
分表后不使用主键作为查询依据,而是每张表单独新增一个字段作为唯一主键使用,比如订单表订单号是唯一的,不管最终落在哪张表都基于订单号作为查询依据,更新也一样。
主从同步原理master提交完事务后,写入binlog
slave连接到master,获取binlog
master创建dump线程,推送binglog到slave
slave启动一个IO线程读取同步过来的master的binlog,记录到relay log中继日志中
slave再开启一个sql线程读取relay log事件并在slave执行,完成同步
slave记录自己的binglog
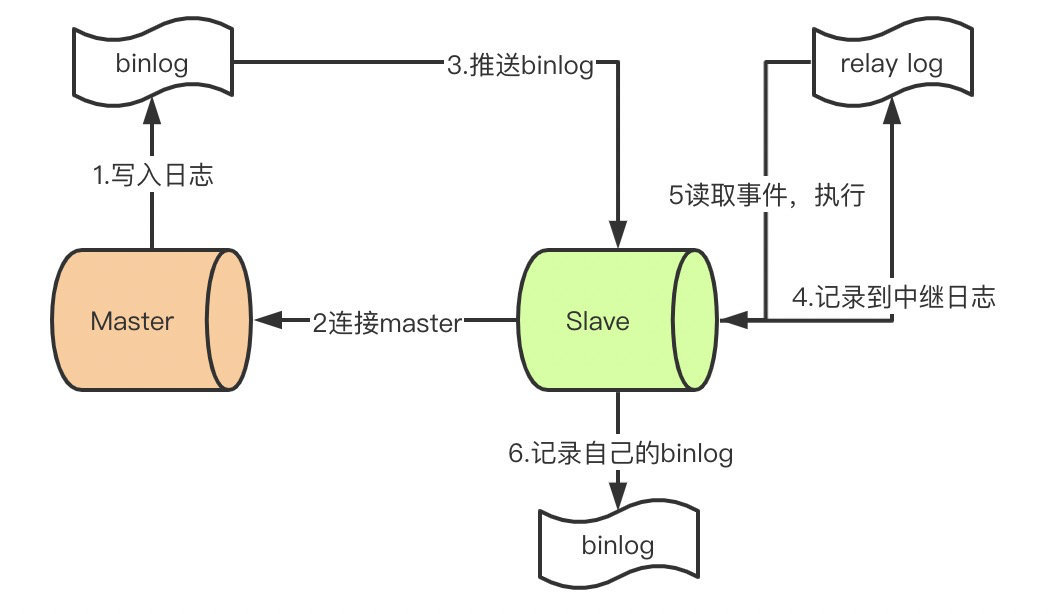
由于mysql默认的复制方式是异步的,主库把日志发送给从库后不关心从库是否已经处理,这样会产生一个问题就是假设主库挂了,从库处理失败了,这时候从库升为主库后,日志就丢失了。由此产生两个概念。
全同步复制
主库写入binlog后强制同步日志到从库,所有的从库都执行完成后才返回给客户端,但是很显然这个方式的话性能会受到严重影响。
半同步复制
和全同步不同的是,半同步复制的逻辑是这样,从库写入日志成功后返回ACK确认给主库,主库收到至少一个从库的确认就认为写操作完成。
缓存缓存作为高性能的代表,在某些特殊业务可能承担90%以上的热点流量。对于一些活动比如秒杀这种并发QPS可能几十万的场景,引入缓存事先预热可以大幅降低对数据库的压力,10万的QPS对于单机的数据库来说可能就挂了,但是对于如redis这样的缓存来说就完全不是问题。
