,首先硬件层面机器要能扛得住,其次架构设计做好微服务的拆分,代码层面各种缓存、削峰、解耦等等问题要处理好,数据库层面做好读写分离、分库分表,稳定性方面要保证有监控,熔断限流降级该有的必须要有,发生问题能及时发现处理。这样从整个系统设计方面就会有一个初步的概念。
微服务架构演化在互联网早期的时候,单体架构就足以支撑起日常的业务需求,大家的所有业务服务都在一个项目里,部署在一台物理机器上。所有的业务包括你的交易系统、会员信息、库存、商品等等都夹杂在一起,当流量一旦起来之后,单体架构的问题就暴露出来了,机器挂了所有的业务全部无法使用了。

于是,集群架构的架构开始出现,单机无法抗住的压力,最简单的办法就是水平拓展横向扩容了,这样,通过负载均衡把压力流量分摊到不同的机器上,暂时是解决了单点导致服务不可用的问题。
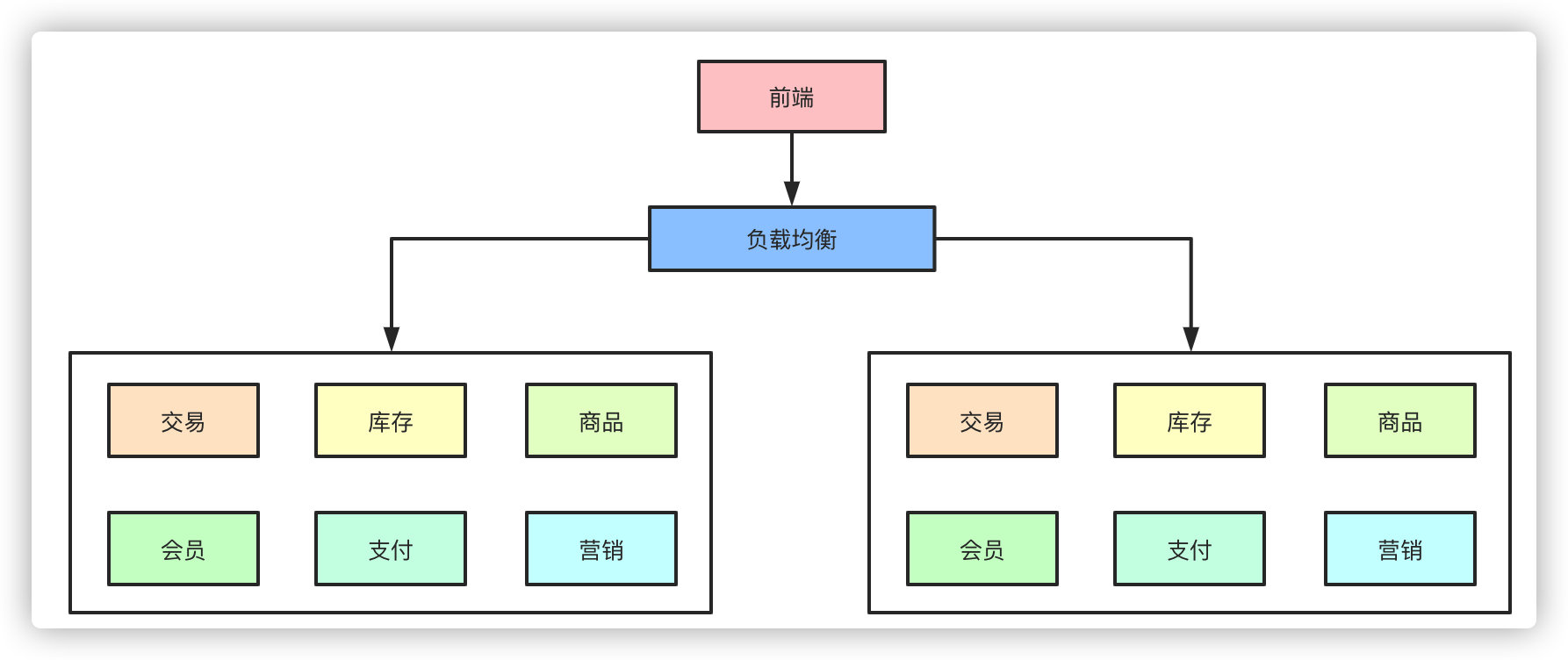
但是随着业务的发展,在一个项目里维护所有的业务场景使开发和代码维护变得越来越困难,一个简单的需求改动都需要发布整个服务,代码的合并冲突也会变得越来越频繁,同时线上故障出现的可能性越大。微服务的架构模式就诞生了。
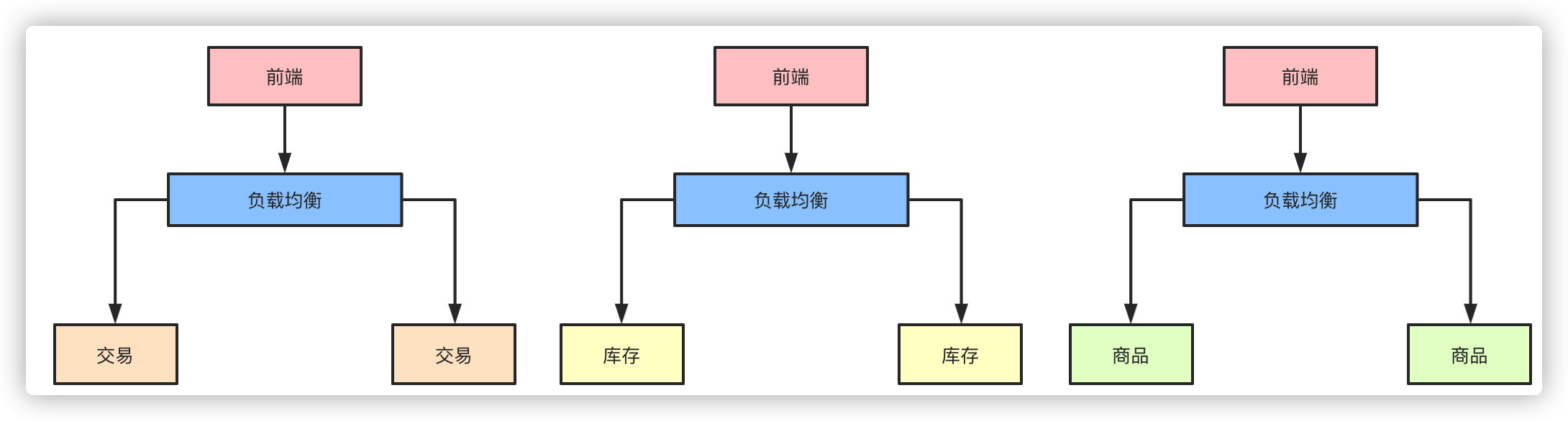
把每个独立的业务拆分开独立部署,开发和维护的成本降低,集群能承受的压力也提高了,再也不会出现一个小小的改动点需要牵一发而动全身了。
以上的点从高并发的角度而言,似乎都可以归类为通过服务拆分和集群物理机器的扩展提高了整体的系统抗压能力,那么,随之拆分而带来的问题也就是高并发系统需要解决的问题。
