
QA机器人的本质是:假设用户提了一个问题Q,QA机器人需要从已有的QA数据库中寻找最合适的QA对返回,QA机器人会进行QQ相似度计算和QA匹配度计算,通过综合相似度与匹配度,找到最适合的一组QA对 (Qi, Ai),即最佳答案返回。
解决方案1:NN模型常见的网络模型包括RNN和CNN模型。例如双层编码(Decoder)的长短期记忆模型(LSTM)。这种模型在很多场景下都比较好用,网络模型的主要缺点是需要一定数量的样本。
解决方案2:拆分成子问题。在语料比较小的情况下,将问题进行拆分,分为两个阶段:
把问题变成一种短文本语义表征,通常有tfidf、w2v。
然后再进行语义距离计算,例如计算向量的余弦距离。
它的优点是在语料比较小的情况下效果不错。
3.4 QA机器人原理(QQ匹配)
这里以QQ匹配来介绍QA机器人原理。
QQ匹配包括几个部分:句向量化、相似度计算、相似度排序。
句向量化是使用BoW词袋模型和同义词扩展,将句子的词转换成向量;
然后再与问题库里的词进行相似度计算,计算出余弦相似度;
用余弦距离产生相应的结果,按照相似度大小排序返回答案列表。

句向量我们是通过词袋模型和同义词扩展来表示的。
什么是词袋模型?词袋模型就是忽略文本里的词序、词法、句法,只将它看做一个词的集合,把它当成一个词袋。
还引入了同义词扩展。在实际的问题中,不同的词可能存在不同的问法,但其语义相同,所以进行一些同义词等价,这样就形成了词向量。向量的值是TF-IDF值,用于表示权重。
TF-IDF模型(term frequency–inverse document frequency,词频与逆向文件频率)。TF-IDF是一种统计方法,用以评估某一字词对于一个文件集或一个语料库的重要程度。TF-IDF的主要思想是,如果某个词或短语在一篇文章中出现的词频高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF有两个值,一个是词频率,另一个是IDF(inverse document frequency,逆向文件频率)。如图中的计算方式。