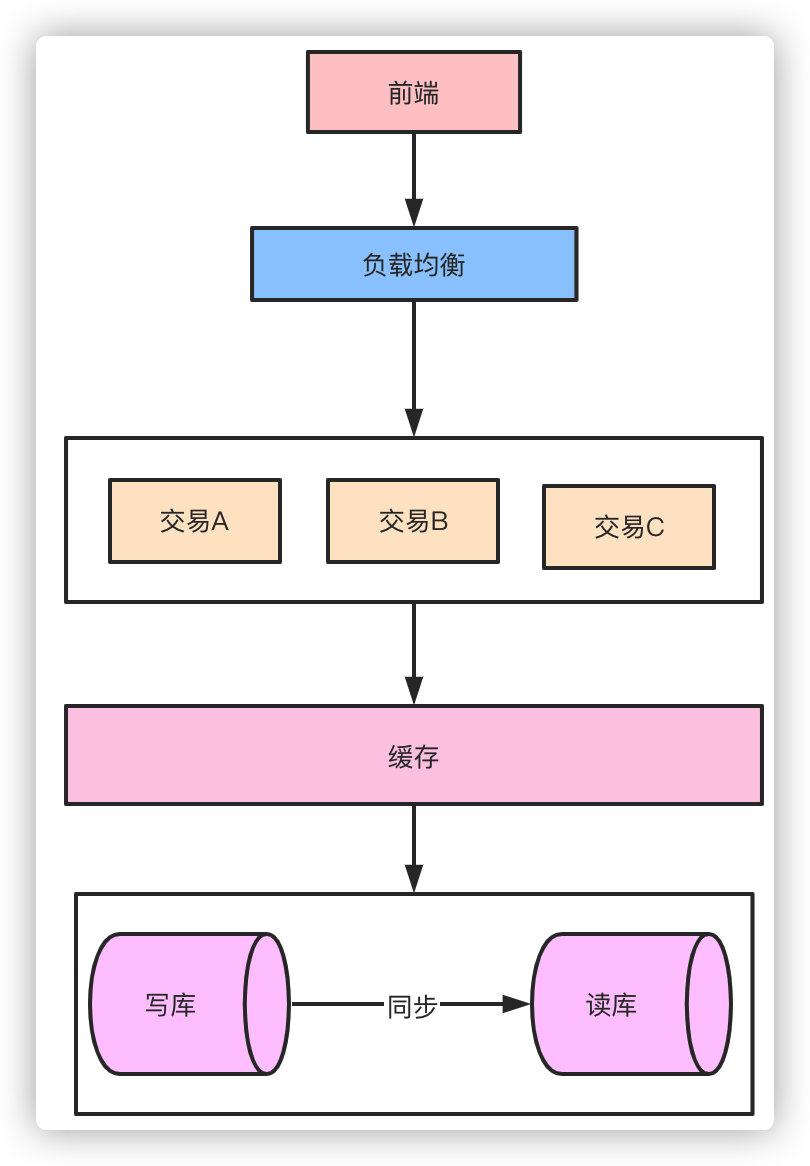
以秒杀系统举例,活动预热商品信息可以提前缓存提供查询服务,活动库存数据可以提前缓存,下单流程可以完全走缓存扣减,秒杀结束后再异步写入数据库,数据库承担的压力就小的太多了。当然,引入缓存之后就还要考虑缓存击穿、雪崩、热点一系列的问题了。
热key问题所谓热key问题就是,突然有几十万的请求去访问redis上的某个特定key,那么这样会造成流量过于集中,达到物理网卡上限,从而导致这台redis的服务器宕机引发雪崩。
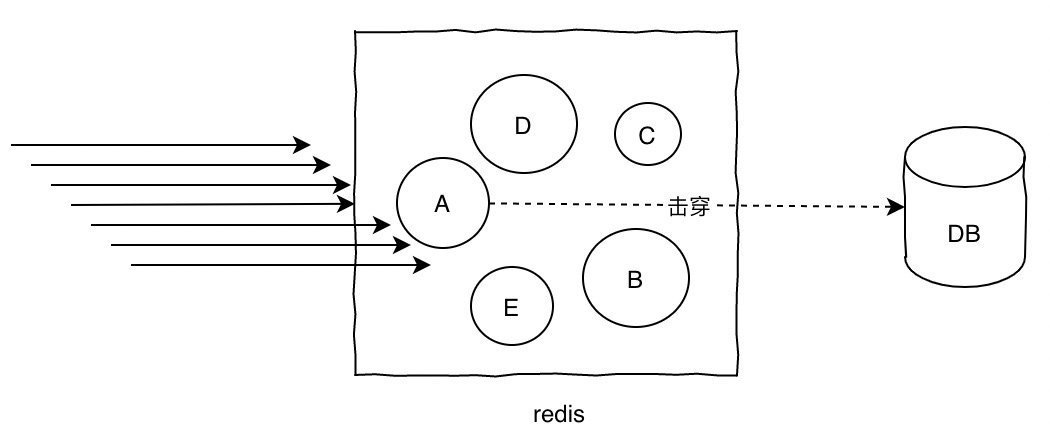
针对热key的解决方案:
提前把热key打散到不同的服务器,降低压力
加入二级缓存,提前加载热key数据到内存中,如果redis宕机,走内存查询
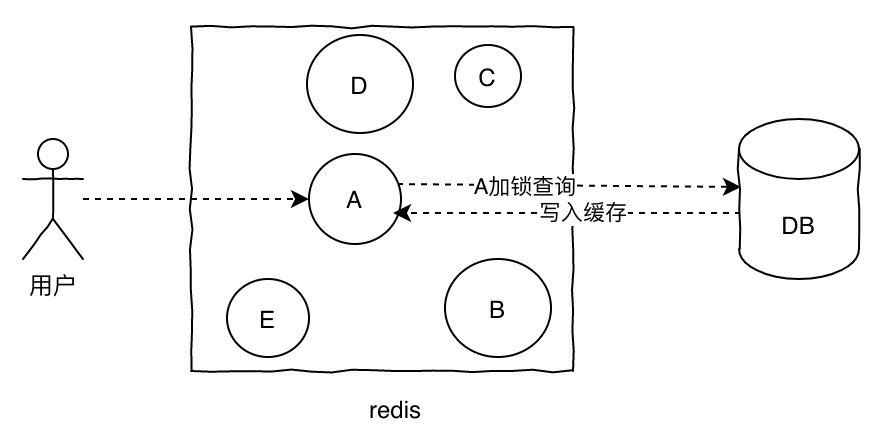
缓存击穿缓存击穿的概念就是单个key并发访问过高,过期时导致所有请求直接打到db上,这个和热key的问题比较类似,只是说的点在于过期导致请求全部打到DB上而已。
解决方案:
加锁更新,比如请求查询A,发现缓存中没有,对A这个key加锁,同时去数据库查询数据,写入缓存,再返回给用户,这样后面的请求就可以从缓存中拿到数据了。
将过期时间组合写在value中,通过异步的方式不断的刷新过期时间,防止此类现象。
缓存穿透是指查询不存在缓存中的数据,每次请求都会打到DB,就像缓存不存在一样。