RPC微服务化的拆分带来的好处和便利性是显而易见的,但是与此同时各个微服务之间的通信就需要考虑了。传统HTTP的通信方式对性能是极大的浪费,这时候就需要引入诸如Dubbo类的RPC框架,基于TCP长连接的方式提高整个集群通信的效率。
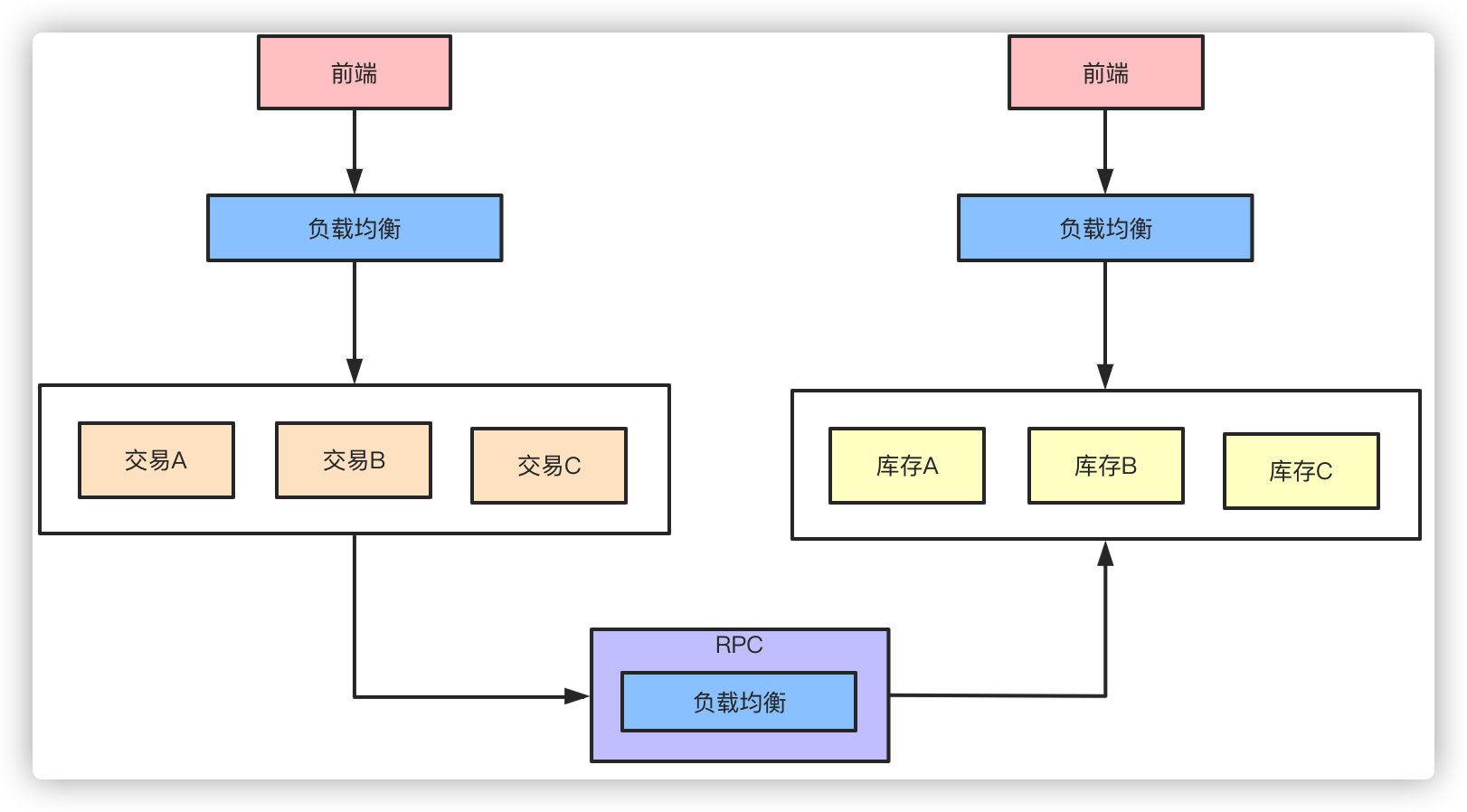
我们假设原来来自客户端的QPS是9000的话,那么通过负载均衡策略分散到每台机器就是3000,而HTTP改为RPC之后接口的耗时缩短了,单机和整体的QPS就提升了。而RPC框架本身一般都自带负载均衡、熔断降级的机制,可以更好的维护整个系统的高可用性。
那么说完RPC,作为基本上国内普遍的选择Dubbo的一些基本原理就是接下来的问题。