举个例子,库中10000篇文档,10000篇提到“母牛”,其中10篇提到“产奶量”,比如一篇关于“母牛的产奶量”的文字,这篇文章有100个词,“母牛”出现5次,“产奶量”出现2次)。
通过计算发现,虽然“母牛”的词频率很高,但IDF值很低,最后“母牛”的TF-IDF很低,也就是说这个词不具太大的标识度。而“产奶量”这个词的词频率不高,但它的辨识度很高,最终它的TF-IDF也很高。
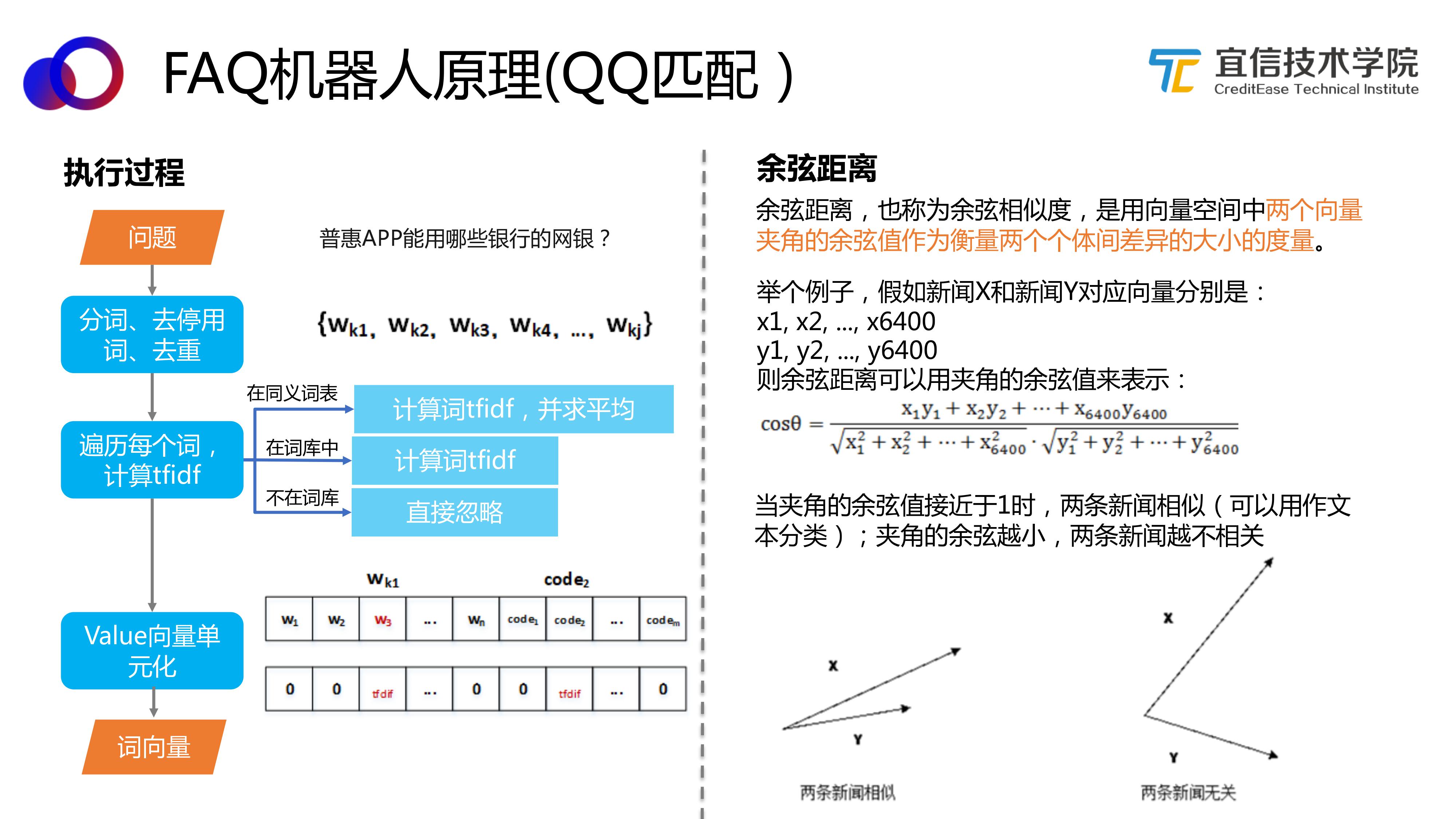
具体执行过程如图所示,首先拿到一个语句,进行分词、去停用词、去重,得到一个词序列。然后遍历每一个词进行TF-IDF计算,如果在同义词表里,就计算词TF-IDF并求平均值;如果在词库中,就计算TF-IDF值;如果不在词库中,就直接忽略,最后形成词对应的TF-IDF值,并将Value向量单元化。
接下来我们要计算向量和向量之间的距离,这里我们采用余弦距离。计算方式如图所示。
当两个词向量的余弦值接近1的时候,两个词向量相似,也就是两个句子相关。否则就不相关。通过计算余弦值来最终达到判断句子的相似度。

上文介绍的QQ匹配是属于一种基于检索的聊天机器人,另一种对应的分类是基于模型生成的表情机器人。
基于检索的聊天机器人:
特点是回复数据是预先存储且知道(或定义)的数据。
优点是问题与答案都经过人工总结,保证了数据库中的答案正确性,表述自然、易于理解。
缺点是用户提问的各种问题,机器人都试图在库上寻找答案;问题数有限,无法覆盖用户的所有问题;需要不断总结、扩展,争取覆盖大多数问题。
生成模型的聊天机器人:
特点是创造出崭新的、未知的回复内容(模型没有见过),类似机器翻译技术。
优点是不需要预先存储且定义好的数据,比起检索模型更加的灵活多变。
缺点是生成效果不佳,生成的答案可能有一些语法错误和语义无关的内容;生成式模型需要海量的训练数据,且难以优化;结果无法控制。