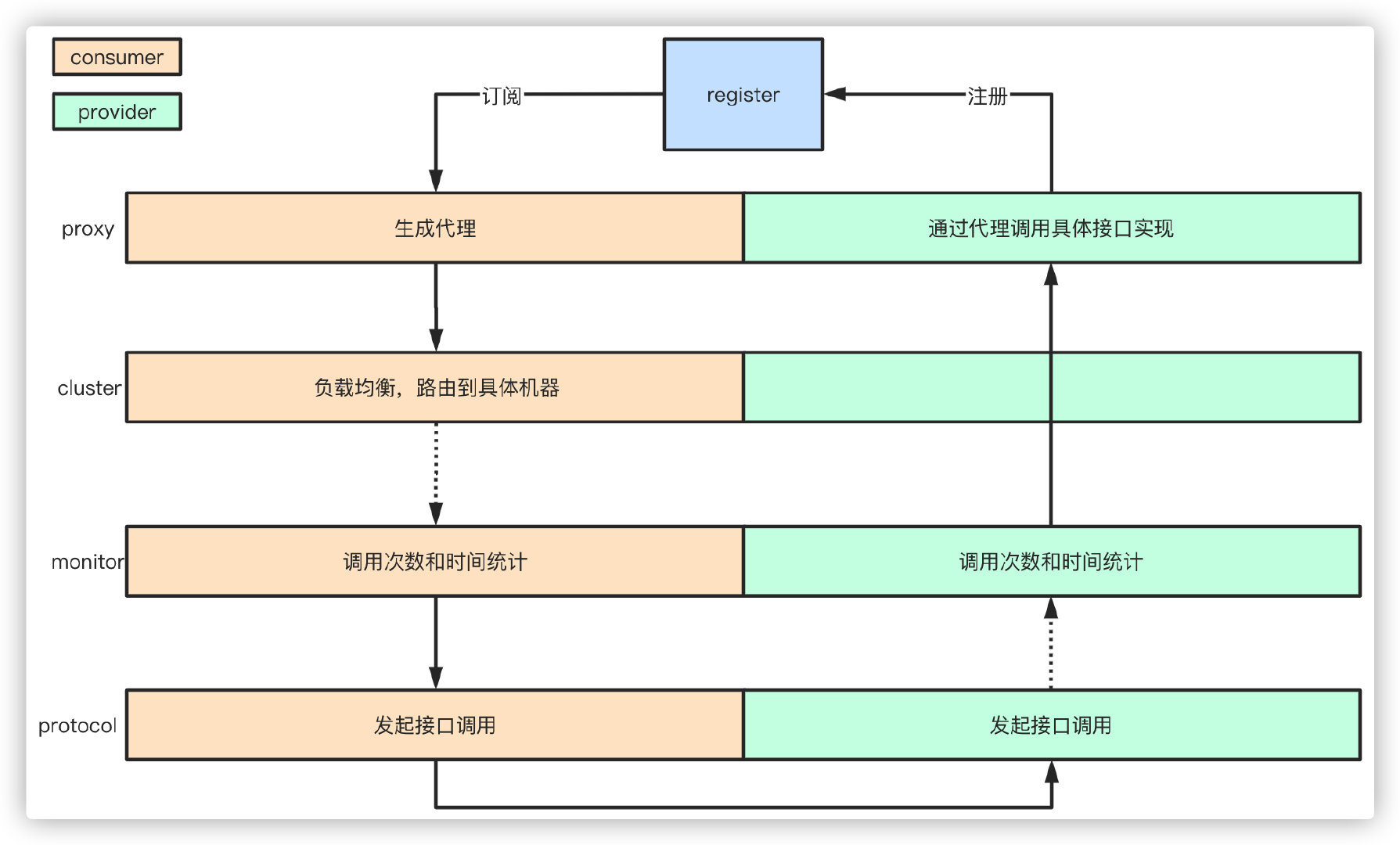
Dubbo工作原理
服务启动的时候,provider和consumer根据配置信息,连接到注册中心register,分别向注册中心注册和订阅服务
register根据服务订阅关系,返回provider信息到consumer,同时consumer会把provider信息缓存到本地。如果信息有变更,consumer会收到来自register的推送
consumer生成代理对象,同时根据负载均衡策略,选择一台provider,同时定时向monitor记录接口的调用次数和时间信息
拿到代理对象之后,consumer通过代理对象发起接口调用
provider收到请求后对数据进行反序列化,然后通过代理调用具体的接口实现